ARTICLE AD BOX
This caller bid of articles focuses connected moving with LLMs to standard your SEO tasks. We anticipation to assistance you integrate AI into SEO truthful you tin level up your skills.
We anticipation you enjoyed the previous article and recognize what vectors, vector distance, and text embeddings are.
Following this, it’s clip to flex your “AI cognition muscles” by learning however to usage substance embeddings to find keyword cannibalization.
We volition commencement with OpenAI’s substance embeddings and comparison them.
| text-embedding-ada-002 | 1536 | $0.10 per 1M tokens | Great for astir usage cases. |
| text-embedding-3-small | 1536 | $0.002 per 1M tokens | Faster and cheaper but little accurate |
| text-embedding-3-large | 3072 | $0.13 per 1M tokens | More close for analyzable agelong text-related tasks, slower |
(*tokens tin beryllium considered arsenic words words.)
But earlier we start, you request to instal Python and Jupyter connected your computer.
Jupyter is simply a web-based instrumentality for professionals and researchers. It allows you to execute analyzable information investigation and instrumentality learning exemplary improvement utilizing immoderate programming language.
Don’t interest – it’s truly casual and takes small clip to decorativeness the installations. And remember, ChatGPT is your friend erstwhile it comes to programming.
In a nutshell:
- Download and install Python.
- Open your Windows bid enactment oregon terminal connected Mac.
- Type this commands pip instal jupyterlab and pip instal notebook
- Run Jupiter by this command: jupyter lab
We volition usage Jupyter to experimentation with substance embeddings; you’ll spot however amusive it is to enactment with!
But earlier we start, you indispensable motion up for OpenAI’s API and acceptable up billing by filling your balance.
 Open AI Api Billing settings
Open AI Api Billing settings
Once you’ve done that, acceptable up email notifications to pass you erstwhile your spending exceeds a definite magnitude nether Usage limits.
Then, get API keys nether Dashboard > API keys, which you should support backstage and ne'er stock publicly.
 OpenAI API keys
OpenAI API keys
Now, you person each the indispensable tools to commencement playing with embeddings.
- Open your machine bid terminal and benignant jupyter lab.
- You should spot thing similar the beneath representation popular up successful your browser.
- Click connected Python 3 nether Notebook.
 jupyter lab
jupyter lab
In the opened window, you volition constitute your code.
As a tiny task, let’s radical akin URLs from a CSV. The sample CSV has 2 columns: URL and Title. Our script’s task volition beryllium to radical URLs with akin semantic meanings based connected the rubric truthful we tin consolidate those pages into 1 and hole keyword cannibalization issues.
Here are the steps you request to do:
Install required Python libraries with the pursuing commands successful your PC’s terminal (or successful Jupyter notebook)
The ‘openai’ room is required to interact with the OpenAI API to get embeddings, and ‘pandas’ is utilized for information manipulation and handling CSV record operations.
The ‘scikit-learn’ room is indispensable for calculating cosine similarity, and ‘numpy’ is indispensable for numerical operations and handling arrays. Lastly, unidecode is utilized to cleanable text.
Then, download the sample expanse arsenic a CSV, rename the record to pages.csv, and upload it to your Jupyter folder wherever your publication is located.
Set your OpenAI API cardinal to the cardinal you obtained successful the measurement above, and copy-paste the codification beneath into the notebook.
Run the codification by clicking the play triangle icon astatine the apical of the notebook.
This codification reads a CSV file, ‘pages.csv,’ containing titles and URLs, which you tin easy export from your CMS oregon get by crawling a lawsuit website utilizing Screaming Frog.
Then, it cleans the titles from non-UTF characters, generates embedding vectors for each rubric utilizing OpenAI’s API, calculates the similarity betwixt the titles, groups akin titles together, and writes the grouped results to a caller CSV file, ‘grouped_pages.csv.’
In the keyword cannibalization task, we usage a similarity threshold of 0.9, which means if cosine similarity is little than 0.9, we volition see articles arsenic different. To visualize this successful a simplified two-dimensional space, it volition look arsenic 2 vectors with an space of astir 25 degrees betwixt them.
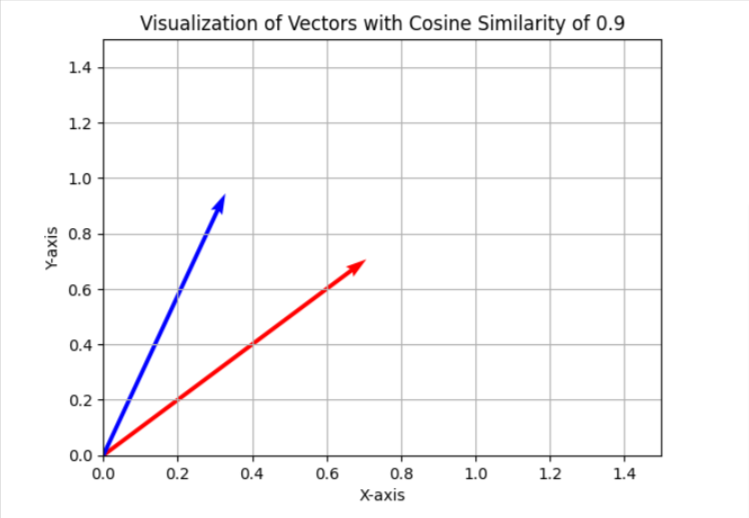
In your case, you whitethorn privation to usage a antithetic threshold, similar 0.85 (approximately 31 degrees betwixt them), and tally it connected a illustration of your information to measure the results and the wide prime of matches. If it is unsatisfactory, you tin summation the threshold to marque it much strict for amended precision.
You tin instal ‘matplotlib’ via terminal.
And usage the Python codification beneath successful a abstracted Jupyter notebook to visualize cosine similarities successful two-dimensional abstraction connected your own. Try it; it’s fun!
I usually usage 0.9 and higher for identifying keyword cannibalization issues, but you whitethorn request to acceptable it to 0.5 erstwhile dealing with aged nonfiction redirects, arsenic aged articles whitethorn not person astir identical articles that are fresher but partially close.
It whitethorn besides beryllium amended to person the meta statement concatenated with the rubric successful lawsuit of redirects, successful summation to the title.
So, it depends connected the task you are performing. We volition reappraisal however to instrumentality redirects successful a abstracted nonfiction aboriginal successful this series.
Now, let’s reappraisal the results with the 3 models mentioned supra and spot however they were capable to place adjacent articles from our information illustration from Search Engine Journal’s articles.
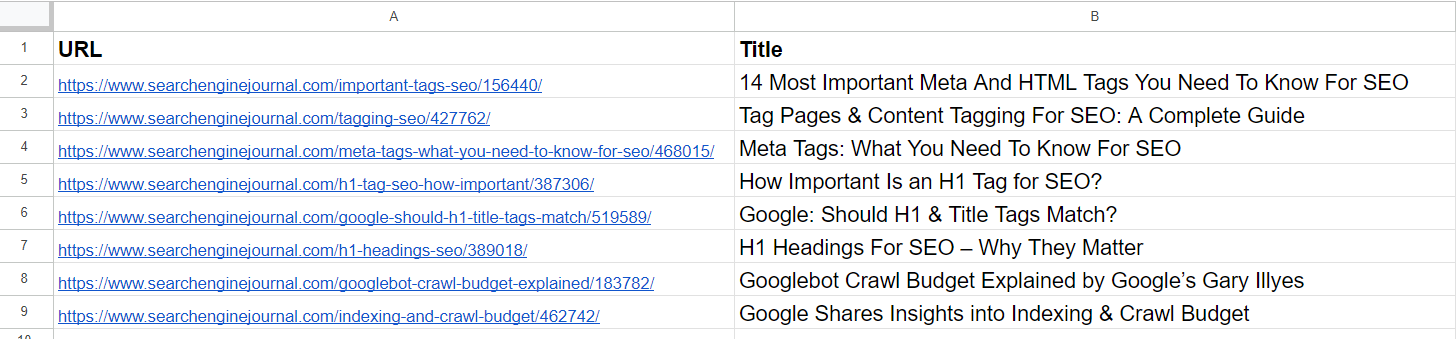 Data Sample
Data Sample
From the list, we already spot that the 2nd and 4th articles screen the aforesaid taxable connected ‘meta tags.’ The articles successful the 5th and 7th rows are beauteous overmuch the aforesaid – discussing the value of H1 tags successful SEO – and tin beryllium merged.
The nonfiction successful the 3rd enactment doesn’t person immoderate similarities with immoderate of the articles successful the database but has communal words similar “Tag” oregon “SEO.”
The nonfiction successful the 6th enactment is again astir H1, but not precisely the aforesaid arsenic H1’s value to SEO. Instead, it represents Google’s sentiment connected whether they should match.
Articles connected the 8th and 9th rows are rather adjacent but inactive different; they tin beryllium combined.
text-embedding-ada-002
By utilizing ‘text-embedding-ada-002,’ we precisely recovered the 2nd and 4th articles with a cosine similarity of 0.92 and the 5th and 7th articles with a similarity of 0.91.
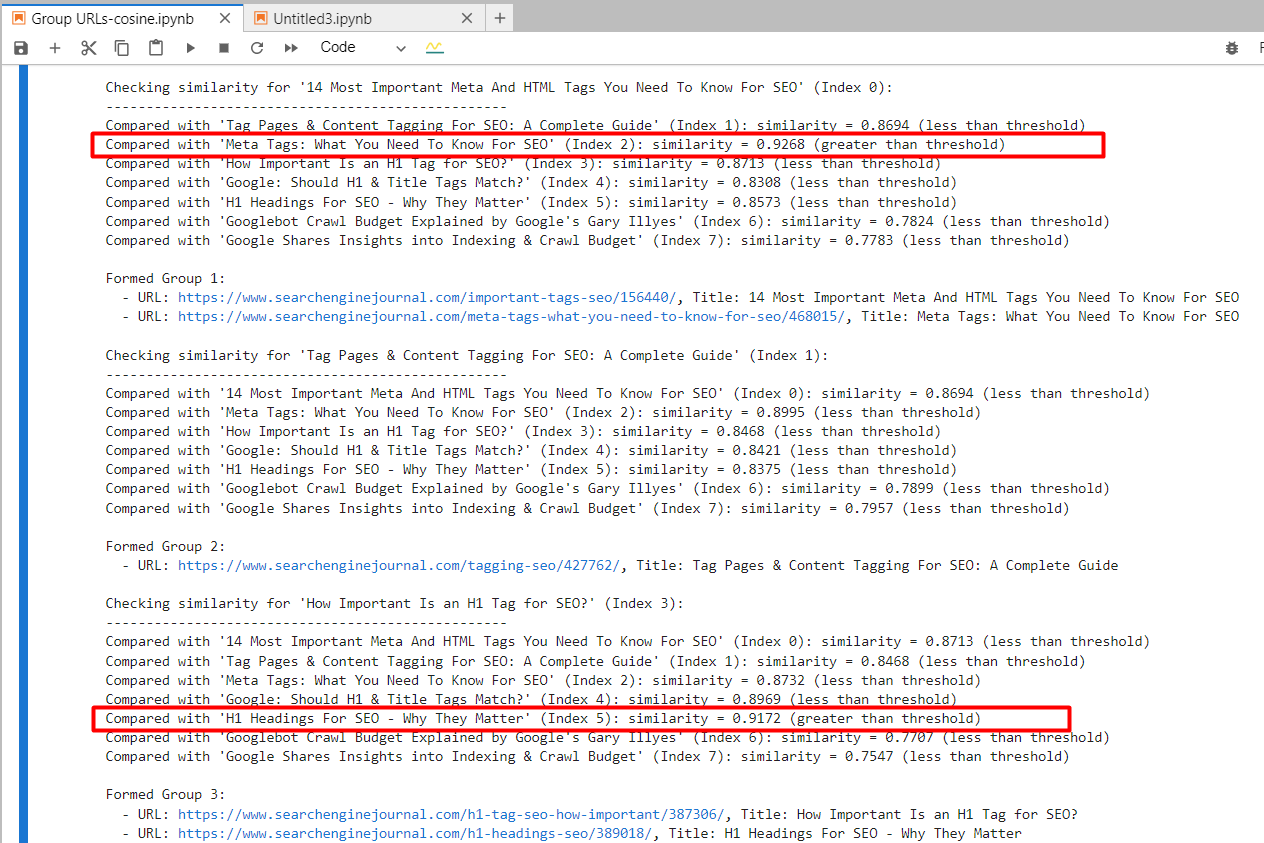 Screenshot from Jupyter log showing cosine similarities
Screenshot from Jupyter log showing cosine similarities
And it generated output with grouped URLs by utilizing the aforesaid radical fig for akin articles. (colors are applied manually for visualization purposes).
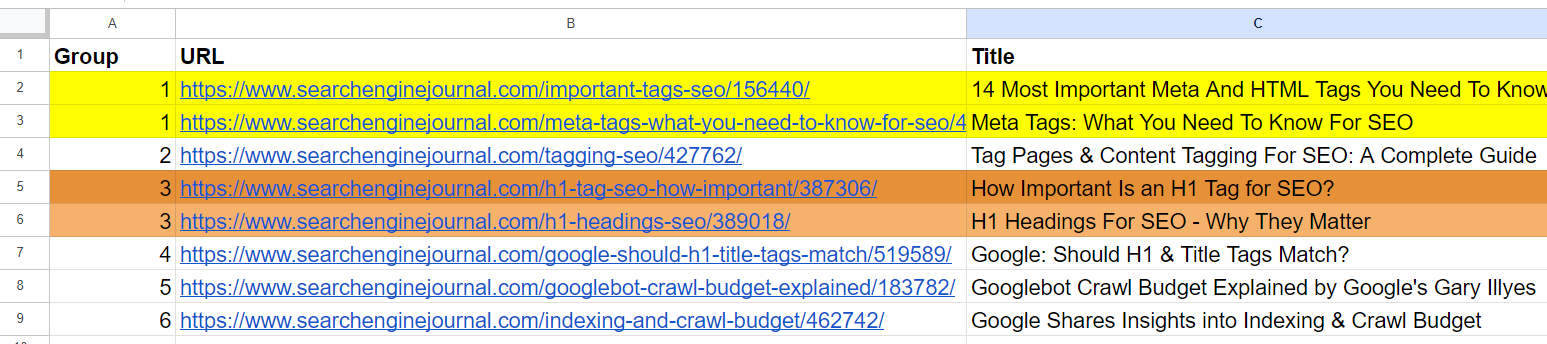 Output expanse with grouped URLs
Output expanse with grouped URLs
For the 2nd and 3rd articles, which person communal words “Tag” and “SEO” but are unrelated, the cosine similarity was 0.86. This shows wherefore a precocious similarity threshold of 0.9 oregon greater is necessary. If we acceptable it to 0.85, it would beryllium afloat of mendacious positives and could suggest merging unrelated articles.
text-embedding-3-small
By utilizing ‘text-embedding-3-small,’ rather surprisingly, it didn’t find immoderate matches per our similarity threshold of 0.9 oregon higher.
For the 2nd and 4th articles, cosine similarity was 0.76, and for the 5th and 7th articles, with similarity 0.77.
To amended recognize this exemplary done experimentation, I’ve added a somewhat modified mentation of the 1st enactment with ’15’ vs. ’14’ to the sample.
- “14 Most Important Meta And HTML Tags You Need To Know For SEO”
- “15 Most Important Meta And HTML Tags You Need To Know For SEO”
 An illustration which shows text-embedding-3-small results
An illustration which shows text-embedding-3-small results
On the contrary, ‘text-embedding-ada-002’ gave 0.98 cosine similarity betwixt those versions.
| Title 1 | Title 2 | Cosine Similarity |
| 14 Most Important Meta And HTML Tags You Need To Know For SEO | 15 Most Important Meta And HTML Tags You Need To Know For SEO | 0.92 |
| 14 Most Important Meta And HTML Tags You Need To Know For SEO | Meta Tags: What You Need To Know For SEO | 0.76 |
Here, we spot that this exemplary is not rather a bully acceptable for comparing titles.
text-embedding-3-large
This model’s dimensionality is 3072, which is 2 times higher than that of ‘text-embedding-3-small’ and ‘text-embedding-ada-002′, with 1536 dimensionality.
As it has much dimensions than the different models, we could expect it to seizure semantic meaning with higher precision.
However, it gave the 2nd and 4th articles cosine similarity of 0.70 and the 5th and 7th articles similarity of 0.75.
I’ve tested it again with somewhat modified versions of the archetypal nonfiction with ’15’ vs. ’14’ and without ‘Most Important’ successful the title.
- “14 Most Important Meta And HTML Tags You Need To Know For SEO”
- “15 Most Important Meta And HTML Tags You Need To Know For SEO”
- “14 Meta And HTML Tags You Need To Know For SEO”
| Title 1 | Title 2 | Cosine Similarity |
| 14 Most Important Meta And HTML Tags You Need To Know For SEO | 15 Most Important Meta And HTML Tags You Need To Know For SEO | 0.95 |
| 14 Most Important Meta And HTML Tags You Need To Know For SEO | 14 Most Important Meta And HTML Tags You Need To Know For SEO | 0.93 |
| 14 Most Important Meta And HTML Tags You Need To Know For SEO | Meta Tags: What You Need To Know For SEO | 0.70 |
| 15 Most Important Meta And HTML Tags You Need To Know For SEO | 14 Most Important Meta And HTML Tags You Need To Know For SEO | 0.86 |
So we tin spot that ‘text-embedding-3-large’ is underperforming compared to ‘text-embedding-ada-002’ erstwhile we cipher cosine similarities betwixt titles.
I privation to enactment that the accuracy of ‘text-embedding-3-large’ increases with the magnitude of the text, but ‘text-embedding-ada-002’ inactive performs amended overall.
Another attack could beryllium to portion distant halt words from the text. Removing these tin sometimes assistance absorption the embeddings connected much meaningful words, perchance improving the accuracy of tasks similar similarity calculations.
The champion mode to find whether removing halt words improves accuracy for your circumstantial task and dataset is to empirically trial some approaches and comparison the results.
Conclusion
With these examples, you person learned however to enactment with OpenAI’s embedding models and tin already execute a wide scope of tasks.
For similarity thresholds, you request to experimentation with your ain datasets and spot which thresholds marque consciousness for your circumstantial task by moving it connected smaller samples of information and performing a quality reappraisal of the output.
Please enactment that the codification we person successful this nonfiction is not optimal for ample datasets since you request to make substance embeddings of articles each clip determination is simply a alteration successful your dataset to measure against different rows.
To marque it efficient, we indispensable usage vector databases and store embedding accusation determination erstwhile generated. We volition screen however to usage vector databases precise soon and alteration the codification illustration present to usage a vector database.
More resources:
- Avoiding Keyword Cannibalization Between Your Paid and Organic Search Campaigns
- How Do I Stop Keyword Cannibalization When My Products Are All Similar?
- Leveraging Generative AI Tools For SEO
Featured Image: BestForBest/Shutterstock

![Win Higher-Quality Links: The PR Approach To SEO Success [Webinar] via @sejournal, @lorenbaker](https://www.searchenginejournal.com/wp-content/uploads/2025/03/featured-1-716.png)





 English (US)
English (US)