ARTICLE AD BOX
What Is a Robots.txt File?
A robots.txt record is simply a acceptable of instructions telling hunt engines which pages should and shouldn’t beryllium crawled connected a website. Which guides crawler entree but shouldn’t beryllium utilized to support pages retired of Google's index.
A robots.txt record looks similar this:
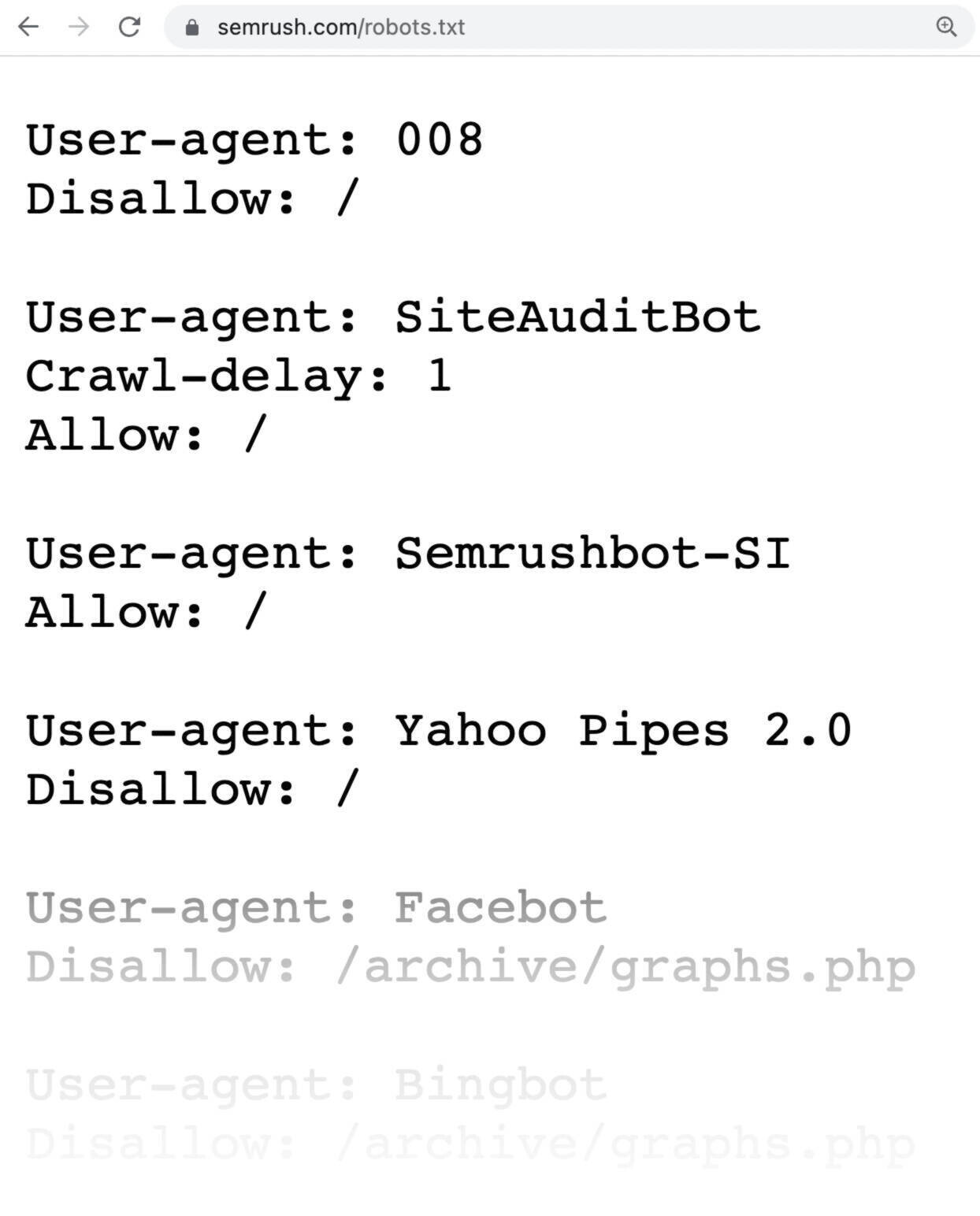
Robots.txt files mightiness look complicated, but the syntax (computer language) is straightforward.
Before we get into those details, let’s connection immoderate clarification connected however robots.txt differs from immoderate presumption that dependable similar.
Robots.txt files, meta robots tags, and x-robots tags each usher hunt engines astir however to grip your site’s content.
But they disagree successful their level of control, wherever they’re located, and what they control.
Here are the specifics:
- Robots.txt: This record is located successful your website's basal directory and acts arsenic a gatekeeper to supply general, site-wide instructions to hunt motor crawlers connected which areas of your tract they should and shouldn’t crawl
- Meta robots tags: These are snippets of codification that reside wrong the <head> conception of idiosyncratic webpages. And supply page-specific instructions to hunt engines connected whether to scale (include successful hunt results) and travel (crawl links within) each page.
- X-robot tags: These are codification snippets that are chiefly utilized for non-HTML files similar PDFs and images. And are implemented successful the file's HTTP header.
Further reading: Meta Robots Tag & X-Robots-Tag Explained
Why Is Robots.txt Important for SEO?
A robots.txt record helps negociate web crawler activities, truthful they don’t overwork your website oregon fuss with pages not meant for nationalist view.
Below are a fewer reasons to usage a robots.txt file:
1. Optimize Crawl Budget
Crawl fund refers to the fig of pages Google volition crawl connected your tract wrong a fixed clip frame.
The fig tin alteration based connected your site’s size, health, and fig of backlinks.
If your website’s fig of pages exceeds your site’s crawl budget, you could person important pages that neglect to get indexed.
Those unindexed pages won’t rank. Meaning you wasted clip creating pages users won’t see.
Blocking unnecessary pages with robots.txt allows Googlebot (Google’s web crawler) to walk much crawl fund connected pages that matter.
2. Block Duplicate and Non-Public Pages
Crawl bots don’t request to sift done each leafage connected your site. Because not each of them were created to beryllium served successful the hunt motor results pages (SERPs).
Like staging sites, interior hunt results pages, duplicate pages, oregon login pages. Some contented absorption systems grip these interior pages for you.
WordPress, for example, automatically disallows the login leafage “/wp-admin/” for each crawlers.
Robots.txt allows you to artifact these pages from crawlers.
3. Hide Resources
Sometimes, you privation to exclude resources specified arsenic PDFs, videos, and images from hunt results.
To support them backstage oregon person Google absorption connected much important content.
In either case, robots.txt keeps them from being crawled.
How Does a Robots.txt File Work?
Robots.txt files archer hunt motor bots which URLs they should crawl and (more importantly) which ones to ignore.
As they crawl webpages, hunt motor bots observe and travel links. This process takes them from tract A to tract B to tract C crossed links, pages, and websites.
But if a bot finds a robots.txt file, it volition work it earlier doing thing else.
The syntax is straightforward.
You delegate rules by identifying the “user-agent” (search motor bot) and specifying the directives (rules).
You tin besides usage an asterisk (*) to delegate directives to each user-agent, which applies the regularisation for each bots.
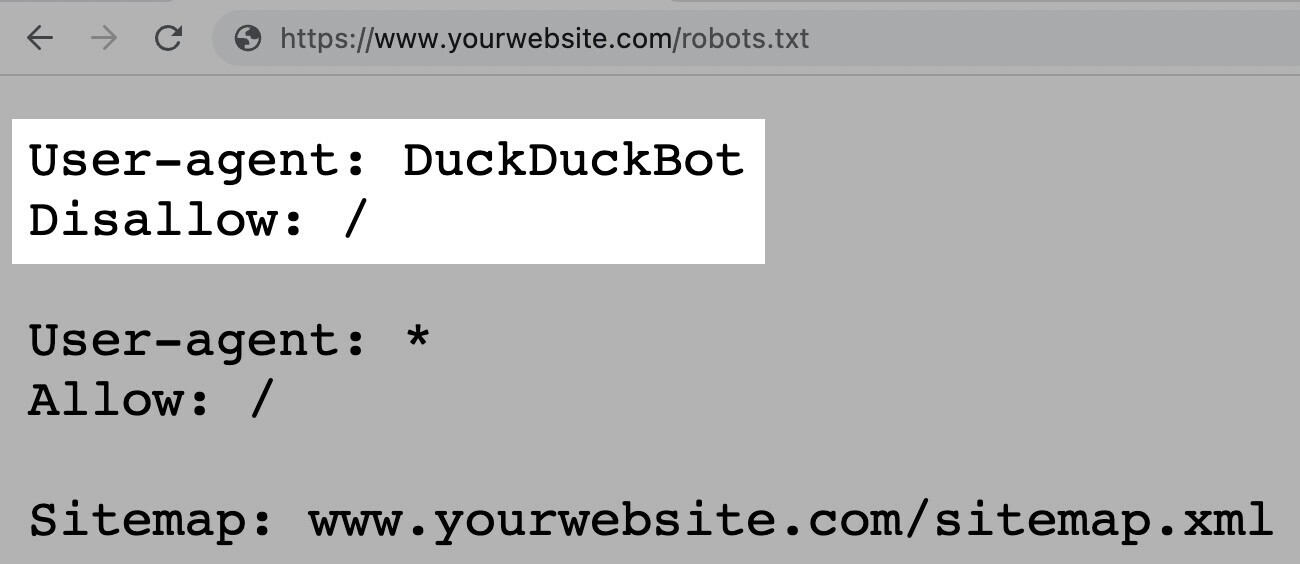
For example, the beneath acquisition allows each bots but DuckDuckGo to crawl your site:
Semrush bots crawl the web to stitchery insights for our website optimization tools, specified arsenic Site Audit, Backlink Audit, and On Page SEO Checker.
Our bots respect the rules outlined successful your robots.txt file. So, if you artifact our bots from crawling your website, they won’t.
But doing that besides means you can’t usage immoderate of our tools to their afloat potential.
For example, if you blocked our SiteAuditBot from crawling your website, you couldn’t audit your tract with our Site Audit tool. To analyse and hole method issues connected your site.
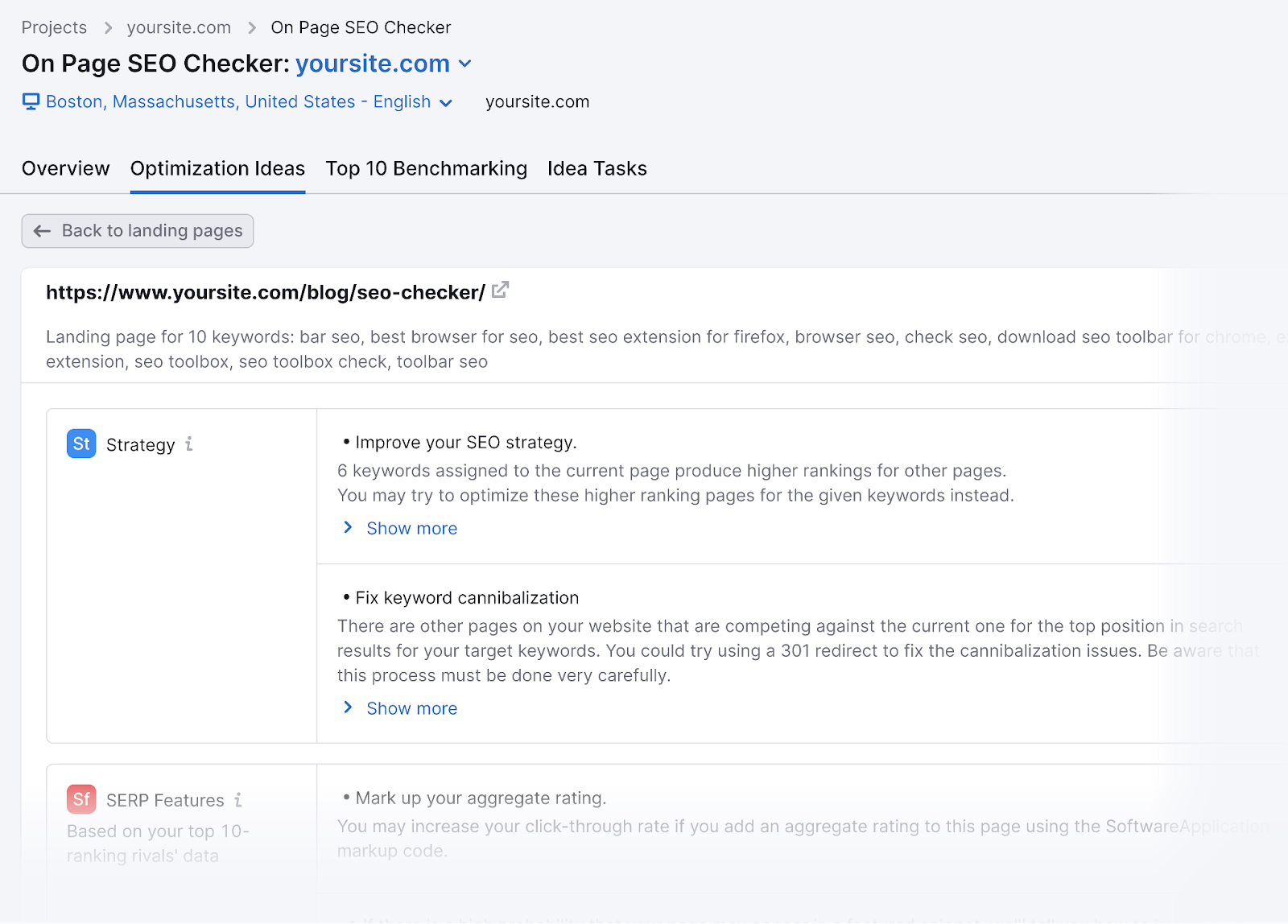
If you blocked our SemrushBot-SI from crawling your site, you couldn’t usage the On Page SEO Checker instrumentality effectively.
And you’d suffer retired connected generating optimization ideas to amended your webpages’ rankings.
How to Find a Robots.txt File
Your robots.txt record is hosted connected your server, conscionable similar immoderate different record connected your website.
You tin presumption the robots.txt record for immoderate fixed website by typing the afloat URL for the homepage and adding “/robots.txt” astatine the end.
Like this: “https://semrush.com/robots.txt.”
Before learning however to make a robots.txt record oregon going into the syntax, let’s archetypal look astatine immoderate examples.
Examples of Robots.txt Files
Here are immoderate real-world robots.txt examples from fashionable websites.
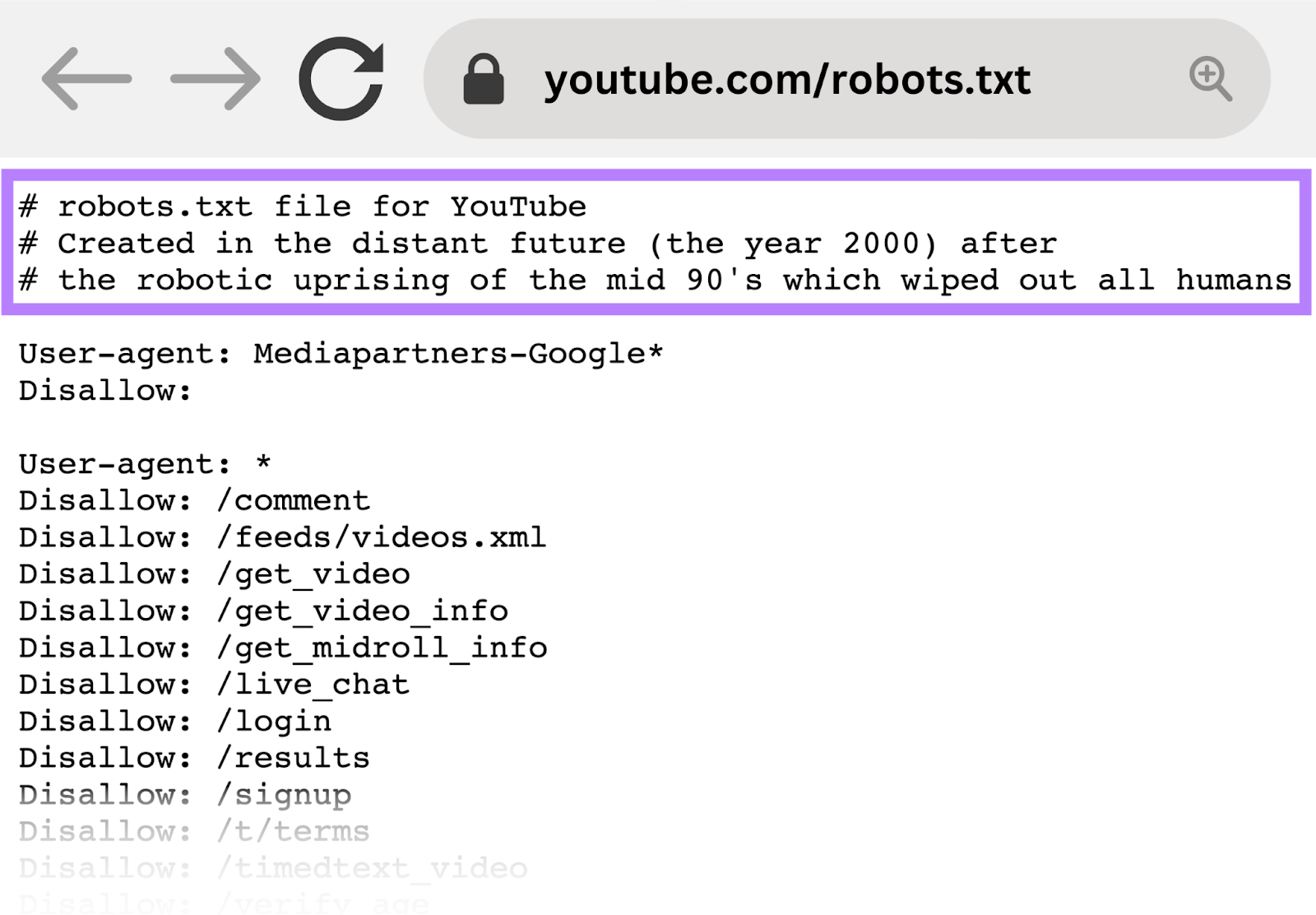
YouTube
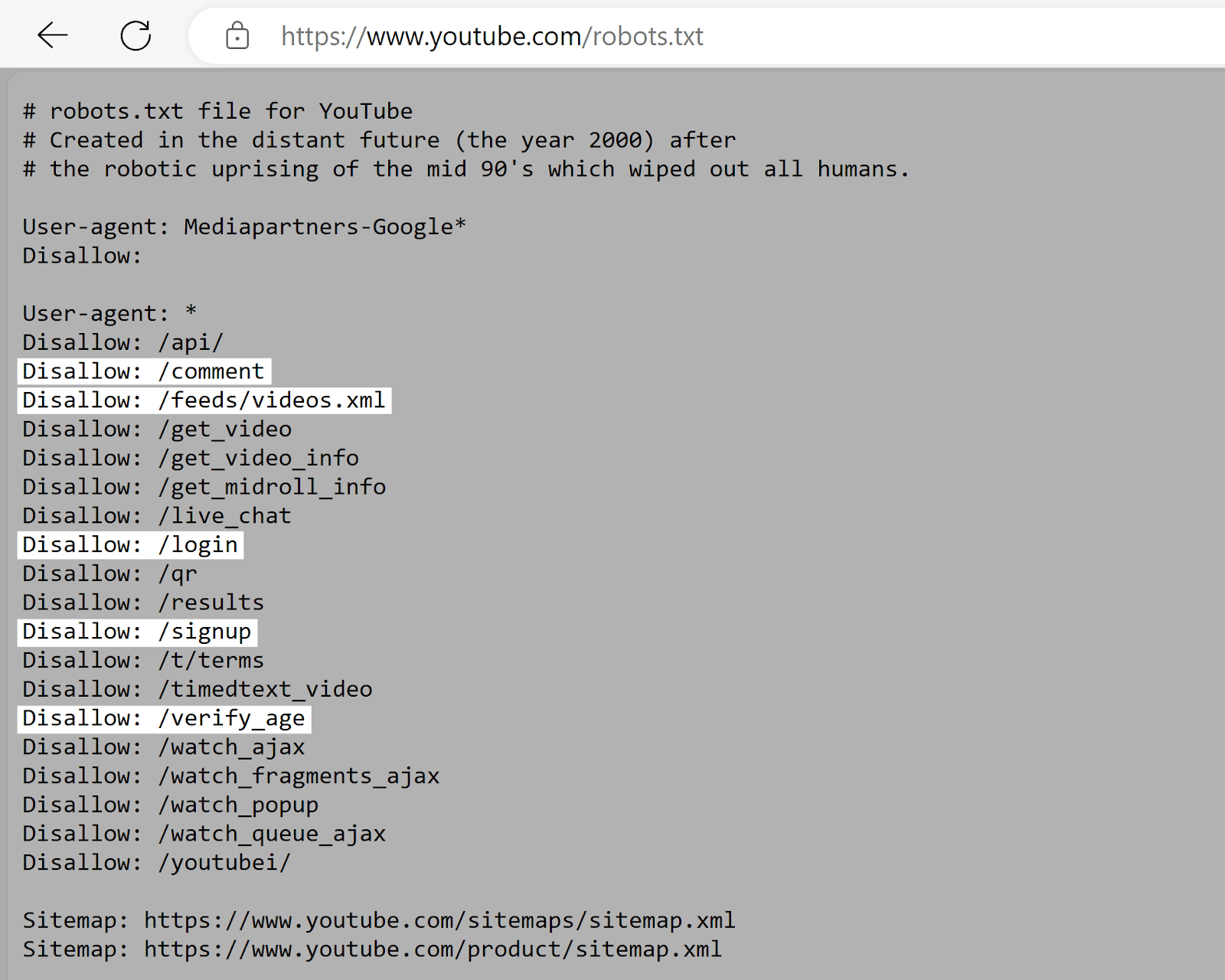
YouTube’s robots.txt record tells crawlers not to entree idiosyncratic comments, video feeds, login/signup pages, and property verification pages.
This discourages the indexing of user-specific oregon dynamic content that’s often irrelevant to hunt results and whitethorn rise privateness concerns.
G2
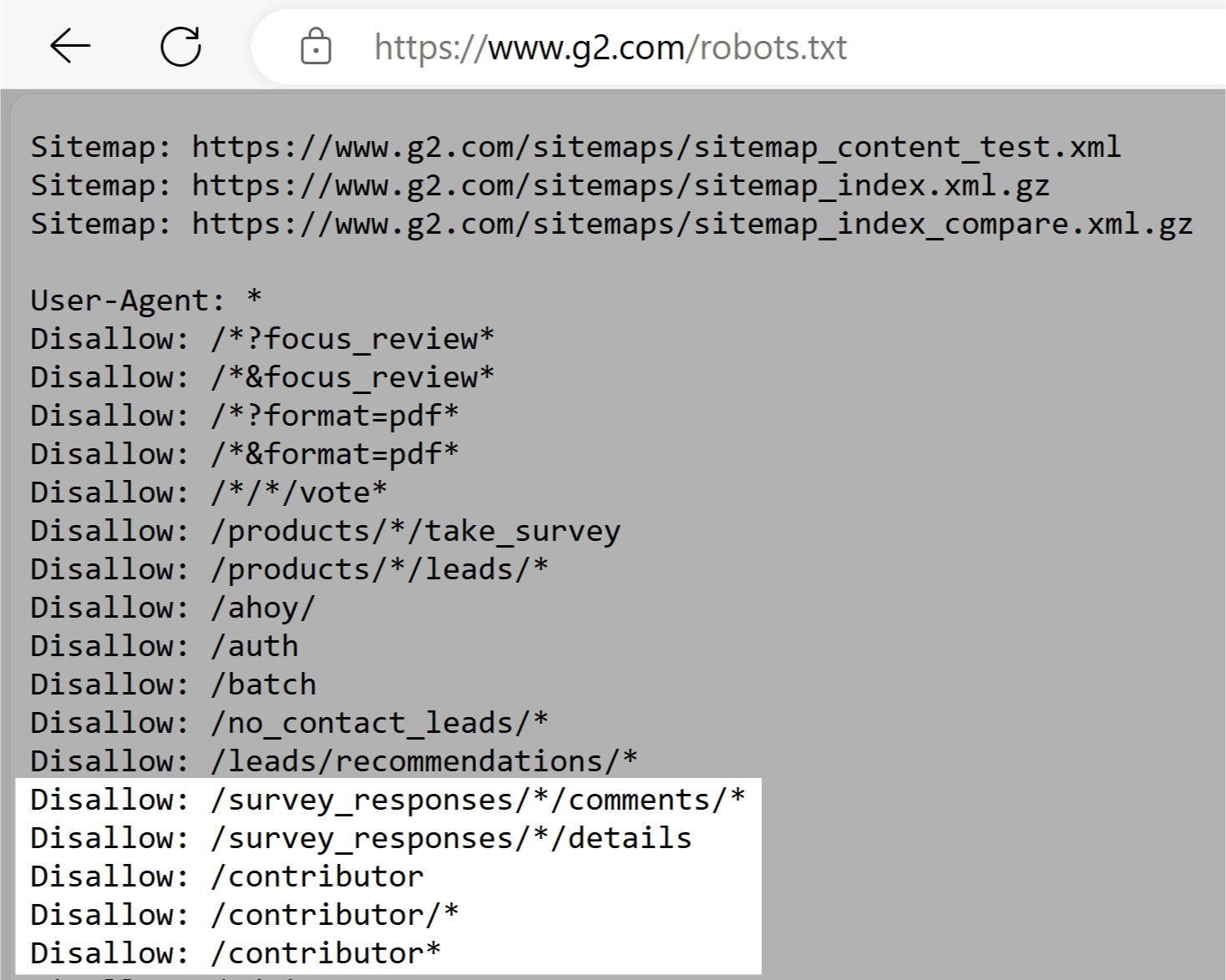
G2’s robots.txt record tells crawlers not to entree sections with user-generated content. Like survey responses, comments, and contributor profiles.
This helps support idiosyncratic privateness by protecting perchance delicate idiosyncratic information. And besides prevents users from attempting to manipulate hunt results.
Nike
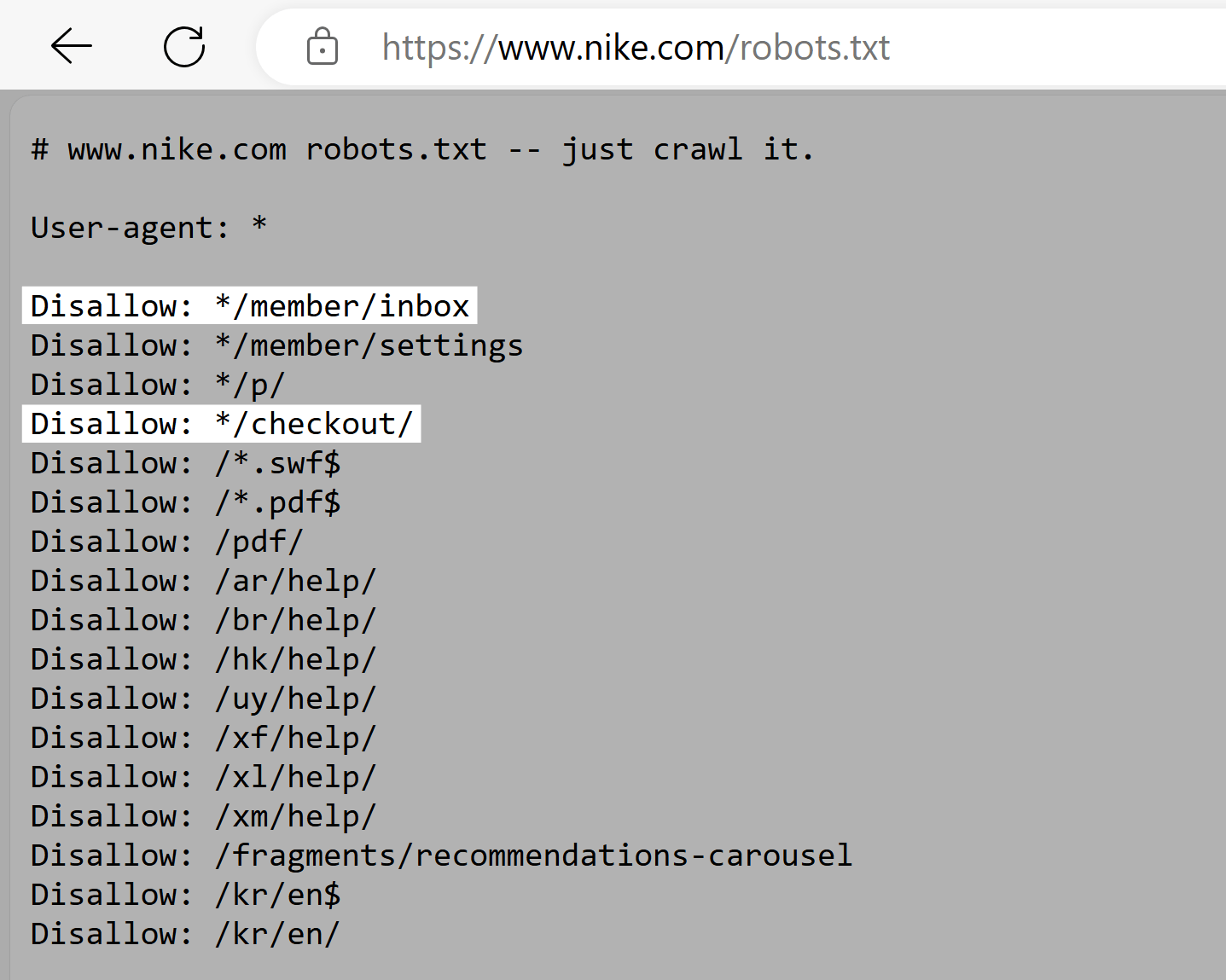
Nike’s robots.txt record uses the disallow directive to artifact crawlers from accessing user-generated directories. Like "/checkout/" and "*/member/inbox."
This ensures that perchance delicate idiosyncratic information isn’t exposed successful hunt results. And prevents attempts to manipulate SEO rankings.
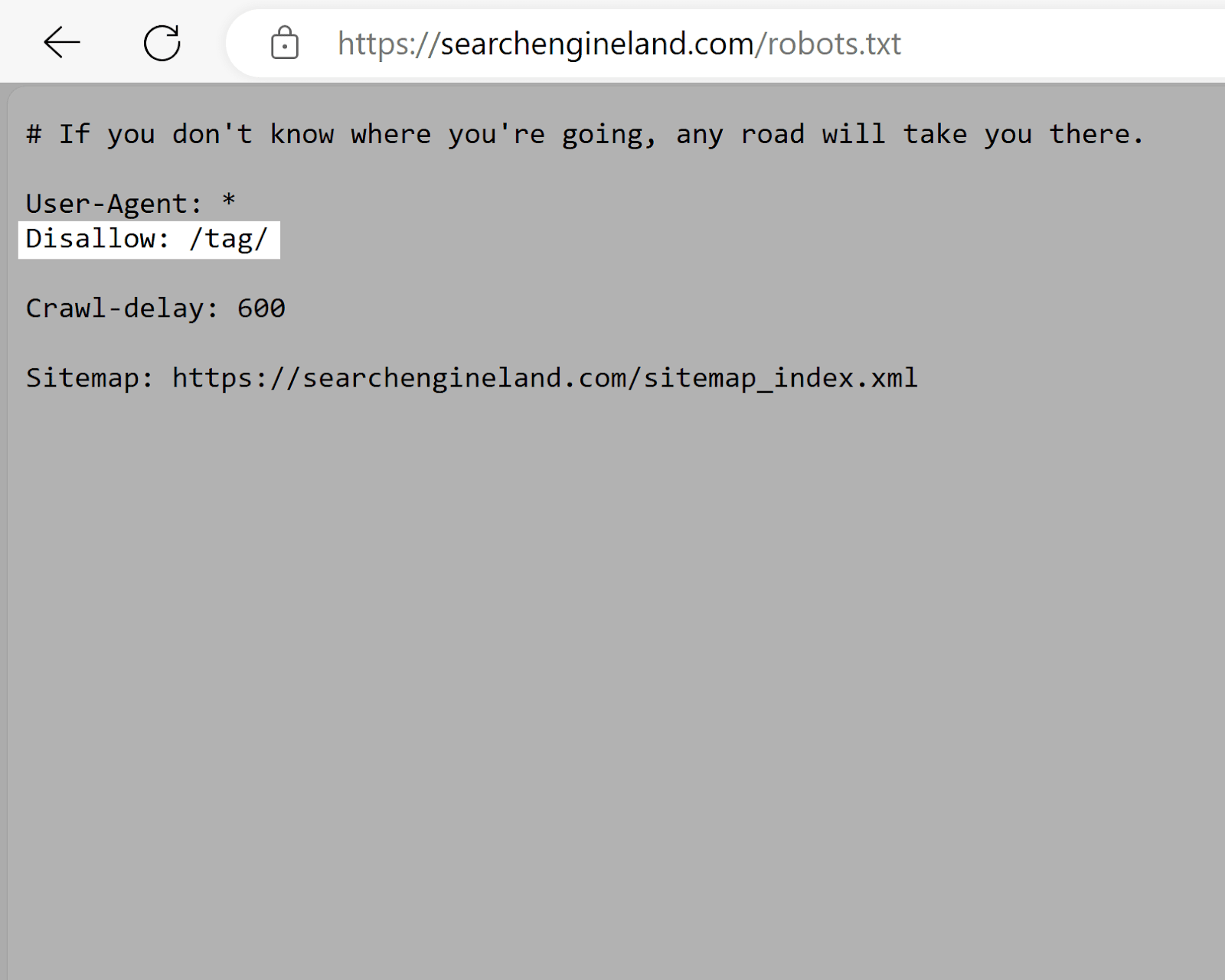
Search Engine Land
Search Engine Land’s robots.txt record uses the disallow tag to discourage the indexing of "/tag/" directory pages. Which thin to person debased SEO worth compared to existent contented pages. And tin origin duplicate content issues.
This encourages hunt engines to prioritize crawling higher-quality content, maximizing the website's crawl budget.
Which is particularly important fixed however galore pages Search Engine Land has.
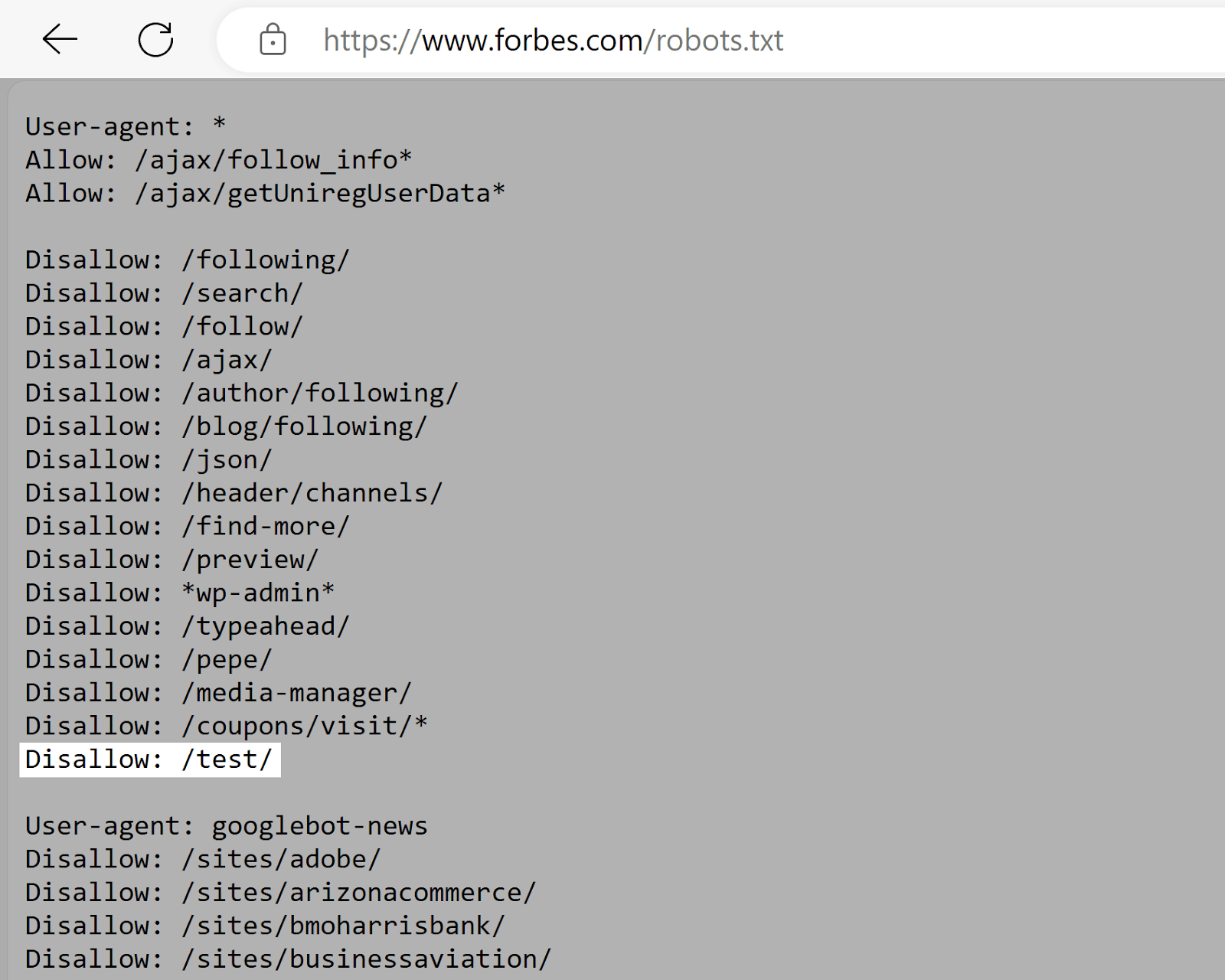
Forbes
Forbes’s robots.txt record instructs Google to debar the "/test/" directory. Which apt contains investigating oregon staging environments.
This prevents unfinished oregon delicate contented from being indexed (assuming it isn’t linked to elsewhere.)
Explaining Robots.txt Syntax
A robots.txt record is made up of:
- One oregon much blocks of “directives” (rules)
- Each with a specified “user-agent” (search motor bot)
- And an “allow” oregon “disallow” instruction
A elemental artifact tin look similar this:
User-agent: Googlebot
Disallow: /not-for-google
User-agent: DuckDuckBot
Disallow: /not-for-duckduckgo
Sitemap: https://www.yourwebsite.com/sitemap.xml
The User-Agent Directive
The archetypal enactment of each directive artifact is the user-agent, which identifies the crawler.
If you privation to archer Googlebot not to crawl your WordPress admin page, for example, your directive volition commencement with:
User-agent: Googlebot
Disallow: /wp-admin/
When aggregate directives are present, the bot whitethorn take the astir circumstantial artifact of directives available.
Let’s accidental you person 3 sets of directives: 1 for *, 1 for Googlebot, and 1 for Googlebot-Image.
If the Googlebot-News idiosyncratic cause crawls your site, it volition travel the Googlebot directives.
On the different hand, the Googlebot-Image idiosyncratic cause volition travel the much circumstantial Googlebot-Image directives.
The Disallow Robots.txt Directive
The 2nd enactment of a robots.txt directive is the “disallow” line.
You tin person aggregate disallow directives that specify which parts of your tract the crawler can’t access.
An bare disallow enactment means you’re not disallowing anything—a crawler tin entree each sections of your site.
For example, if you wanted to let each hunt engines to crawl your full site, your artifact would look similar this:
User-agent: *
Allow: /
If you wanted to artifact each hunt engines from crawling your site, your artifact would look similar this:
User-agent: *
Disallow: /
The Allow Directive
The “allow” directive allows hunt engines to crawl a subdirectory oregon circumstantial page, adjacent successful an different disallowed directory.
For example, if you privation to forestall Googlebot from accessing each station connected your blog but for one, your directive mightiness look similar this:
User-agent: Googlebot
Disallow: /blog
Allow: /blog/example-post
The Sitemap Directive
The Sitemap directive tells hunt engines—specifically Bing, Yandex, and Google—where to find your XML sitemap.
Sitemaps mostly see the pages you privation hunt engines to crawl and index.
This directive lives astatine the apical oregon bottommost of a robots.txt record and looks similar this:
Adding a Sitemap directive to your robots.txt record is simply a speedy alternative. But you tin (and should) besides submit your XML sitemap to each hunt motor utilizing their webmaster tools.
Search engines volition crawl your tract eventually, but submitting a sitemap speeds up the crawling process.
The Crawl-Delay Directive
The “crawl-delay” directive instructs crawlers to hold their crawl rates. To debar overtaxing a server (i.e., slowing down your website).
Google nary longer supports the crawl-delay directive. And if you privation to acceptable your crawl complaint for Googlebot, you’ll person to bash it successful Search Console.
But Bing and Yandex do enactment the crawl-delay directive. Here’s however to usage it.
Let’s accidental you privation a crawler to hold 10 seconds aft each crawl action. You would acceptable the hold to 10 similar so:
User-agent: *
Crawl-delay: 10
Further reading: 15 Crawlability Problems & How to Fix Them
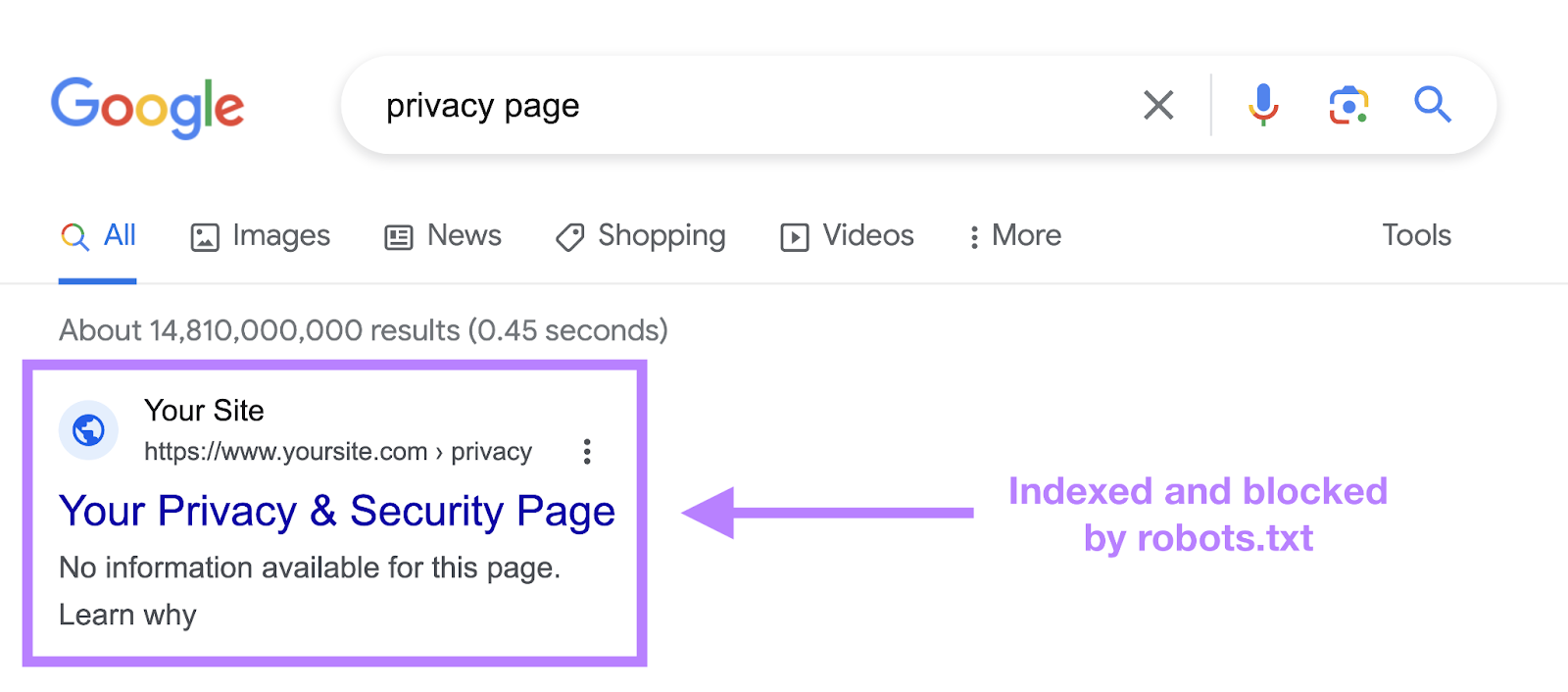
The Noindex Directive
A robots.txt record tells a bot what it should oregon shouldn’t crawl. But it can’t archer a hunt motor which URLs not to scale and service successful hunt results.
Using the noindex tag successful your robots.txt record whitethorn artifact a bot from knowing what’s connected your page. But the leafage tin inactive amusement up successful hunt results. Albeit with nary information.
Like this:
Google ne'er officially supported this directive. And connected September 1, 2019, Google adjacent announced that they so don’t support the noindex directive successful robots.txt.
If you privation to reliably exclude a leafage oregon record from appearing successful hunt results, avoid this directive altogether and usage a meta robots noindex tag instead.
How to Create a Robots.txt File
Use a robots.txt generator tool oregon make 1 yourself.
Here’s however to make 1 from scratch:
1. Create a File and Name It Robots.txt
Start by opening a .txt papers wrong a substance editor oregon web browser.
Next, sanction the papers “robots.txt.”
You’re present acceptable to commencement typing directives.
2. Add Directives to the Robots.txt File
A robots.txt record consists of 1 oregon much groups of directives. And each radical consists of aggregate lines of instructions.
Each radical begins with a user-agent and has the pursuing information:
- Who the radical applies to (the user-agent)
- Which directories (pages) oregon files the cause should access
- Which directories (pages) oregon files the cause shouldn’t access
- A sitemap (optional) to archer hunt engines which pages and files you deem important
Crawlers disregard lines that don’t lucifer these directives.
Let’s accidental you don’t privation Google crawling your “/clients/” directory due to the fact that it’s conscionable for interior use.
The archetypal radical would look thing similar this:
User-agent: Googlebot
Disallow: /clients/
Additional instructions tin beryllium added successful a abstracted enactment below, similar this:
User-agent: Googlebot
Disallow: /clients/
Disallow: /not-for-google
Once you’re done with Google’s circumstantial instructions, deed participate doubly to make a caller radical of directives.
Let’s marque this 1 for each hunt engines and forestall them from crawling your “/archive/” and “/support/” directories due to the fact that they’re for interior usage only.
It would look similar this:
User-agent: Googlebot
Disallow: /clients/
Disallow: /not-for-google
User-agent: *
Disallow: /archive/
Disallow: /support/
Once you’re finished, adhd your sitemap.
Your finished robots.txt record would look thing similar this:
User-agent: Googlebot
Disallow: /clients/
Disallow: /not-for-google
User-agent: *
Disallow: /archive/
Disallow: /support/
Sitemap: https://www.yourwebsite.com/sitemap.xml
Then, prevention your robots.txt file. And retrieve that it indispensable beryllium named “robots.txt.”
3. Upload the Robots.txt File
After you’ve saved the robots.txt record to your computer, upload it to your tract and marque it disposable for hunt engines to crawl.
Unfortunately, there’s nary cosmopolitan instrumentality for this step.
Uploading the robots.txt record depends connected your site’s record operation and web hosting.
Search online oregon scope retired to your hosting supplier for assistance connected uploading your robots.txt file.
For example, you tin hunt for "upload robots.txt record to WordPress."
Below are immoderate articles explaining however to upload your robots.txt record successful the astir fashionable platforms:
- Robots.txt record successful WordPress
- Robots.txt record successful Wix
- Robots.txt record successful Joomla
- Robots.txt record successful Shopify
- Robots.txt record successful BigCommerce
After uploading the file, cheque if anyone tin spot it and if Google tin work it.
Here’s how.
4. Test Your Robots.txt File
First, trial whether your robots.txt record is publically accessible (i.e., if it was uploaded correctly).
Open a backstage model successful your browser and hunt for your robots.txt file.
For example, “https://semrush.com/robots.txt.”
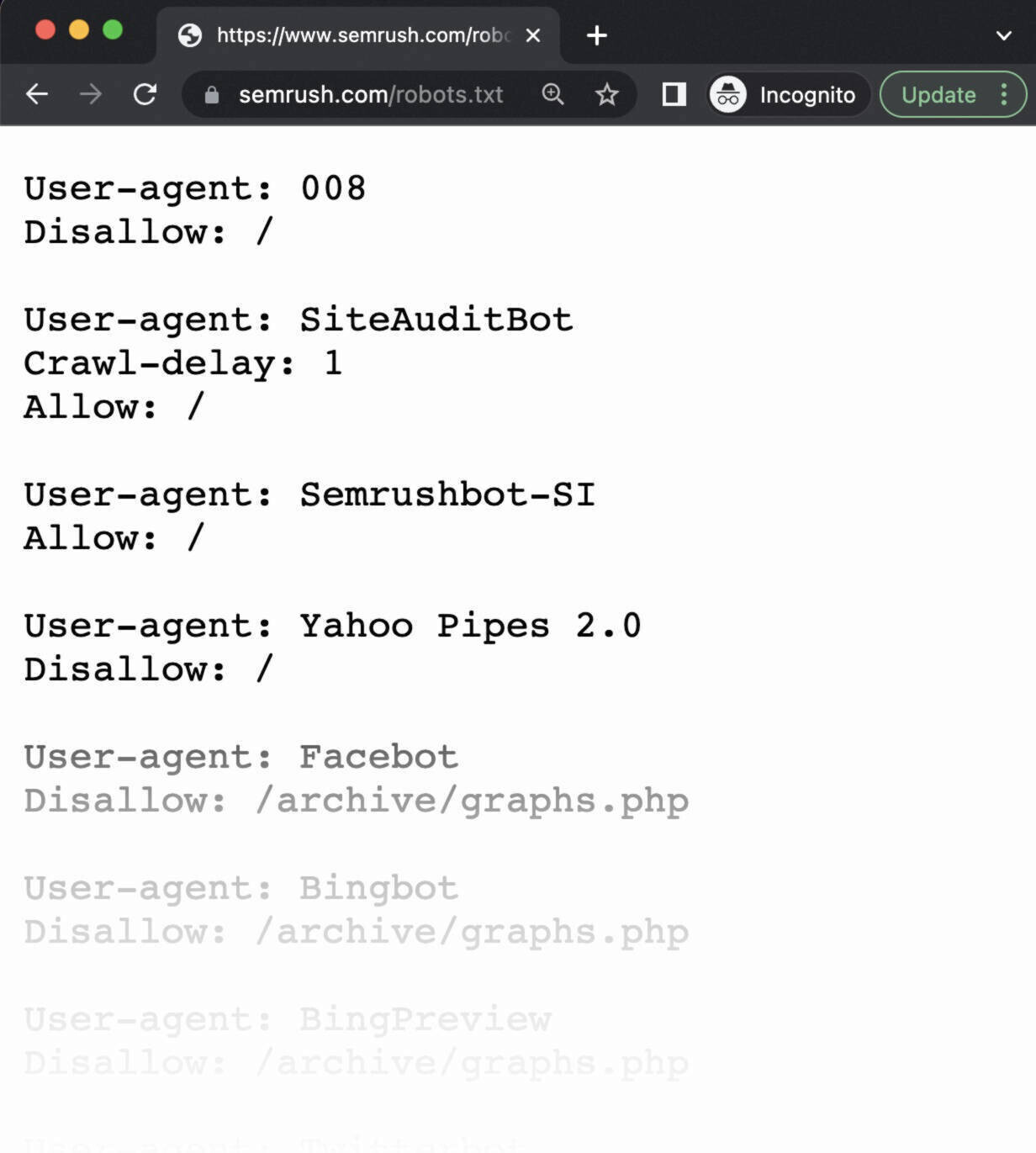
If you spot your robots.txt record with the contented you added, you’re acceptable to trial the markup (HTML code).
Google offers 2 options for investigating robots.txt markup:
- The robots.txt report successful Search Console
- Google’s open-source robots.txt library (advanced)
Because the 2nd enactment is geared toward precocious developers, let’s trial with Search Console.
Go to the robots.txt report by clicking the link.
If you haven’t linked your website to your Google Search Console account, you’ll request to adhd a spot first.
Then, verify that you’re the site’s owner.
If you person existing verified properties, prime 1 from the drop-down list.
The instrumentality volition place syntax warnings and logic errors.
And show the full fig of warnings and errors beneath the editor.
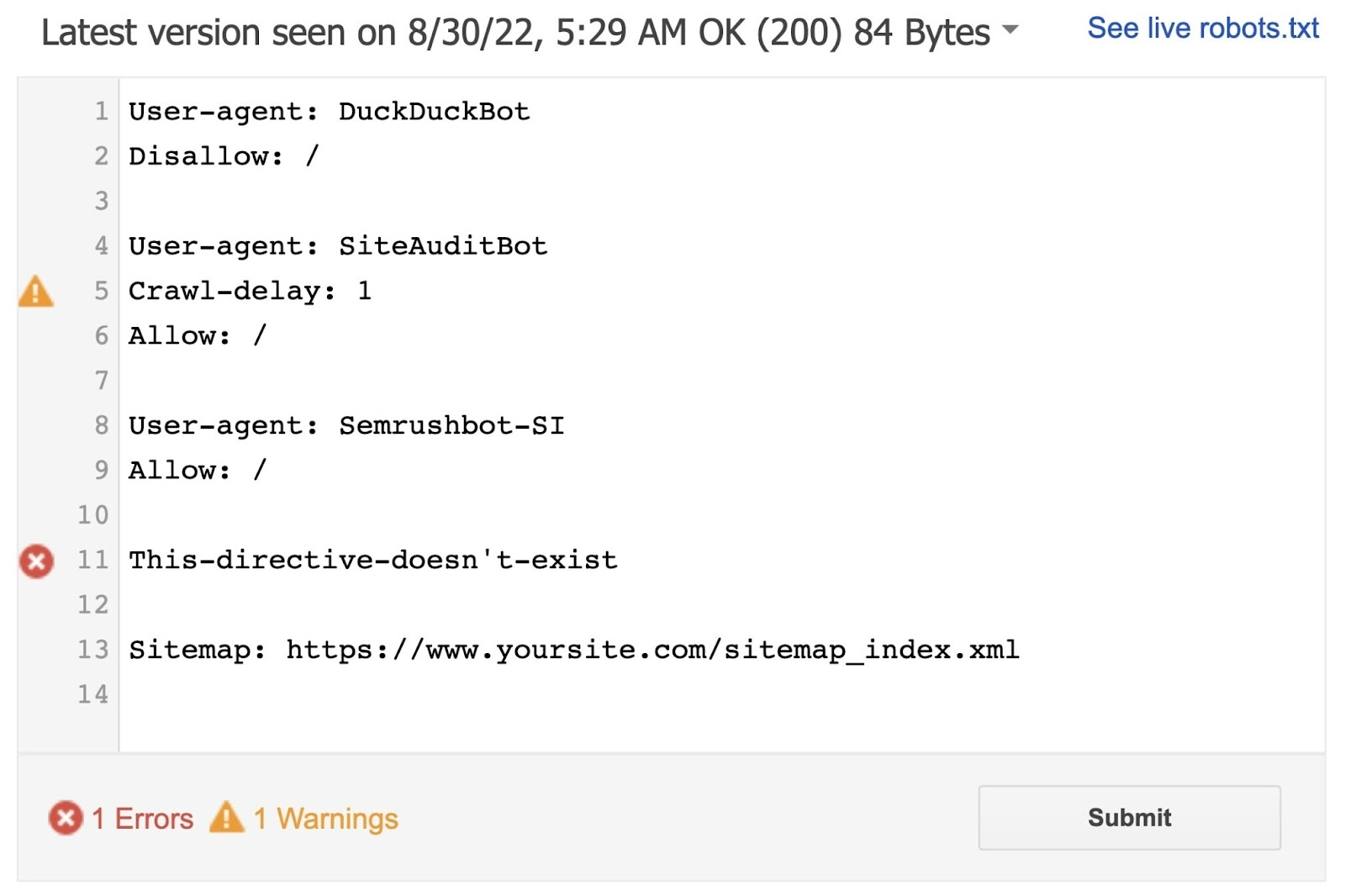
You tin edit errors oregon warnings straight connected the leafage and retest arsenic you go.
Any changes made connected the leafage aren’t saved to your site. So, transcript and paste the edited trial transcript into the robots.txt record connected your site.
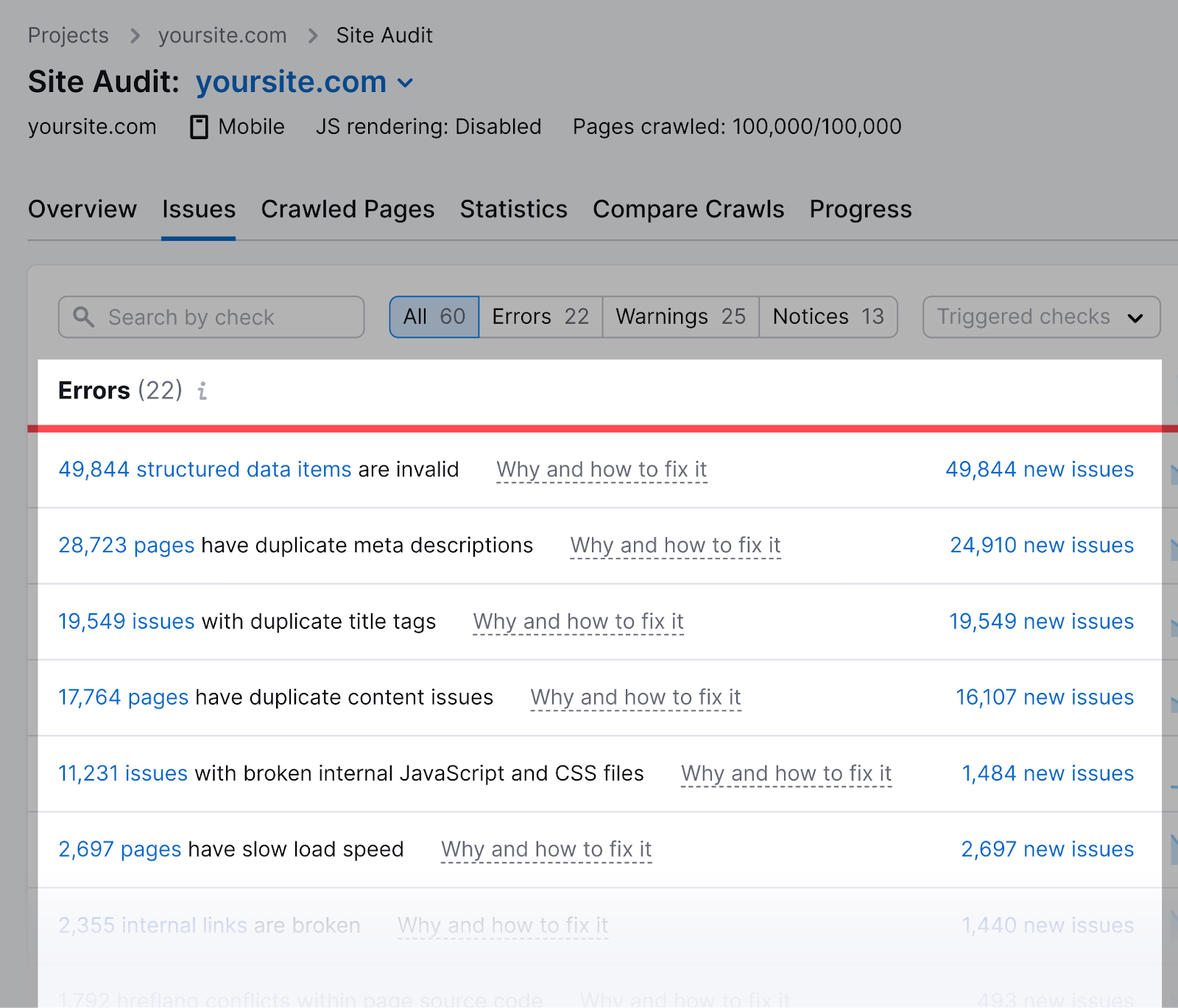
Semrush’s Site Audit instrumentality tin besides cheque for issues regarding your robots.txt file.
First, set up a task successful the tool to audit your website.
Once the audit is complete, navigate to the “Issues” tab and hunt for “robots.txt.”
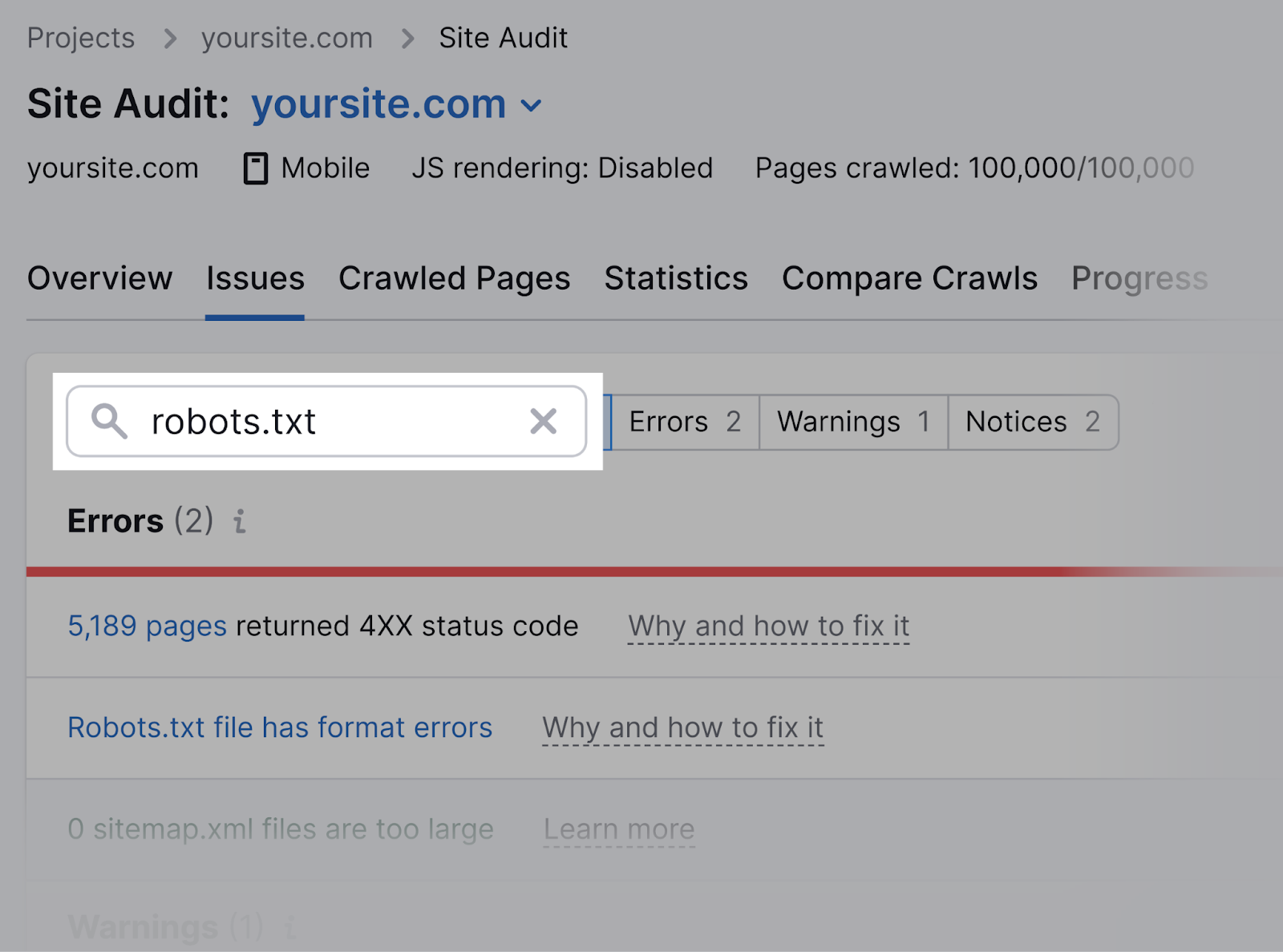
Click connected the “Robots.txt record has format errors” nexus if it turns retired that your record has format errors.
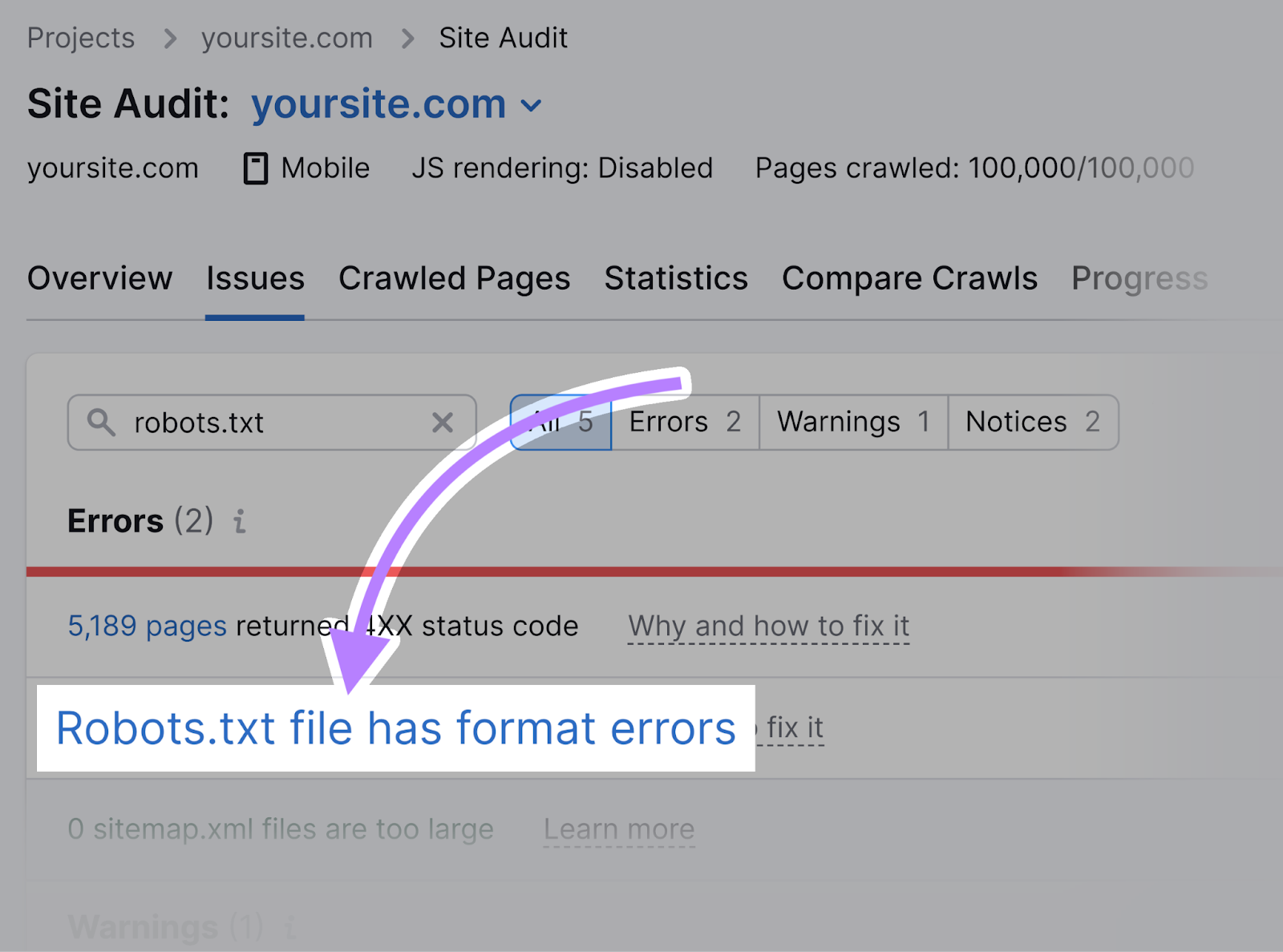
You’ll spot a database of invalid lines.
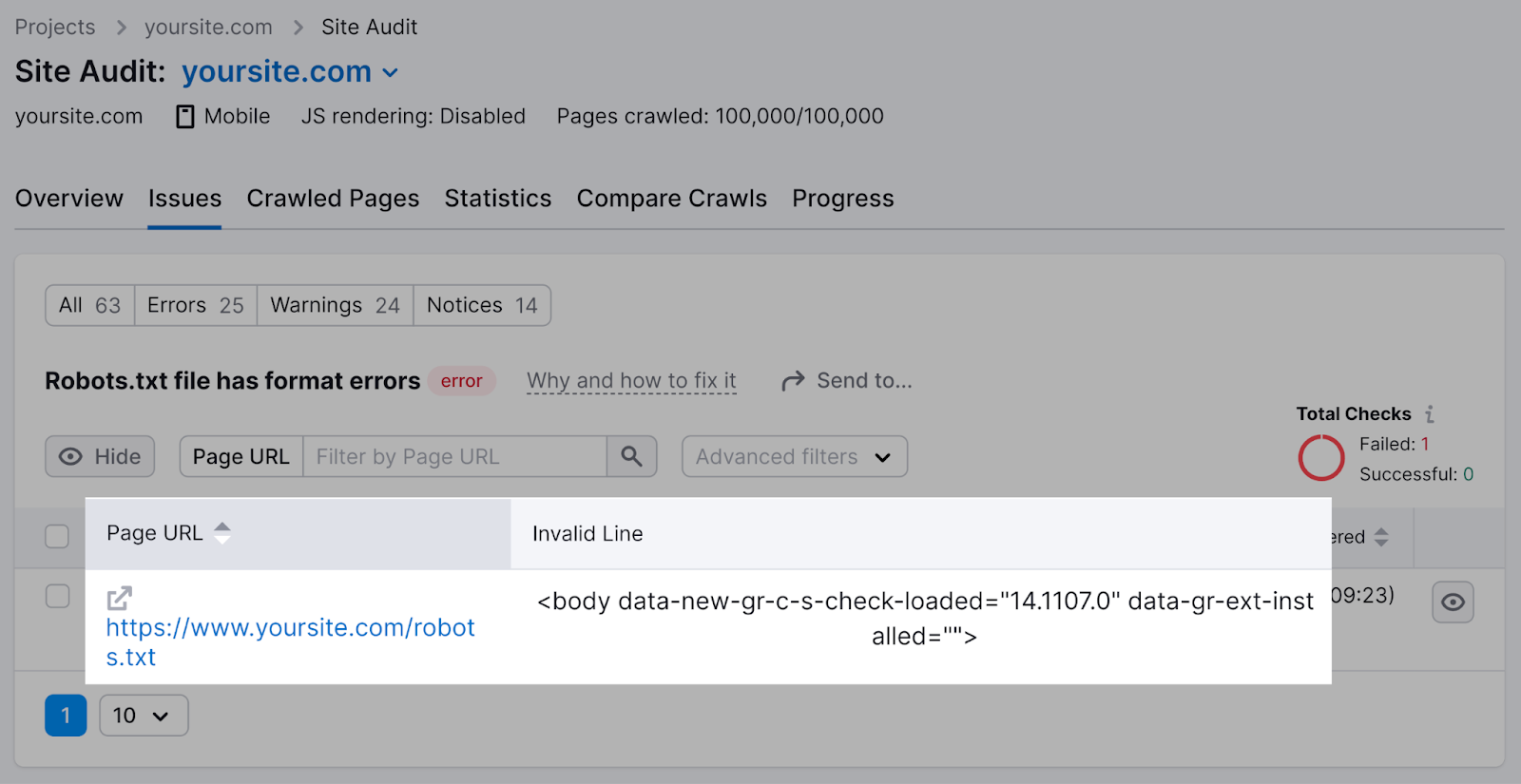
You tin click “Why and however to hole it” to get circumstantial instructions connected however to hole the error.
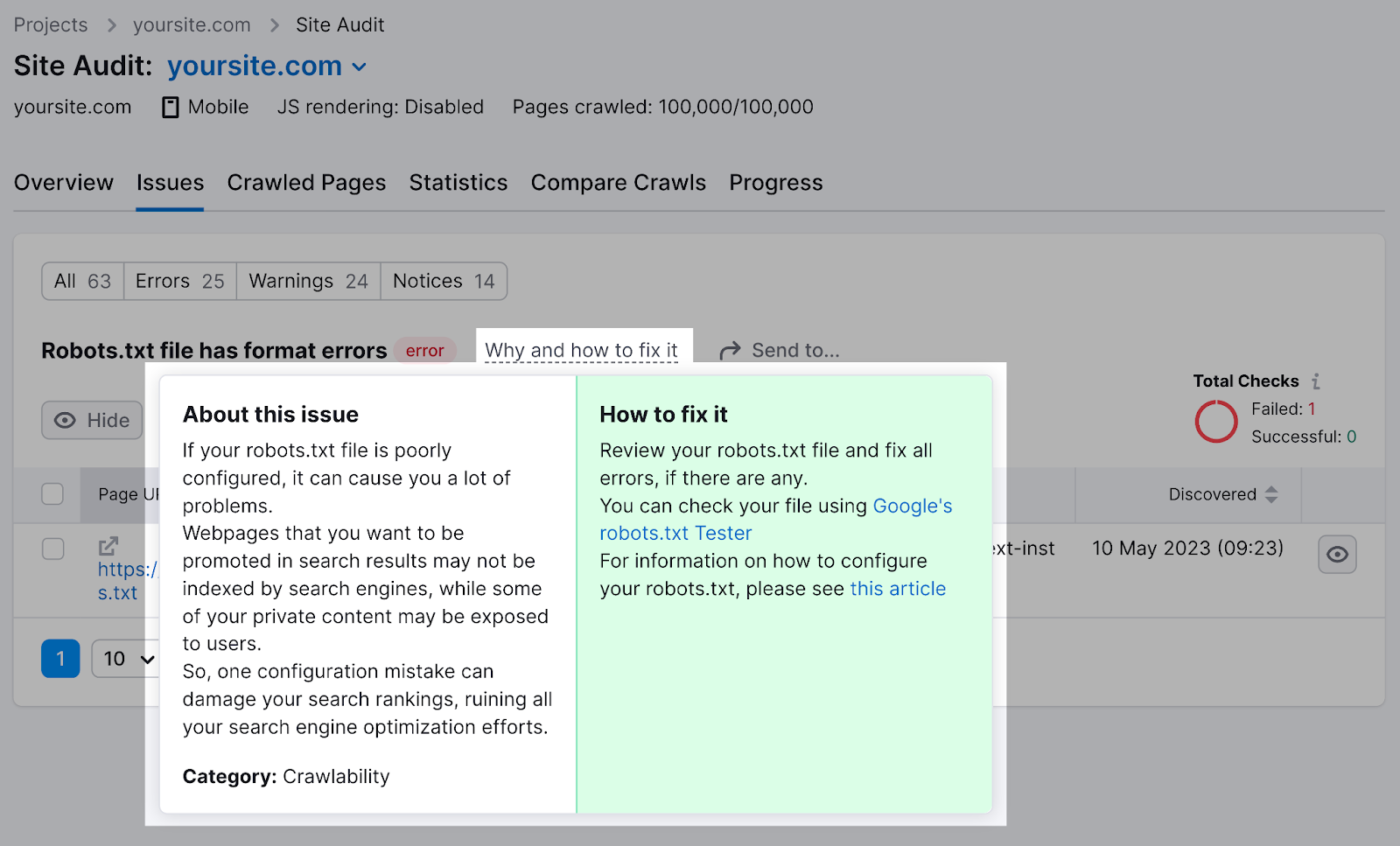
Checking your robots.txt record for issues is important, arsenic adjacent insignificant mistakes tin negatively impact your site’s indexability.
Robots.txt Best Practices
Use a New Line for Each Directive
Each directive should beryllium connected a caller line.
Otherwise, hunt engines won’t beryllium capable to work them. And your instructions volition beryllium ignored.
Incorrect:
User-agent: * Disallow: /admin/
Disallow: /directory/
Correct:
User-agent: *
Disallow: /admin/
Disallow: /directory/
Use Each User-Agent Only Once
Bots don’t caput if you participate the aforesaid user-agent aggregate times.
But referencing it lone erstwhile keeps things neat and simple. And reduces the chances of quality error.
Confusing:
User-agent: Googlebot
Disallow: /example-page
User-agent: Googlebot
Disallow: /example-page-2
Notice however the Googlebot user-agent is listed twice?
Clear:
User-agent: Googlebot
Disallow: /example-page
Disallow: /example-page-2
In the archetypal example, Google would inactive travel the instructions. But penning each directives nether the aforesaid user-agent is cleaner and helps you enactment organized.
Use Wildcards to Clarify Directions
You tin usage wildcards (*) to use a directive to each user-agents and lucifer URL patterns.
To forestall hunt engines from accessing URLs with parameters, you could technically database them retired 1 by one.
But that’s inefficient. You tin simplify your directions with a wildcard.
Inefficient:
User-agent: *
Disallow: /shoes/vans?
Disallow: /shoes/nike?
Disallow: /shoes/adidas?
Efficient:
User-agent: *
Disallow: /shoes/*?
The supra illustration blocks each hunt motor bots from crawling each URLs nether the “/shoes/” subfolder with a question mark.
Use ‘$’ to Indicate the End of a URL
Adding the “$” indicates the extremity of a URL.
For example, if you privation to artifact hunt engines from crawling each .jpg files connected your site, you tin database them individually.
But that would beryllium inefficient.
Inefficient:
User-agent: *
Disallow: /photo-a.jpg
Disallow: /photo-b.jpg
Disallow: /photo-c.jpg
Instead, adhd the “$” feature:
Efficient:
User-agent: *
Disallow: /*.jpg$
The “$” look is simply a adjuvant diagnostic successful circumstantial circumstances similar above. But it tin besides beryllium dangerous.
You tin easy unblock things you didn’t mean to, truthful beryllium prudent successful its application.
Crawlers disregard everything that starts with a hash (#).
So, developers often usage a hash to adhd a remark successful the robots.txt file. It helps support the record organized and casual to read.
To adhd a comment, statesman the enactment with a hash (#).
Like this:
User-agent: *
#Landing Pages
Disallow: /landing/
Disallow: /lp/
#Files
Disallow: /files/
Disallow: /private-files/
#Websites
Allow: /website/*
Disallow: /website/search/*
Developers occasionally see comic messages successful robots.txt files due to the fact that they cognize users seldom spot them.
For example, YouTube’s robots.txt record reads: “Created successful the distant aboriginal (the twelvemonth 2000) aft the robotic uprising of the mid 90’s which wiped retired each humans.”
And Nike’s robots.txt reads “just crawl it” (a motion to its “just bash it” tagline) and its logo.

Use Separate Robots.txt Files for Different Subdomains
Robots.txt files power crawling behaviour lone connected the subdomain successful which they’re hosted.
To power crawling connected a antithetic subdomain, you’ll request a abstracted robots.txt file.
So, if your main tract lives connected “domain.com” and your blog lives connected the subdomain “blog.domain.com,” you’d request 2 robots.txt files. One for the main domain's basal directory and the different for your blog’s basal directory.
5 Robots.txt Mistakes to Avoid
When creating your robots.txt file, present are immoderate communal mistakes you should ticker retired for.
1. Not Including Robots.txt successful the Root Directory
Your robots.txt record should ever beryllium located successful your site's basal directory. So that hunt motor crawlers tin find your record easily.
For example, if your website is “www.example.com,” your robots.txt record should beryllium located astatine "www.example.com/robots.txt."
If you enactment your robots.txt record successful a subdirectory, specified arsenic "www.example.com/contact/robots.txt," hunt motor crawlers whitethorn not find it. And whitethorn presume that you haven't acceptable immoderate crawling instructions for your website.
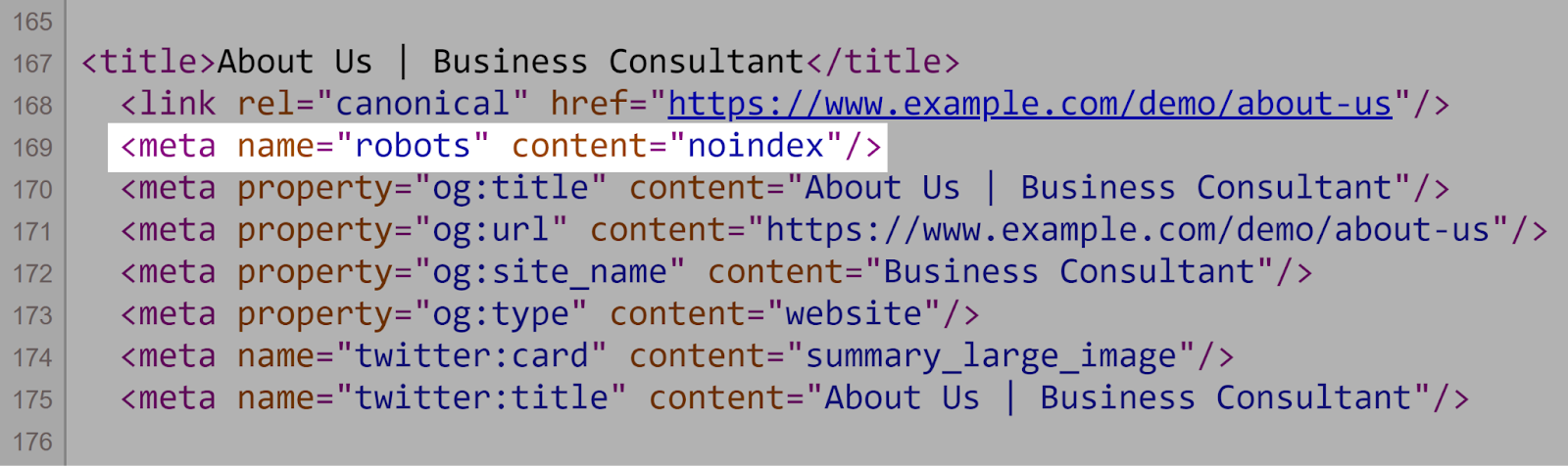
2. Using Noindex Instructions successful Robots.txt
Robots.txt should absorption connected crawling directives, not indexing ones. Again, Google doesn’t support the noindex regularisation successful the robots.txt file.
Instead, usage meta robots tags (e.g., <meta name="robots" content="noindex">) connected idiosyncratic pages to power indexing.
Like so:
3. Blocking JavaScript and CSS
Be cautious not to artifact hunt engines from accessing JavaScript and CSS files via robots.txt. Unless you person a circumstantial crushed for doing so, specified arsenic restricting entree to delicate data.
Blocking hunt engines from crawling these files utilizing your robots.txt tin marque it harder for those hunt engines to recognize your site's structure and content.
Which tin perchance harm your hunt rankings. Because hunt engines whitethorn not beryllium capable to afloat render your pages.
Further reading: JavaScript SEO: How to Optimize JS for Search Engines
4. Not Blocking Access to Your Unfinished Site oregon Pages
When processing a caller mentation of your site, you should usage robots.txt to artifact hunt engines from uncovering it prematurely. To forestall unfinished contented from being shown successful hunt results.
Search engines crawling and indexing an in-development leafage tin pb to mediocre user experience. And imaginable duplicate contented issues.
By blocking entree to your unfinished tract with robots.txt, you guarantee that lone your site's final, polished mentation appears successful hunt results.
5. Using Absolute URLs
Use comparative URLs successful your robots.txt record to marque it easier to negociate and maintain.
Absolute URLs are unnecessary and tin present errors if your domain changes.
❌ Here’s an illustration of a robots.txt record with implicit URLs:
User-agent: *
Disallow: https://www.example.com/private-directory/
Disallow: https://www.example.com/temp/
Allow: https://www.example.com/important-directory/
✅ And 1 without:
User-agent: *
Disallow: /private-directory/
Disallow: /temp/
Allow: /important-directory/
Keep Your Robots.txt File Error-Free
Now that you recognize however robots.txt files work, it's important to optimize your ain robots.txt file. Because adjacent tiny mistakes tin negatively interaction your website's quality to beryllium decently crawled, indexed, and displayed successful hunt results.
Semrush's Site Audit instrumentality makes it casual to analyse your robots.txt record for errors and get actionable recommendations to hole immoderate issues.

![Win Higher-Quality Links: The PR Approach To SEO Success [Webinar] via @sejournal, @lorenbaker](https://www.searchenginejournal.com/wp-content/uploads/2025/03/featured-1-716.png)





 English (US)
English (US)