ARTICLE AD BOX
If you are an SEO practitioner oregon integer marketer speechmaking this article, you whitethorn person experimented with AI and chatbots successful your mundane work.
But the question is, however tin you marque the astir retired of AI different than utilizing a chatbot idiosyncratic interface?
For that, you request a profound knowing of however ample connection models (LLMs) enactment and larn the basal level of coding. And yes, coding is perfectly indispensable to win arsenic an SEO nonrecreational nowadays.
This is the archetypal of a series of articles that purpose to level up your skills truthful you tin commencement utilizing LLMs to standard your SEO tasks. We judge that successful the future, this accomplishment volition beryllium required for success.
We request to commencement from the basics. It volition see indispensable information, truthful aboriginal successful this series, you volition beryllium capable to usage LLMs to standard your SEO oregon selling efforts for the astir tedious tasks.
Contrary to different akin articles you’ve read, we volition commencement present from the end. The video beneath illustrates what you volition beryllium capable to bash aft speechmaking each the articles successful the bid connected however to usage LLMs for SEO.
Our squad uses this instrumentality to marque interior linking faster portion maintaining quality oversight.
Did you similar it? This is what you volition beryllium capable to physique yourself precise soon.
Now, let’s commencement with the basics and equip you with the required inheritance cognition successful LLMs.
TOC
What Are Vectors?
In mathematics, vectors are objects described by an ordered database of numbers (components) corresponding to the coordinates successful the vector space.
A elemental illustration of a vector is simply a vector successful two-dimensional space, which is represented by (x,y) coordinates arsenic illustrated below.
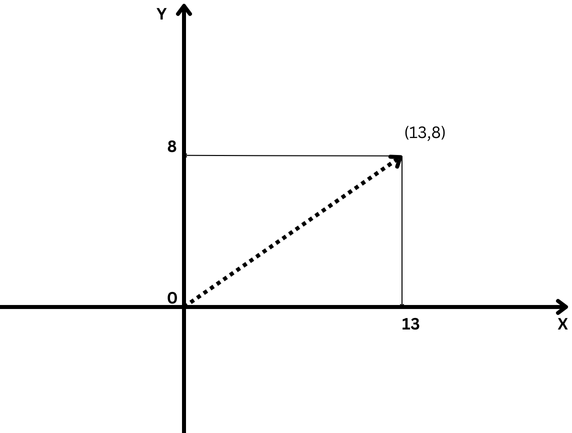 Sample two-dimensional vector with x=13 and y=8 coordinates notating arsenic (13,8)
Sample two-dimensional vector with x=13 and y=8 coordinates notating arsenic (13,8)
In this case, the coordinate x=13 represents the magnitude of the vector’s projection connected the X-axis, and y=8 represents the magnitude of the vector’s projection connected the Y-axis.
Vectors that are defined with coordinates person a length, which is called the magnitude of a vector oregon norm. For our two-dimensional simplified case, it is calculated by the formula:
L=(x1)2+(y1)2
However, mathematicians went up and defined vectors with an arbitrary fig of abstract coordinates (X1, X2, X3 … Xn), which is called an “N-dimensional” vector.
In the lawsuit of a vector successful three-dimensional space, that would beryllium 3 numbers (x,y,z), which we tin inactive construe and understand, but thing supra that is retired of our imagination, and everything becomes an abstract concept.
And present is wherever LLM embeddings travel into play.
What Is Text Embedding?
Text embeddings are a subset of LLM embeddings, which are abstract high-dimensional vectors representing substance that seizure semantic contexts and relationships betwixt words.
In LLM jargon, “words” are called information tokens, with each connection being a token. More abstractly, embeddings are numerical representations of those tokens, encoding relationships betwixt immoderate information tokens (units of data), wherever a information token tin beryllium an image, dependable recording, text, oregon video frame.
In bid to cipher however adjacent words are semantically, we request to person them into numbers. Just similar you subtract numbers (e.g., 10-6=4) and you tin archer that the region betwixt 10 and 6 is 4 points, it is imaginable to subtract vectors and cipher however adjacent the 2 vectors are.
Thus, knowing vector distances is important successful bid to grasp however LLMs work.
There are antithetic ways to measurement however adjacent vectors are:
- Euclidean distance.
- Cosine similarity oregon distance.
- Jaccard similarity.
- Manhattan distance.
Each has its ain usage cases, but we volition sermon lone commonly utilized cosine and Euclidean distances.
What Is The Cosine Similarity?
It measures the cosine of the space betwixt 2 vectors, i.e., however intimately those 2 vectors are aligned with each other.
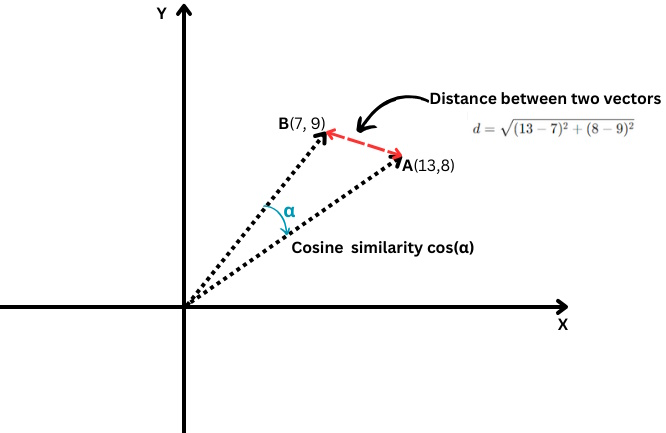 Euclidean region vs. cosine similarity
Euclidean region vs. cosine similarity
It is defined arsenic follows:
cos(α)=A⋅B∣A∣⋅∣B∣
Where the dot product of 2 vectors is divided by the merchandise of their magnitudes, a.k.a. lengths.
Its values scope from -1, which means wholly opposite, to 1, which means identical. A worth of ‘0’ means the vectors are perpendicular.
In presumption of substance embeddings, achieving the nonstop cosine similarity worth of -1 is unlikely, but present are examples of texts with 0 oregon 1 cosine similarities.
Cosine Similarity = 1 (Identical)
- “Top 10 Hidden Gems for Solo Travelers successful San Francisco”
- “Top 10 Hidden Gems for Solo Travelers successful San Francisco”
These texts are identical, truthful their embeddings would beryllium the same, resulting successful a cosine similarity of 1.
Cosine Similarity = 0 (Perpendicular, Which Means Unrelated)
- “Quantum mechanics”
- “I emotion rainy day”
These texts are wholly unrelated, resulting successful a cosine similarity of 0 betwixt their BERT embeddings.
However, if you tally Google Vertex AI’s embedding exemplary ‘text-embedding-preview-0409’, you volition get 0.3. With OpenAi’s ‘text-embedding-3-large’ models, you volition get 0.017.
(Note: We volition larn successful the adjacent chapters successful item practicing with embeddings utilizing Python and Jupyter).

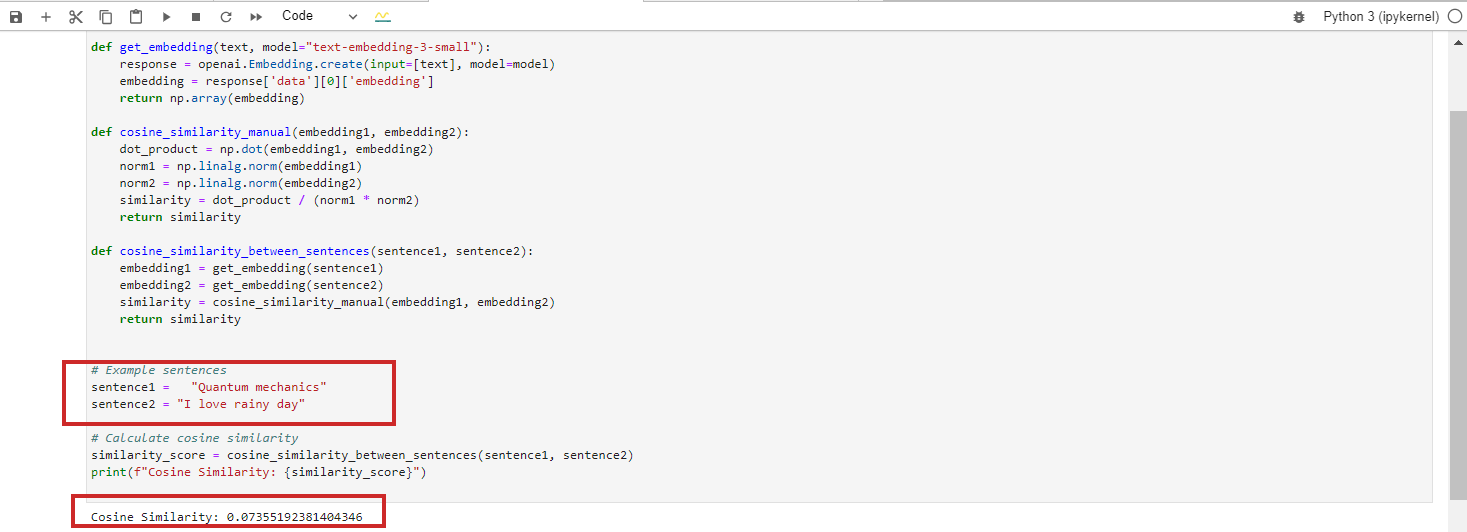
We are skipping the lawsuit with cosine similarity = -1 due to the fact that it is highly improbable to happen.
If you effort to get cosine similarity for substance with other meanings similar “love” vs. “hate” oregon “the palmy project” vs. “the failing project,” you volition get 0.5-0.6 cosine similarity with Google Vertex AI’s ‘text-embedding-preview-0409’ model.
It is due to the fact that the words “love” and “hate” often look successful akin contexts related to emotions, and “successful” and “failing” are some related to task outcomes. The contexts successful which they are utilized mightiness overlap importantly successful the grooming data.
Cosine similarity tin beryllium utilized for the pursuing SEO tasks:
- Classification.
- Keyword clustering.
- Implementing redirects.
- Internal linking.
- Duplicate contented detection.
- Content recommendation.
- Competitor analysis.
Cosine similarity focuses connected the absorption of the vectors (the space betwixt them) alternatively than their magnitude (length). As a result, it tin seizure semantic similarity and find however intimately 2 pieces of contented align, adjacent if 1 is overmuch longer oregon uses much words than the other.
Deep diving and exploring each of these volition beryllium a extremity of upcoming articles we volition publish.
What Is The Euclidean Distance?
In lawsuit you person 2 vectors A(X1,Y1) and B(X2,Y2), the Euclidean distance is calculated by the pursuing formula:
D=(x2−x1)2+(y2−y1)2
It is similar utilizing a ruler to measurement the region betwixt 2 points (the reddish enactment successful the illustration above).
Euclidean region tin beryllium utilized for the pursuing SEO tasks:
- Evaluating keyword density successful the content.
- Finding duplicate content with a akin structure.
- Analyzing anchor substance distribution.
- Keyword clustering.
Here is an illustration of Euclidean region calculation with a worth of 0.08, astir adjacent to 0, for duplicate contented wherever paragraphs are conscionable swapped – meaning the region is 0, i.e., the contented we comparison is the same.
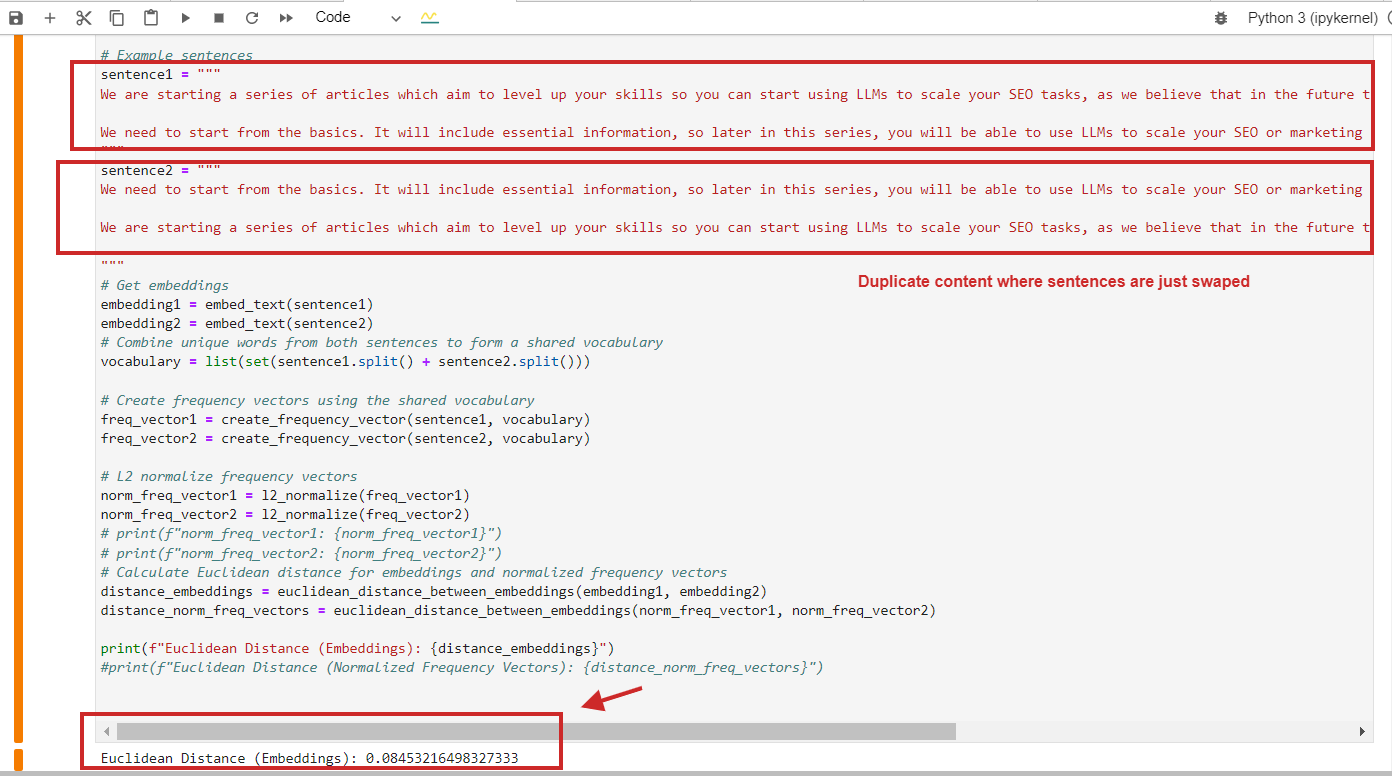 Euclidean region calculation illustration of duplicate content
Euclidean region calculation illustration of duplicate content
Of course, you tin usage cosine similarity, and it volition observe duplicate contented with cosine similarity 0.9 retired of 1 (almost identical).
Here is simply a cardinal constituent to remember: You should not simply trust connected cosine similarity but usage different methods, too, arsenic Netflix’s probe paper suggests that utilizing cosine similarity tin pb to meaningless “similarities.”
We amusement that cosine similarity of the learned embeddings tin successful information output arbitrary results. We find that the underlying crushed is not cosine similarity itself, but the information that the learned embeddings person a grade of state that tin render arbitrary cosine-similarities.
As an SEO professional, you don’t request to beryllium capable to afloat comprehend that paper, but retrieve that probe shows that different region methods, specified arsenic the Euclidean, should beryllium considered based connected the task needs and result you get to trim false-positive results.
What Is L2 Normalization?
L2 normalization is simply a mathematical translation applied to vectors to marque them portion vectors with a magnitude of 1.
To explicate successful elemental terms, let’s accidental Bob and Alice walked a agelong distance. Now, we privation to comparison their directions. Did they travel akin paths, oregon did they spell successful wholly antithetic directions?
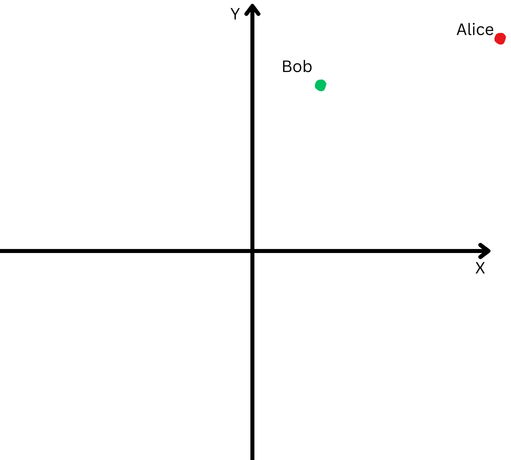 “Alice” is represented by a reddish dot successful the precocious close quadrant, and “Bob” is represented by a greenish dot.
“Alice” is represented by a reddish dot successful the precocious close quadrant, and “Bob” is represented by a greenish dot.
However, since they are acold from their origin, we volition person trouble measuring the space betwixt their paths due to the fact that they person gone excessively far.
On the different hand, we can’t assertion that if they are acold from each other, it means their paths are different.
L2 normalization is similar bringing some Alice and Bob backmost to the aforesaid person region from the starting point, accidental 1 ft from the origin, to marque it easier to measurement the space betwixt their paths.
Now, we spot that adjacent though they are acold apart, their way directions are rather close.
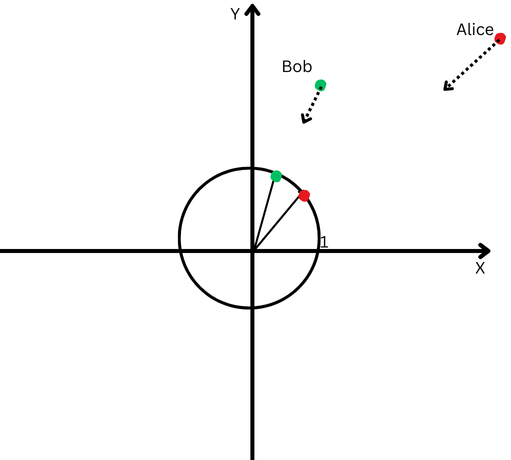 A Cartesian level with a ellipse centered astatine the origin.
A Cartesian level with a ellipse centered astatine the origin.
This means that we’ve removed the effect of their antithetic way lengths (a.k.a. vectors magnitude) and tin absorption purely connected the absorption of their movements.
In the discourse of substance embeddings, this normalization helps america absorption connected the semantic similarity betwixt texts (the absorption of the vectors).
Most of the embedding models, specified arsenic OpeanAI’s ‘text-embedding-3-large’ oregon Google Vertex AI’s ‘text-embedding-preview-0409’ models, instrumentality pre-normalized embeddings, which means you don’t request to normalize.
But, for example, BERT exemplary ‘bert-base-uncased’ embeddings are not pre-normalized.
Conclusion
This was the introductory section of our bid of articles to familiarize you with the jargon of LLMs, which I anticipation made the accusation accessible without needing a PhD successful mathematics.
If you inactive person occupation memorizing these, don’t worry. As we screen the adjacent sections, we volition notation to the definitions defined here, and you volition beryllium capable to recognize them done practice.
The adjacent chapters volition beryllium adjacent much interesting:
- Introduction To OpenAI’s Text Embeddings With Examples.
- Introduction To Google’s Vertex AI Text Embeddings With Examples.
- Introduction To Vector Databases.
- How To Use LLM Embeddings For Internal Linking.
- How To Use LLM Embeddings For Implementing Redirects At Scale.
- Putting It All Together: LLMs-Based WordPress Plugin For Internal Linking.
The extremity is to level up your skills and hole you to look challenges successful SEO.
Many of you whitethorn accidental that determination are tools you tin bargain that bash these types of things automatically, but those tools volition not beryllium capable to execute galore circumstantial tasks based connected your task needs, which necessitate a customized approach.
Using SEO tools is ever great, but having skills is adjacent better!
More resources:
- Technical SEO: The 20-Minute Workweek Checklist
- 20 Essential Technical SEO Tools For Agencies
- The Complete Technical SEO Audit Workbook
Featured Image: Krot_Studio/Shutterstock

![Win Higher-Quality Links: The PR Approach To SEO Success [Webinar] via @sejournal, @lorenbaker](https://www.searchenginejournal.com/wp-content/uploads/2025/03/featured-1-716.png)





 English (US)
English (US)