ARTICLE AD BOX
A vector database is simply a postulation of information wherever each portion of information is stored arsenic a (numerical) vector. A vector represents an entity oregon entity, specified arsenic an image, person, spot etc. successful the abstract N-dimensional space.
Vectors, arsenic explained successful the previous chapter, are important for identifying however entities are related and tin beryllium utilized to find their semantic similarity. This tin beryllium applied successful respective ways for SEO – specified arsenic grouping akin keywords oregon contented (using kNN).
In this article, we are going to larn a fewer ways to use AI to SEO, including uncovering semantically akin contented for interior linking. This tin assistance you refine your contented strategy successful an epoch wherever hunt engines progressively rely connected LLMs.
You tin besides work a erstwhile nonfiction successful this bid astir however to find keyword cannibalization utilizing OpenAI’s substance embeddings.
Let’s dive successful present to commencement gathering the ground of our tool.
How To Build An Internal Linking tool
If you person thousands of articles and privation to find the closest semantic similarity for your people query, you can’t make vector embeddings for each of them connected the alert to compare, arsenic it is highly inefficient.
For that to happen, we would request to make vector embeddings lone erstwhile and support them successful a database we tin query and find the closest lucifer article.
And that is what vector databases do: They are peculiar types of databases that store embeddings (vectors).
When you query the database, dissimilar accepted databases, they execute cosine similarity match and instrumentality vectors (in this lawsuit articles) closest to different vector (in this lawsuit a keyword phrase) being queried.
Here is what it looks like:
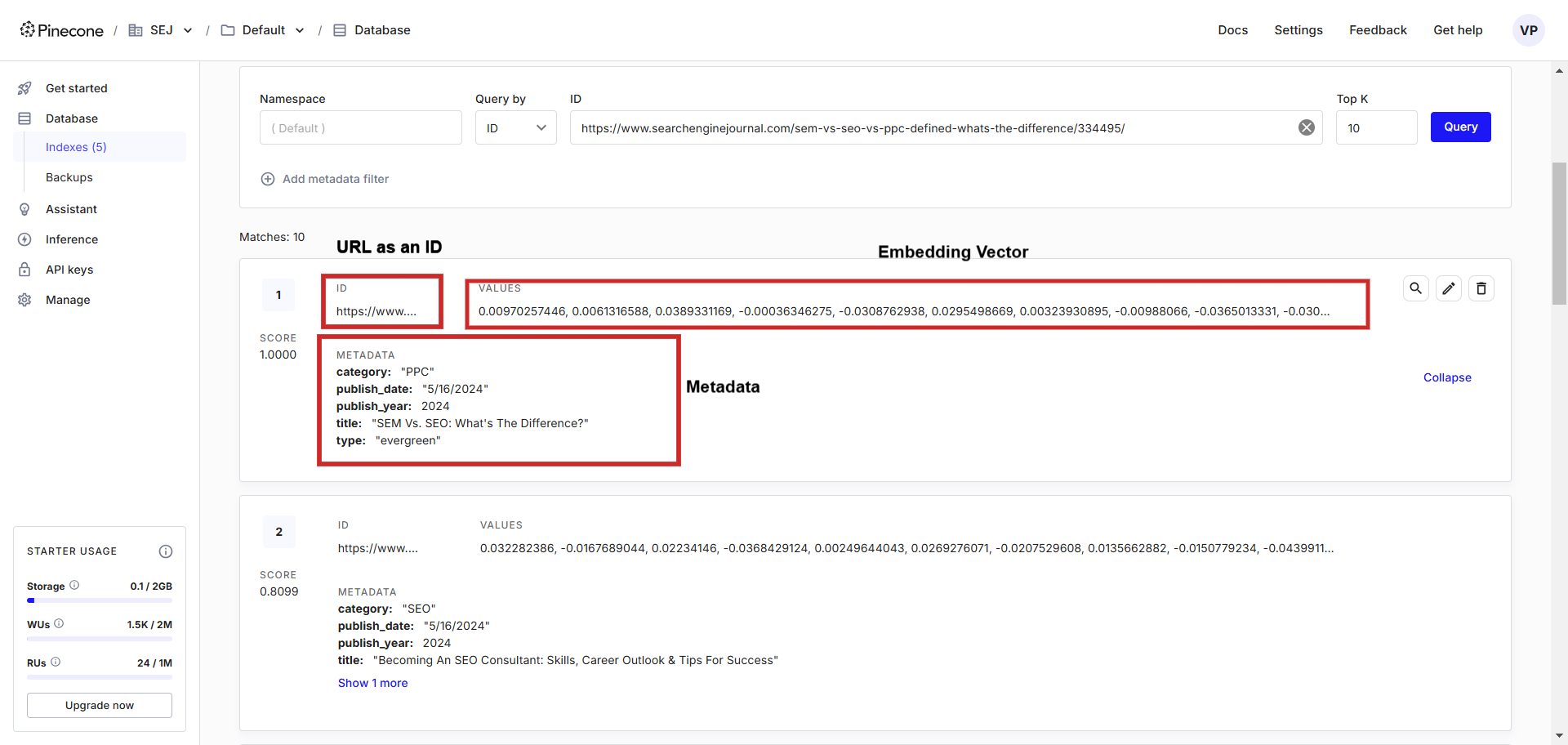 Text embedding grounds illustration successful the vector database.
Text embedding grounds illustration successful the vector database.
In the vector database, you tin spot vectors alongside metadata stored, which we can easily query utilizing a programming connection of our choice.
In this article, we volition beryllium using Pinecone due to its easiness of knowing and simplicity of use, but determination are different providers specified as Chroma, BigQuery, or Qdrant you whitethorn privation to cheque out.
Let’s dive in.
- 1. How To Build An Internal Linking tool
- 2. Create A Vector Database
- 3. Export Your Articles From Your CMS
- 4. Inserting OpenAi's Text Embeddings Into The Vector Database
- 5. Finding An Article Match For A Keyword
- 6. Inserting Google Vertex AI Text Embeddings Into The Vector Database
- 7. Finding An Article Match For A Keyword Using Google Vertex AI
- 8. Try Testing The Relevance Of Your Article Writing
1. Create A Vector Database
First, registry an relationship astatine Pinecone and make an scale with a configuration of “text-embedding-ada-002” with ‘cosine’ arsenic a metric to measurement vector distance. You tin sanction the scale anything, we volition sanction itarticle-index-all-ada‘.
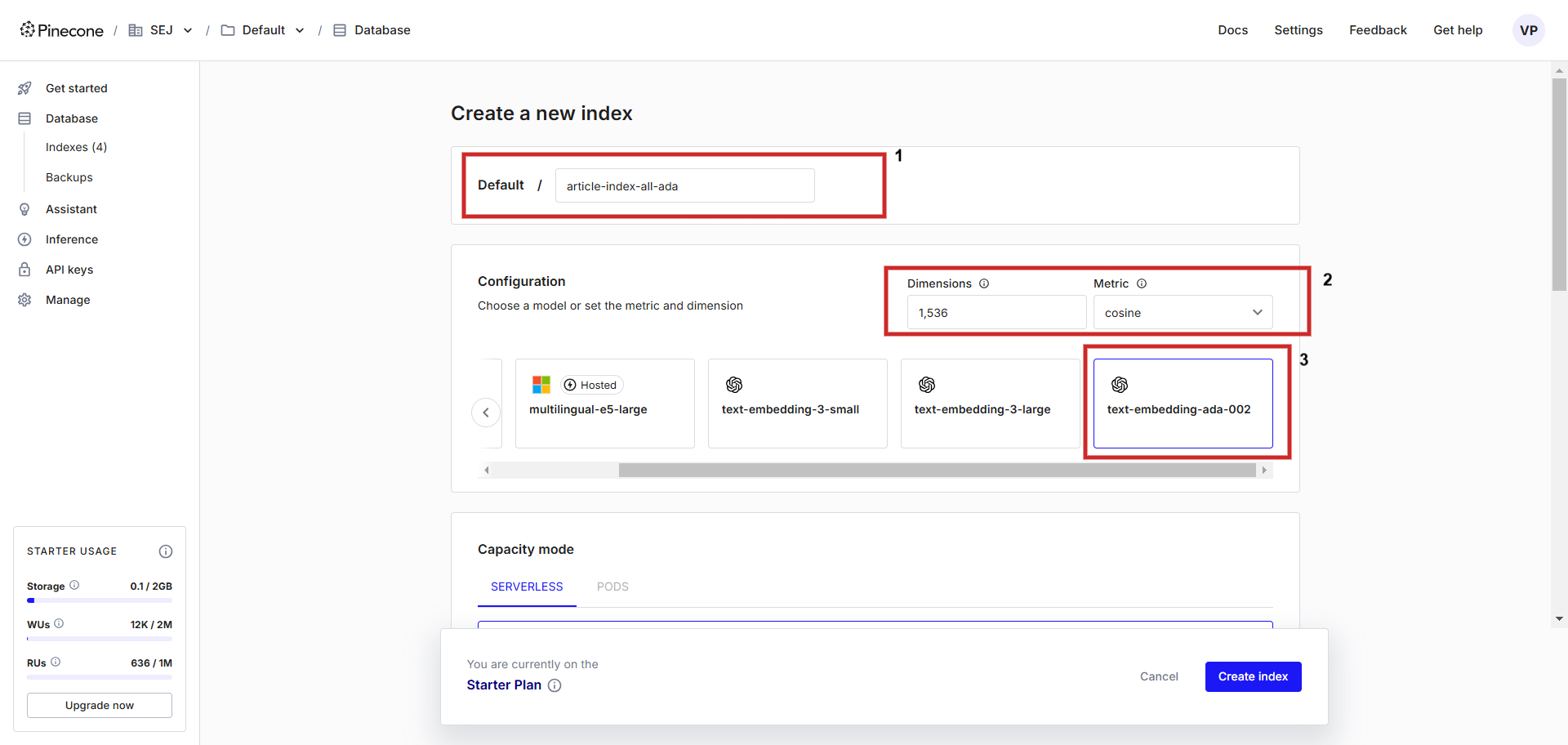 Creating a vector database.
Creating a vector database.
This helper UI is lone for assisting you during the setup, successful lawsuit you privation to store Vertex AI vector embedding you request to acceptable ‘dimensions’ to 768 successful the config surface manually to lucifer default dimensionality and you tin store Vertex AI substance vectors (you tin acceptable magnitude worth thing from 1 to 768 to prevention memory).
In this nonfiction we volition larn however to usage OpenAi’s ‘text-embedding-ada-002’ and Google’s Vertex AI ‘text-embedding-005’ models.
Once created, we request an API cardinal to beryllium capable to link to the database utilizing a big URL of the vector database.
Next, you volition request to usage Jupyter Notebook. If you don’t person it installed, travel this guide to instal it and tally this bid (below) afterward successful your PC’s terminal to instal each indispensable packages.
And retrieve ChatGPT is precise utile erstwhile you brushwood issues during coding!
2. Export Your Articles From Your CMS
Next, we request to hole a CSV export record of articles from your CMS. If you usage WordPress, you tin usage a plugin to bash customized exports.
As our eventual extremity is to physique an interior linking tool, we request to determine which information should beryllium pushed to the vector database arsenic metadata. Essentially, metadata-based filtering acts arsenic an further furniture of retrieval guidance, aligning it with the wide RAG framework by incorporating outer knowledge, which volition assistance to amended retrieval quality.
For instance, if we are editing an nonfiction connected “PPC” and privation to insert a nexus to the operation “Keyword Research,” we tin specify successful our instrumentality that “Category=PPC.” This volition let the instrumentality to query lone articles wrong the “PPC” category, ensuring close and contextually applicable linking, oregon we whitethorn privation to nexus to the operation “most caller google update” and bounds the lucifer lone to quality articles by utilizing ‘Type’ and published this year.
In our case, we volition beryllium exporting:
- Title.
- Category.
- Type.
- Publish Date.
- Publish Year.
- Permalink.
- Meta Description.
- Content.
To assistance instrumentality the champion results, we would concatenate the rubric and meta descriptions fields arsenic they are the champion practice of the nonfiction that we tin vectorize and perfect for embedding and interior linking purposes.
Using the afloat nonfiction contented for embeddings whitethorn trim precision and dilute the relevance of the vectors.
This happens due to the fact that a azygous ample embedding tries to correspond aggregate topics covered successful the nonfiction astatine once, starring to a little focused and applicable representation. Chunking strategies (splitting the nonfiction by earthy headings oregon semantically meaningful segments) request to beryllium applied, but these are not the absorption of this article.
Here’s the sample export file you tin download and usage for our codification illustration below.
2. Inserting OpenAi’s Text Embeddings Into The Vector Database
Assuming you already person an OpenAI API key, this codification volition make vector embeddings from the substance and insert them into the vector database successful Pinecone.
You request to make a notebook record and transcript and paste it successful there, past upload the CSV record ‘Sample Export File.csv’ successful the aforesaid folder.
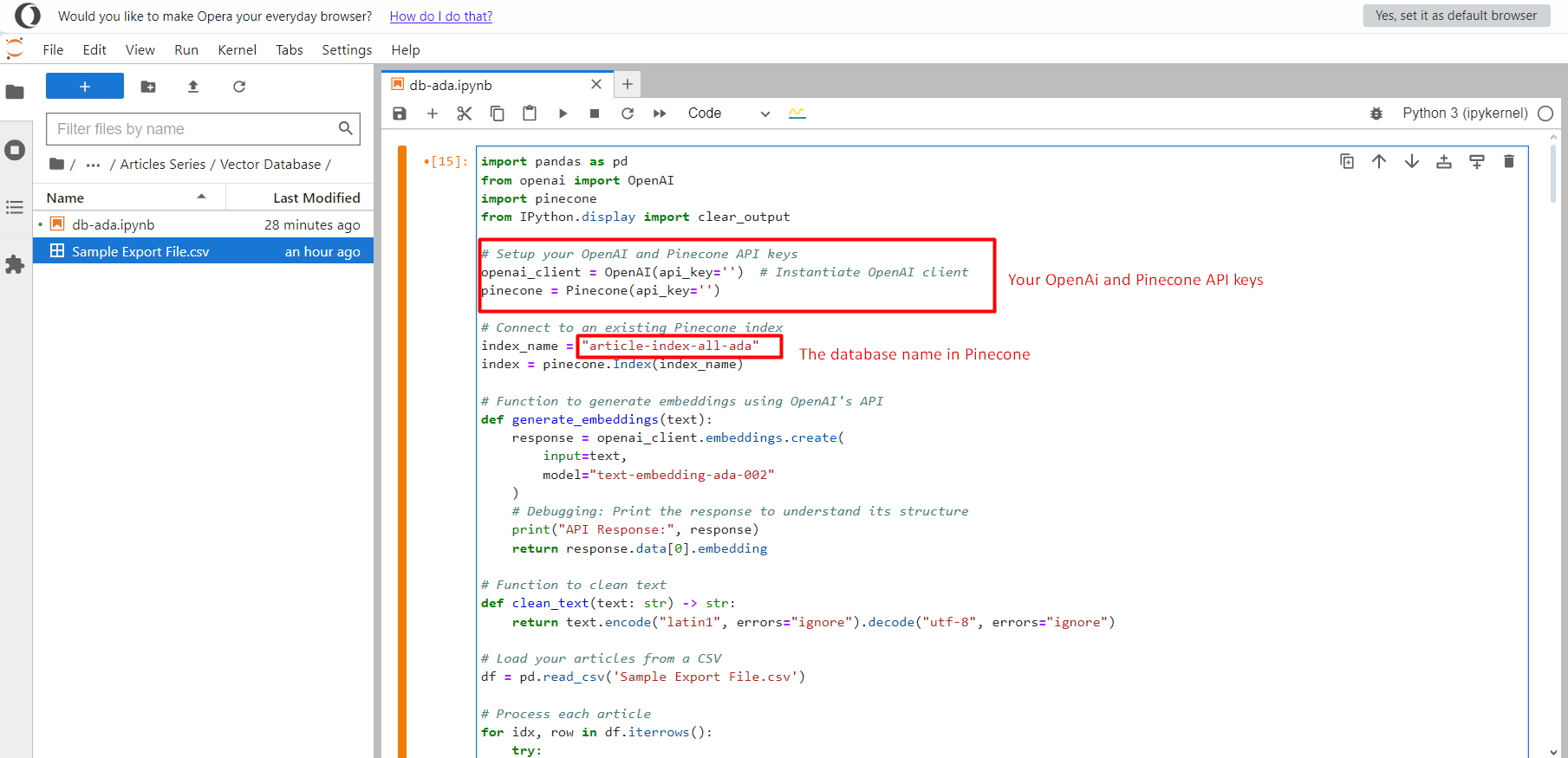 Jupyter project.
Jupyter project.
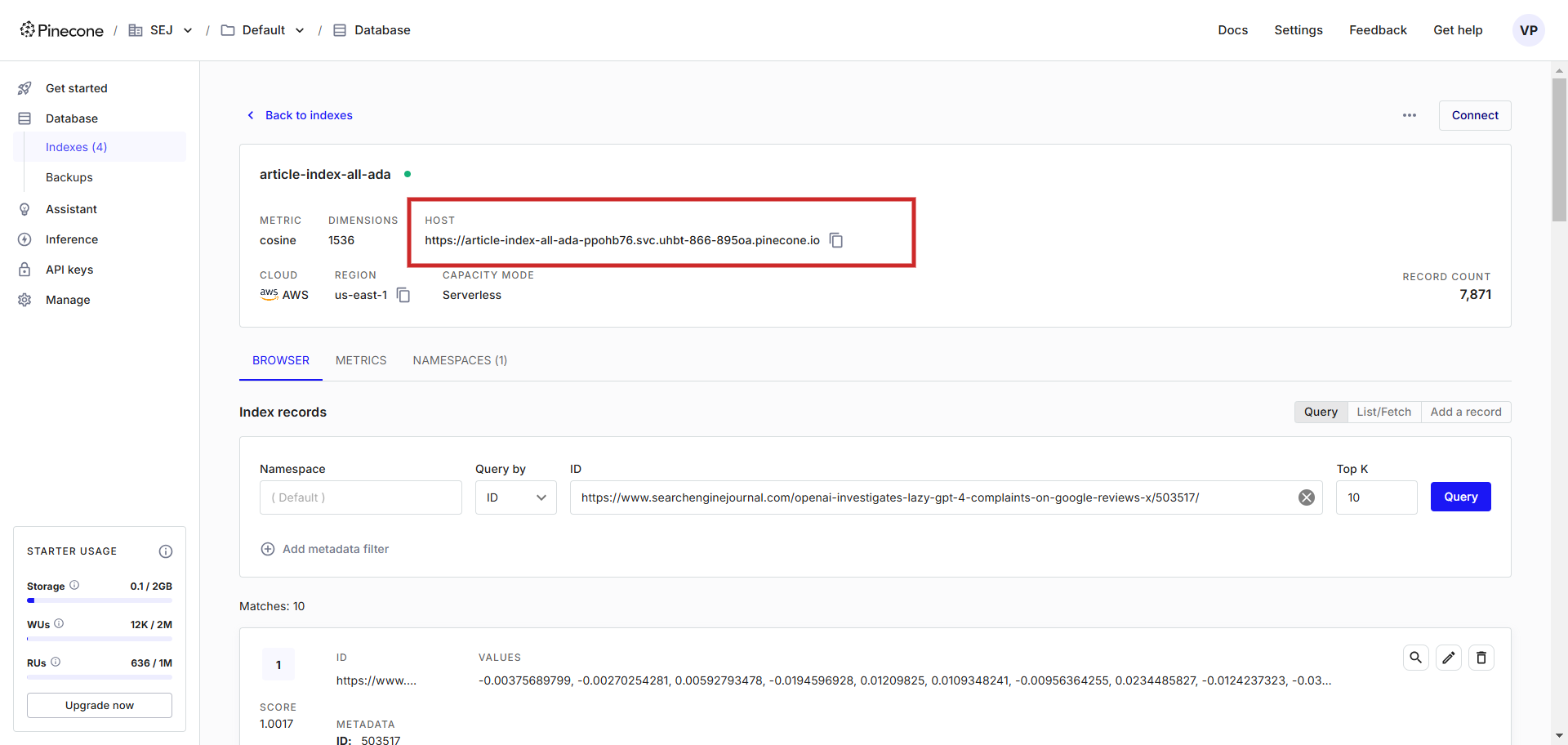
Once done, click connected the Run fastener and it volition commencement pushing each substance embedding vectors into the scale article-index-all-ada we created successful the archetypal step.
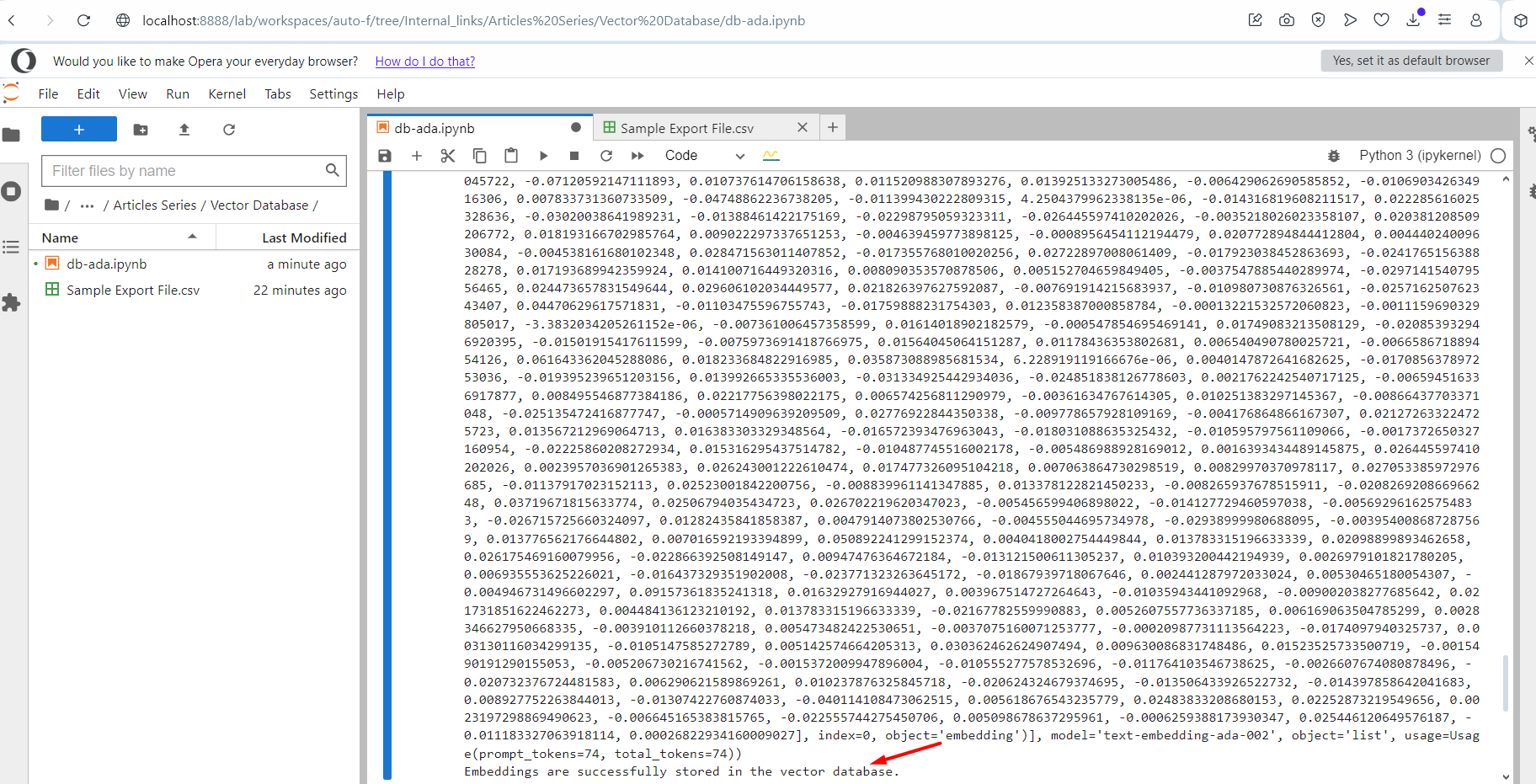 Running the script.
Running the script.
You volition spot an output log substance of embedding vectors. Once finished, it volition amusement the connection astatine the extremity that it was successfully finished. Now spell and cheque your scale successful the Pinecone and you volition spot your records are there.
3. Finding An Article Match For A Keyword
Okay now, let’s effort to find an nonfiction lucifer for the Keyword.
Create a caller notebook record and transcript and paste this code.
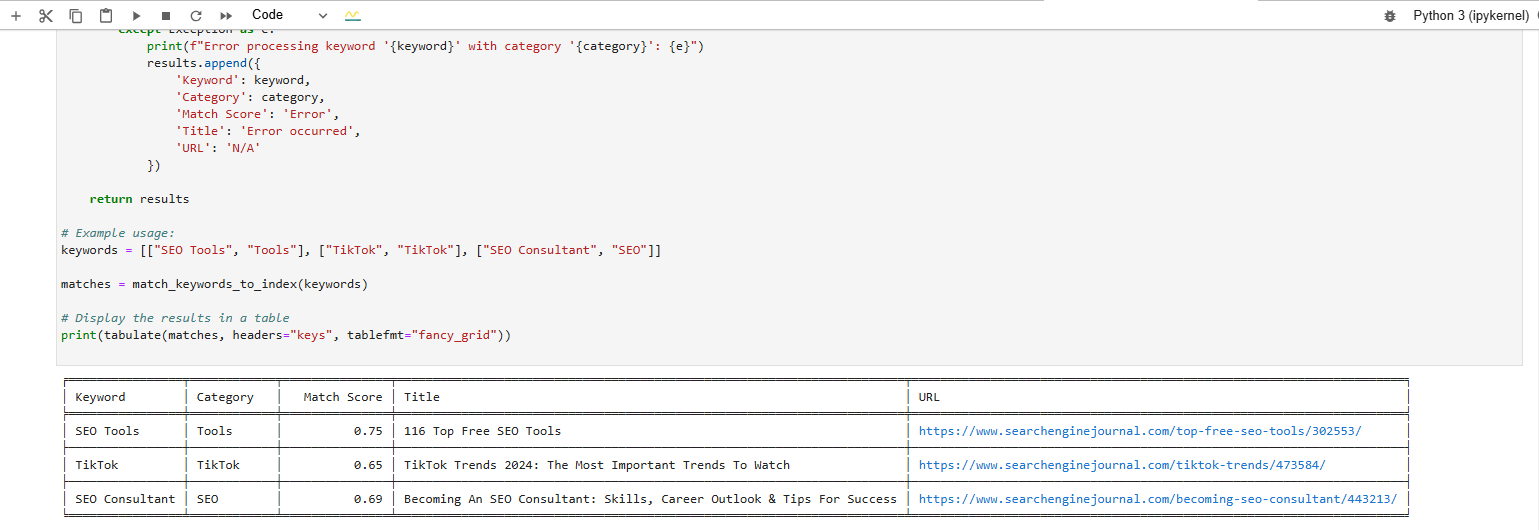
We’re trying to find a lucifer for these keywords:
- SEO Tools.
- TikTok.
- SEO Consultant.
And this is the effect we get aft executing the code:
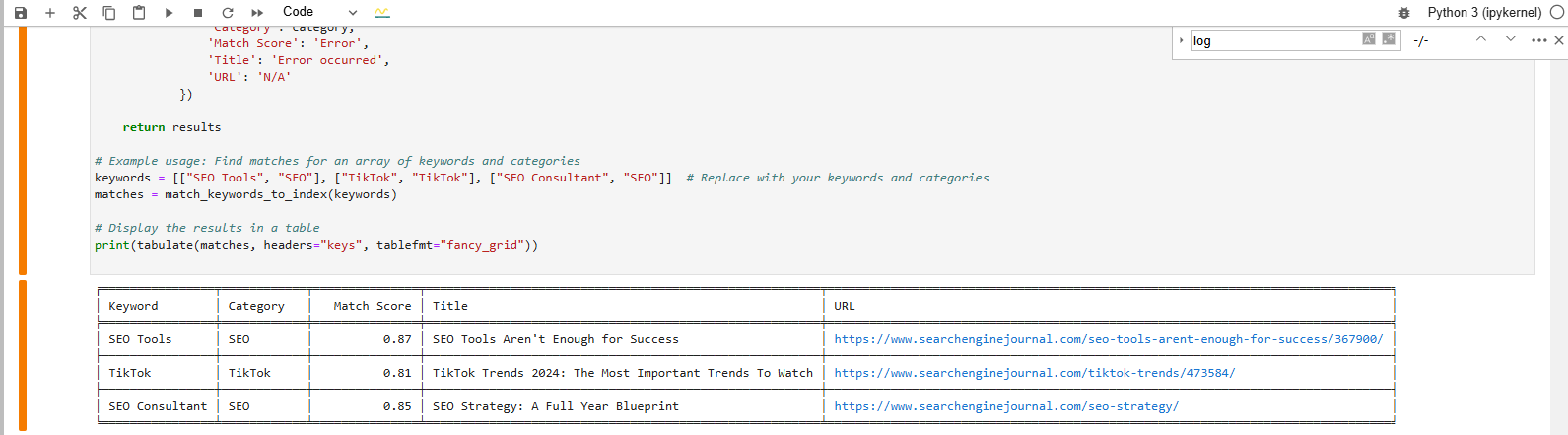 Find a lucifer for the keyword operation from vector database
Find a lucifer for the keyword operation from vector database
The array formatted output astatine the bottommost shows the closest nonfiction matches to our keywords.
4. Inserting Google Vertex AI Text Embeddings Into The Vector Database
Now let’s bash the aforesaid but with Google Vertex AI ‘text-embedding-005’embedding. This exemplary is notable due to the fact that it’s developed by Google, powers Vertex AI Search, and is specifically trained to grip retrieval and query-matching tasks, making it well-suited for our usage case.
You tin adjacent physique an internal hunt widget and adhd it to your website.
Start by signing successful to Google Cloud Console and create a project. Then from the API library find Vertex AI API and alteration it.
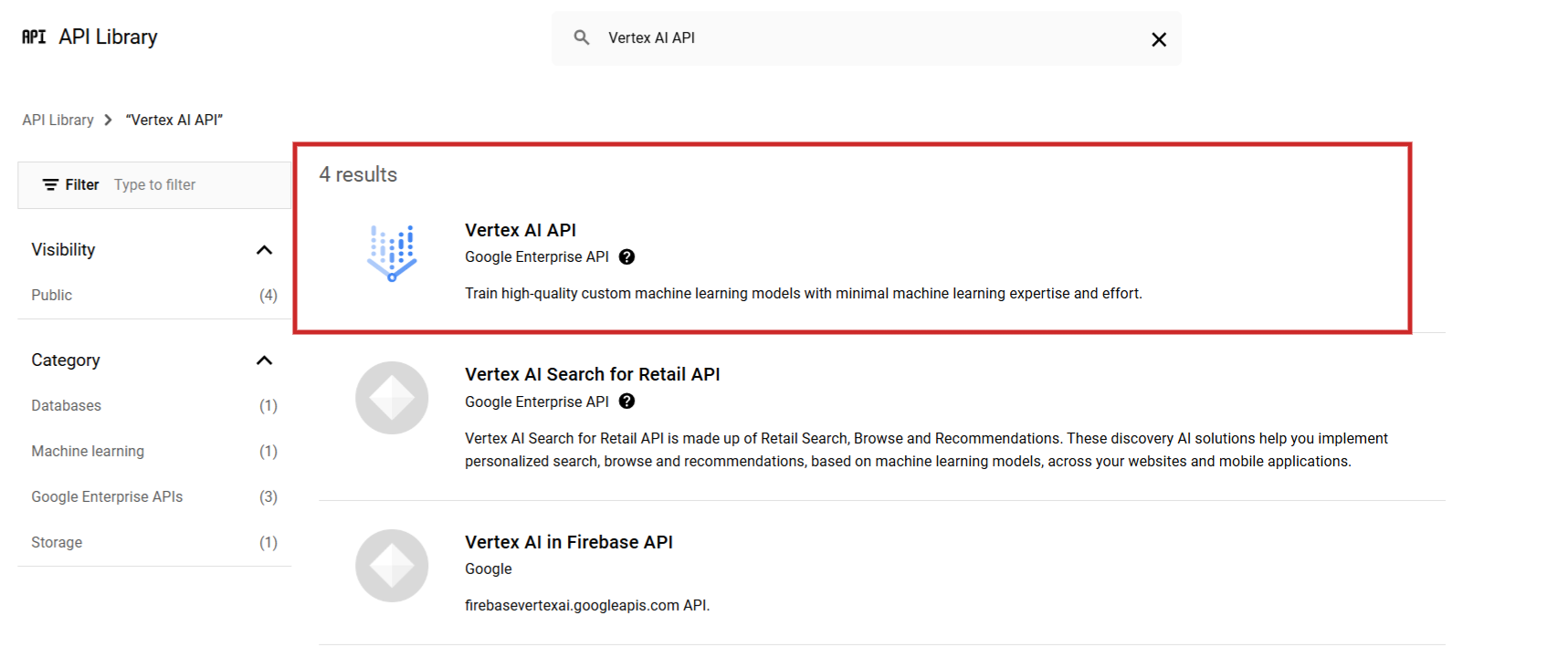 Screenshot from Google Cloud Console, December 2024
Screenshot from Google Cloud Console, December 2024
Set up your billing relationship to beryllium capable to usage Vertex AI arsenic pricing is $0.0002 per 1,000 characters (and it offers $300 credits for caller users).
Once you acceptable it, you request to navigate to API Services > Credentials make a work account, make a key, and download them arsenic JSON.
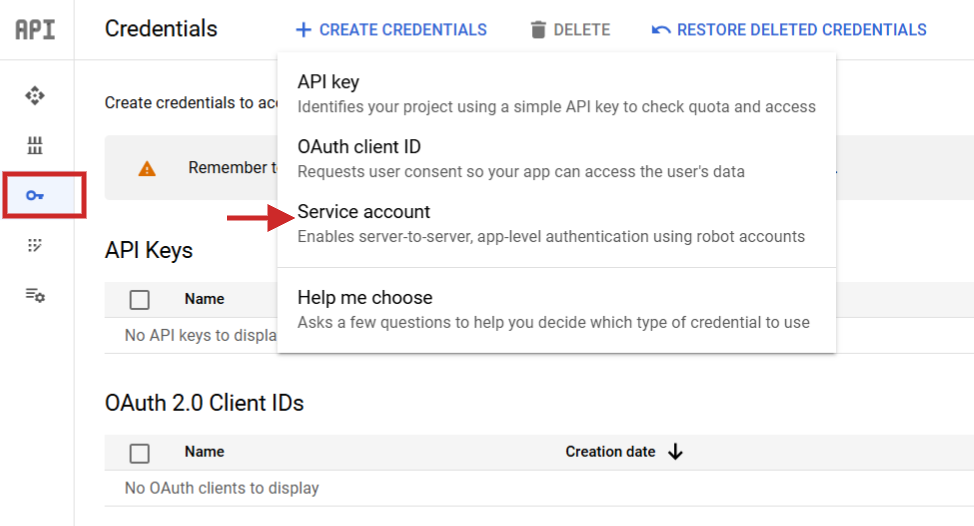
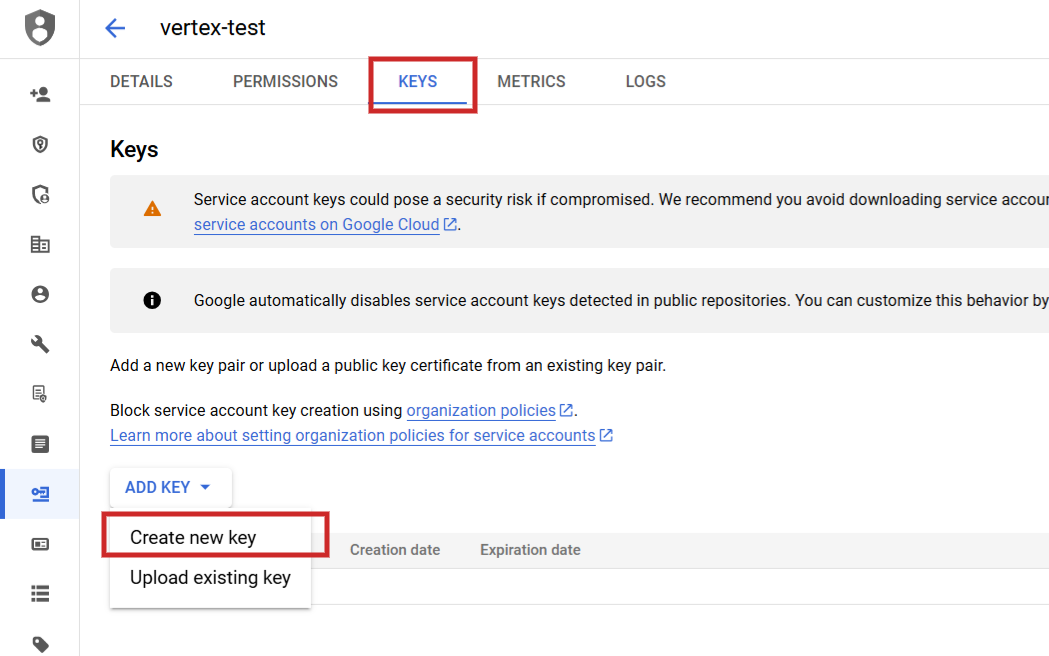

Rename the JSON record to config.json and upload it (via the arrow up icon) to your Jupyter Notebook task folder.
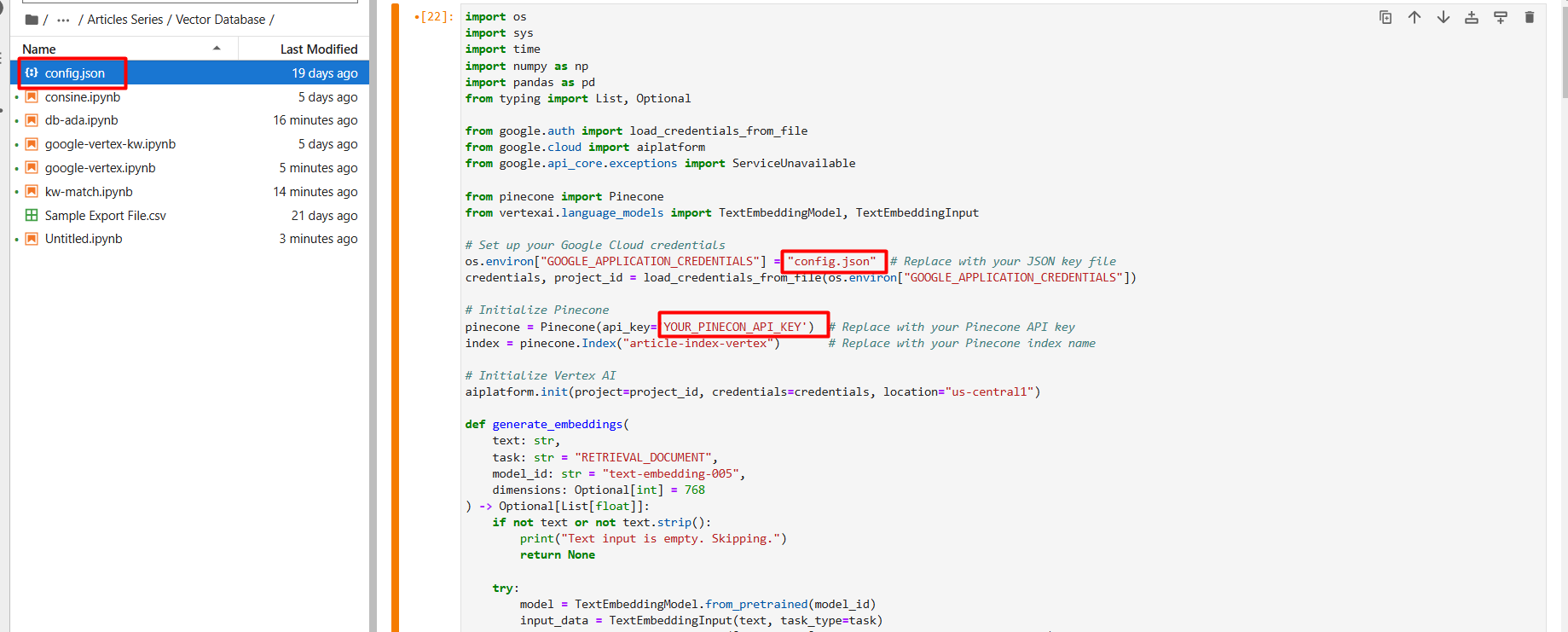 Screenshot from Google Cloud Console, December 2024
Screenshot from Google Cloud Console, December 2024
In the setup archetypal step, make a caller vector database called article-index-vertex by mounting magnitude 768 manually.
Once created you tin tally this publication to commencement generating vector embeddings from the the aforesaid illustration record utilizing Google Vertex AI text-embedding-005 exemplary (you tin take text-multilingual-embedding-002 if you person non-English text).
You volition spot beneath successful logs of created embeddings.
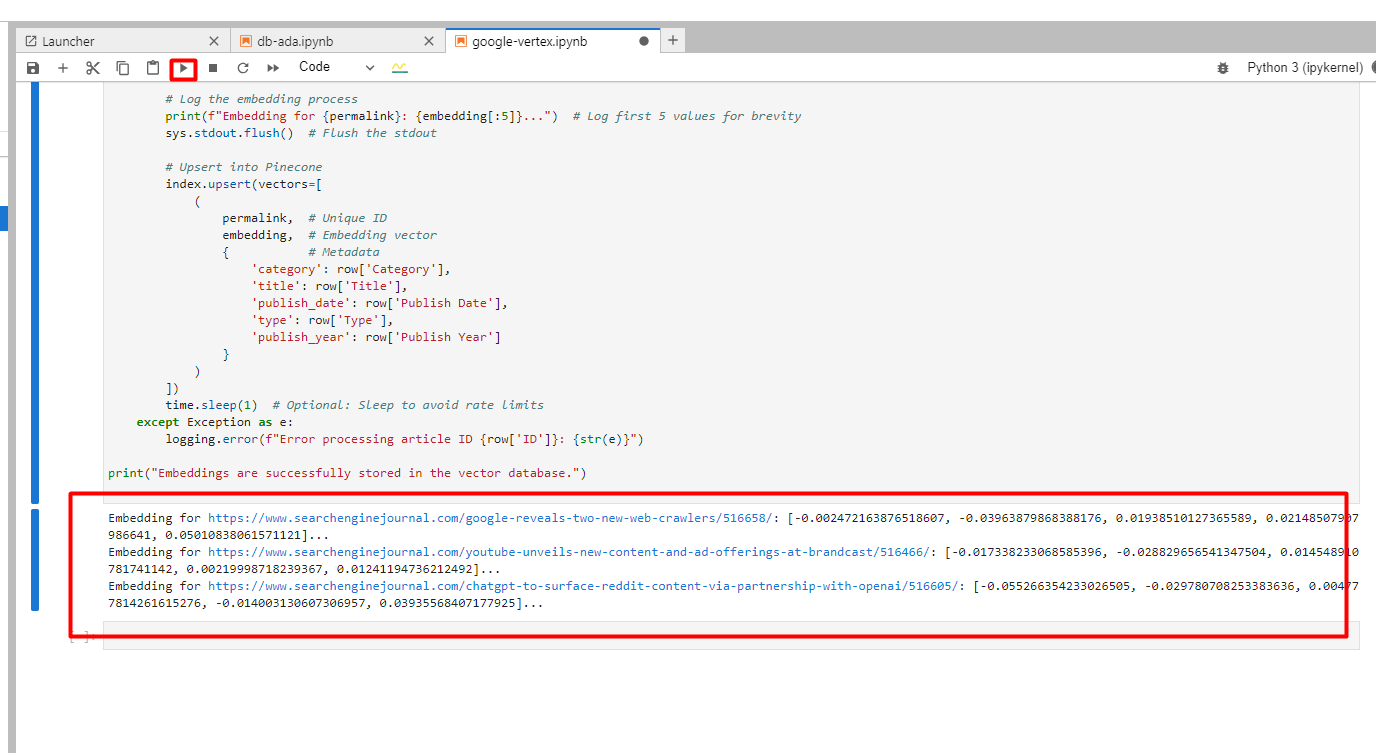 Screenshot from Google Cloud Console, December 2024
Screenshot from Google Cloud Console, December 2024
4. Finding An Article Match For A Keyword Using Google Vertex AI
Now, let’s bash the aforesaid keyword matching with Vertex AI. There is simply a tiny nuance arsenic you request to usage ‘RETRIEVAL_QUERY’ vs. ‘RETRIEVAL_DOCUMENT’ arsenic an statement erstwhile generating embeddings of keywords arsenic we are trying to execute a hunt for an nonfiction (aka document) that champion matches our phrase.
Task types are 1 of the important advantages that Vertex AI has implicit OpenAI’s models.
It ensures that the embeddings seizure the intent of the keywords which is important for interior linking, and improves the relevance and accuracy of the matches recovered successful your vector database.
Use this publication for matching the keywords to vectors.
And you volition spot scores generated:
 Keyword Matche Scores produced by Vertex AI substance embedding model
Keyword Matche Scores produced by Vertex AI substance embedding model
Try Testing The Relevance Of Your Article Writing
Think of this arsenic a simplified (broad) mode to cheque however semantically akin your penning is to the caput keyword. Create a vector embedding of your head keyword and full nonfiction contented via Google’s Vertex AI and cipher a cosine similarity.
If your substance is excessively agelong you whitethorn request to see implementing chunking strategies.
A adjacent people (cosine similarity) to 1.0 (like 0.8 oregon 0.7) means you’re beauteous close connected that subject. If your people is little you whitethorn find that an excessively agelong intro which has a batch of fluff whitethorn beryllium causing dilution of the relevance and cutting it helps to summation it.
But remember, immoderate edits made should marque consciousness from an editorial and idiosyncratic acquisition position arsenic well.
You tin adjacent bash a speedy examination by embedding a competitor’s high-ranking contented and seeing however you stack up.
Doing this helps you to much accurately align your contented with the people subject, which whitethorn assistance you fertile better.
There are already tools that perform specified tasks, but learning these skills means you tin instrumentality a customized attack tailored to your needs—and, of course, to bash it for free.
Experimenting for yourself and learning these skills volition assistance you to support up with AI SEO and to make informed decisions.
As further readings, I urge you dive into these large articles:
- GraphRAG 2.0 Improves AI Search Results
- Introducing SEOntology: The Future Of SEO In The Age Of AI
- Unlocking The Power Of LLM And Knowledge Graph (An Introduction)
More resources:
- AI Has Changed How Search Works
- AI For SEO: Can You Work Faster & Smarter?
- Leveraging Generative AI Tools For SEO
Featured Image: Aozorastock/Shutterstock

![Win Higher-Quality Links: The PR Approach To SEO Success [Webinar] via @sejournal, @lorenbaker](https://www.searchenginejournal.com/wp-content/uploads/2025/03/featured-1-716.png)





 English (US)
English (US)