ARTICLE AD BOX
Understanding however to usage the robots.txt record is important for immoderate website’s SEO strategy. Mistakes successful this file tin interaction however your website is crawled and your pages’ hunt appearance. Getting it right, connected the different hand, tin amended crawling ratio and mitigate crawling issues.
Google recently reminded website owners astir the value of utilizing robots.txt to artifact unnecessary URLs.
Those see add-to-cart, login, oregon checkout pages. But the question is – however bash you usage it properly?
In this article, we volition usher you into each nuance of however to bash conscionable so.
What Is Robots.txt?
The robots.txt is simply a elemental substance record that sits successful the basal directory of your tract and tells crawlers what should beryllium crawled.
The array beneath provides a speedy notation to the cardinal robots.txt directives.
| Directive | Description |
| User-agent | Specifies which crawler the rules use to. See user cause tokens. Using * targets each crawlers. |
| Disallow | Prevents specified URLs from being crawled. |
| Allow | Allows circumstantial URLs to beryllium crawled, adjacent if a genitor directory is disallowed. |
| Sitemap | Indicates the determination of your XML Sitemap by helping hunt engines to observe it. |
This is an illustration of robot.txt from ikea.com with aggregate rules.
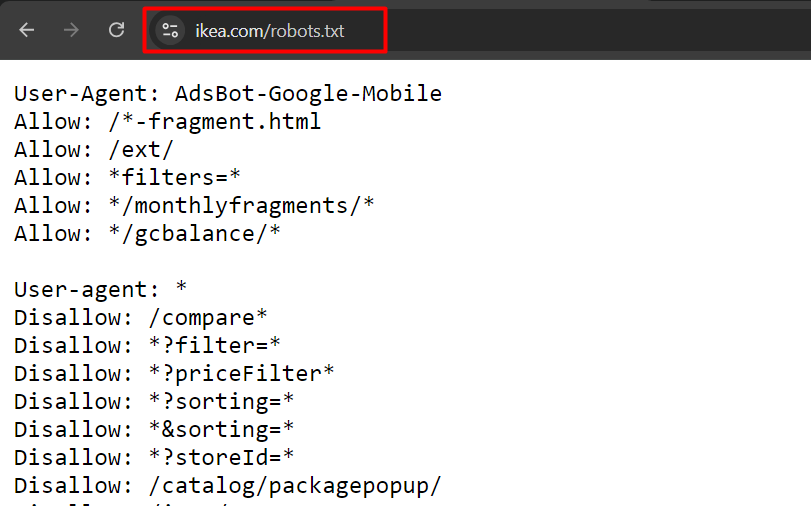 Example of robots.txt from ikea.com
Example of robots.txt from ikea.com
Note that robots.txt doesn’t enactment afloat regular expressions and lone has 2 wildcards:
- Asterisks (*), which matches 0 oregon much sequences of characters.
- Dollar motion ($), which matches the extremity of a URL.
Also, enactment that its rules are case-sensitive, e.g., “filter=” isn’t adjacent to “Filter=.”
Order Of Precedence In Robots.txt
When mounting up a robots.txt file, it’s important to cognize the bid successful which hunt engines determine which rules to use successful lawsuit of conflicting rules.
They travel these 2 cardinal rules:
1. Most Specific Rule
The regularisation that matches much characters successful the URL volition beryllium applied. For example:
In this case, the “Allow: /downloads/free/” regularisation is much circumstantial than “Disallow: /downloads/” due to the fact that it targets a subdirectory.
Google volition let crawling of subfolder “/downloads/free/” but artifact everything other nether “/downloads/.”
2. Least Restrictive Rule
When aggregate rules are arsenic specific, for example:
Google volition take the slightest restrictive one. This means Google volition let entree to /downloads/.
Why Is Robots.txt Important In SEO?
Blocking unimportant pages with robots.txt helps Googlebot focus its crawl budget connected invaluable parts of the website and connected crawling caller pages. It besides helps hunt engines prevention computing power, contributing to amended sustainability.
Imagine you person an online store with hundreds of thousands of pages. There are sections of websites similar filtered pages that whitethorn person an infinite fig of versions.
Those pages don’t person unsocial value, fundamentally incorporate duplicate content, and whitethorn make infinite crawl space, frankincense wasting your server and Googlebot’s resources.
That is wherever robots.txt comes in, preventing hunt motor bots from crawling those pages.
If you don’t bash that, Google whitethorn effort to crawl an infinite fig of URLs with antithetic (even non-existent) hunt parameter values, causing spikes and a waste of crawl budget.
When To Use Robots.txt
As a wide rule, you should ever inquire wherefore definite pages exist, and whether they person thing worthy for hunt engines to crawl and index.
If we travel from this principle, certainly, we should ever block:
- URLs that incorporate query parameters specified as:
- Internal search.
- Faceted navigation URLs created by filtering oregon sorting options if they are not portion of URL operation and SEO strategy.
- Action URLs similar adhd to wishlist oregon adhd to cart.
- Private parts of the website, similar login pages.
- JavaScript files not applicable to website contented oregon rendering, specified arsenic tracking scripts.
- Blocking scrapers and AI chatbots to forestall them from utilizing your contented for their grooming purposes.
Let’s dive into however you tin usage robots.txt for each case.
1. Block Internal Search Pages
The astir communal and perfectly indispensable measurement is to artifact interior hunt URLs from being crawled by Google and other hunt engines, arsenic astir each website has an interior hunt functionality.
On WordPress websites, it is usually an “s” parameter, and the URL looks similar this:
Gary Illyes from Google has repeatedly warned to artifact “action” URLs arsenic they tin origin Googlebot to crawl them indefinitely adjacent non-existent URLs with antithetic combinations.
Here is the regularisation you tin usage successful your robots.txt to artifact specified URLs from being crawled:
- The User-agent: * line specifies that the regularisation applies to each web crawlers, including Googlebot, Bingbot, etc.
- The Disallow: *s=* enactment tells each crawlers not to crawl immoderate URLs that incorporate the query parameter “s=.” The wildcard “*” means it tin lucifer immoderate series of characters earlier oregon aft “s= .” However, it volition not lucifer URLs with uppercase “S” similar “/?S=” since it is case-sensitive.
Here is an illustration of a website that managed to drastically trim the crawling of non-existent interior hunt URLs aft blocking them via robots.txt.
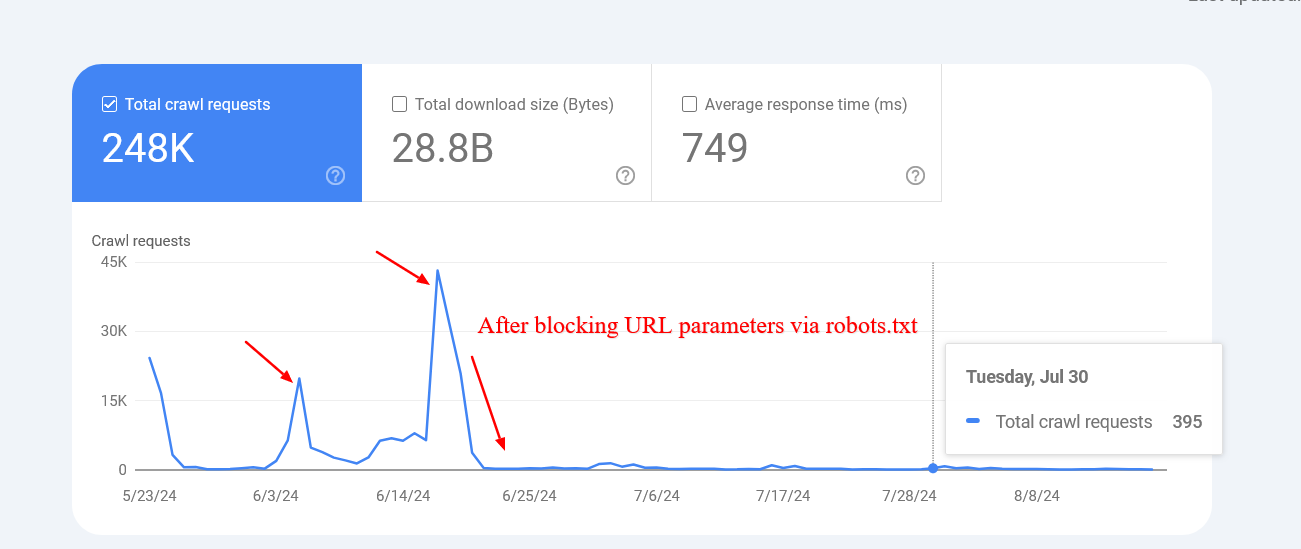 Screenshot from crawl stats report
Screenshot from crawl stats report
Note that Google whitethorn index those blocked pages, but you don’t request to interest astir them arsenic they volition beryllium dropped implicit time.
2. Block Faceted Navigation URLs
Faceted navigation is an integral portion of each ecommerce website. There tin beryllium cases wherever faceted navigation is portion of an SEO strategy and aimed astatine ranking for wide merchandise searches.
For example, Zalando uses faceted navigation URLs for colour options to fertile for wide merchandise keywords similar “gray t-shirt.”
However, successful astir cases, this is not the case, and filter parameters are utilized simply for filtering products, creating dozens of pages with duplicate content.
Technically, those parameters are not antithetic from interior hunt parameters with 1 quality arsenic determination whitethorn beryllium aggregate parameters. You request to marque definite you disallow each of them.
For example, if you person filters with the pursuing parameters “sortby,” “color,” and “price,” you whitethorn usage this acceptable of rules:
Based connected your circumstantial case, determination whitethorn beryllium much parameters, and you whitethorn request to adhd each of them.
What About UTM Parameters?
UTM parameters are utilized for tracking purposes.
As John Mueller stated in his Reddit post, you don’t request to interest astir URL parameters that nexus to your pages externally.
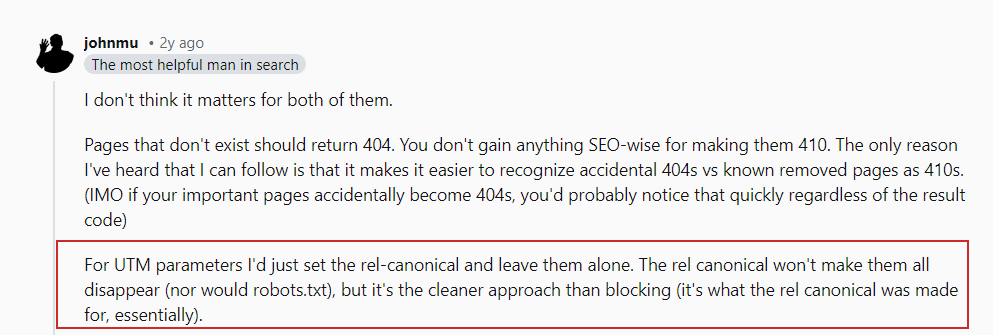 John Mueller connected UTM parameters
John Mueller connected UTM parameters
Just marque definite to artifact immoderate random parameters you usage internally and debar linking internally to those pages, e.g., linking from your nonfiction pages to your hunt leafage with a hunt query leafage “https://www.example.com/?s=google.”
3. Block PDF URLs
Let’s accidental you person a batch of PDF documents, specified arsenic merchandise guides, brochures, oregon downloadable papers, and you don’t privation them crawled.
Here is simply a elemental robots.txt regularisation that volition artifact hunt motor bots from accessing those documents:
The “Disallow: /*.pdf$” enactment tells crawlers not to crawl immoderate URLs that extremity with .pdf.
By utilizing /*, the regularisation matches immoderate way connected the website. As a result, immoderate URL ending with .pdf volition beryllium blocked from crawling.
If you person a WordPress website and privation to disallow PDFs from the uploads directory wherever you upload them via the CMS, you tin usage the pursuing rule:
You tin spot that we person conflicting rules here.
In lawsuit of conflicting rules, the more specific 1 takes priority, which means the past enactment ensures that lone the circumstantial record located successful folder “wp-content/uploads/2024/09/allowed-document.pdf” is allowed to beryllium crawled.
4. Block A Directory
Let’s accidental you person an API endpoint wherever you taxable your information from the form. It is apt your signifier has an enactment property similar action=”/form/submissions/.”
The contented is that Google volition effort to crawl that URL, /form/submissions/, which you apt don’t want. You tin artifact these URLs from being crawled with this rule:
By specifying a directory successful the Disallow rule, you are telling the crawlers to debar crawling each pages nether that directory, and you don’t request to usage the (*) wildcard anymore, similar “/form/*.”
Note that you indispensable ever specify comparative paths and ne'er implicit URLs, similar “https://www.example.com/form/” for Disallow and Allow directives.
Be cautious to debar malformed rules. For example, utilizing /form without a trailing slash volition besides lucifer a leafage /form-design-examples/, which whitethorn beryllium a leafage connected your blog that you privation to index.
Read: 8 Common Robots.txt Issues And How To Fix Them
5. Block User Account URLs
If you person an ecommerce website, you apt person directories that commencement with “/myaccount/,” specified arsenic “/myaccount/orders/” oregon “/myaccount/profile/.”
With the apical leafage “/myaccount/” being a sign-in leafage that you privation to beryllium indexed and recovered by users successful search, you whitethorn privation to disallow the subpages from being crawled by Googlebot.
You tin usage the Disallow regularisation successful operation with the Allow regularisation to artifact everything nether the “/myaccount/” directory (except the /myaccount/ page).
And again, since Google uses the astir circumstantial rule, it volition disallow everything nether the /myaccount/ directory but let lone the /myaccount/ leafage to beryllium crawled.
Here’s different usage lawsuit of combining the Disallow and Allow rules: successful lawsuit you person your hunt nether the /search/ directory and privation it to beryllium recovered and indexed but artifact existent hunt URLs:
6. Block Non-Render Related JavaScript Files
Every website uses JavaScript, and galore of these scripts are not related to the rendering of content, specified arsenic tracking scripts oregon those utilized for loading AdSense.
Googlebot tin crawl and render a website’s contented without these scripts. Therefore, blocking them is harmless and recommended, arsenic it saves requests and resources to fetch and parse them.
Below is simply a illustration enactment that is disallowing illustration JavaScript, which contains tracking pixels.
7. Block AI Chatbots And Scrapers
Many publishers are acrophobic that their contented is being unfairly utilized to bid AI models without their consent, and they privation to forestall this.
Here, each idiosyncratic cause is listed individually, and the regularisation Disallow: / tells those bots not to crawl immoderate portion of the site.
This, too preventing AI grooming connected your content, tin assistance trim the load connected your server by minimizing unnecessary crawling.
For ideas connected which bots to block, you whitethorn privation to cheque your server log files to spot which crawlers are exhausting your servers, and remember, robots.txt doesn’t prevent unauthorized access.
8. Specify Sitemaps URLs
Including your sitemap URL successful the robots.txt record helps hunt engines easy observe each the important pages connected your website. This is done by adding a circumstantial enactment that points to your sitemap location, and you tin specify aggregate sitemaps, each connected its ain line.
Unlike Allow oregon Disallow rules, which let lone a comparative path, the Sitemap directive requires a full, implicit URL to bespeak the determination of the sitemap.
Ensure the sitemaps’ URLs are accessible to hunt engines and person due syntax to debar errors.
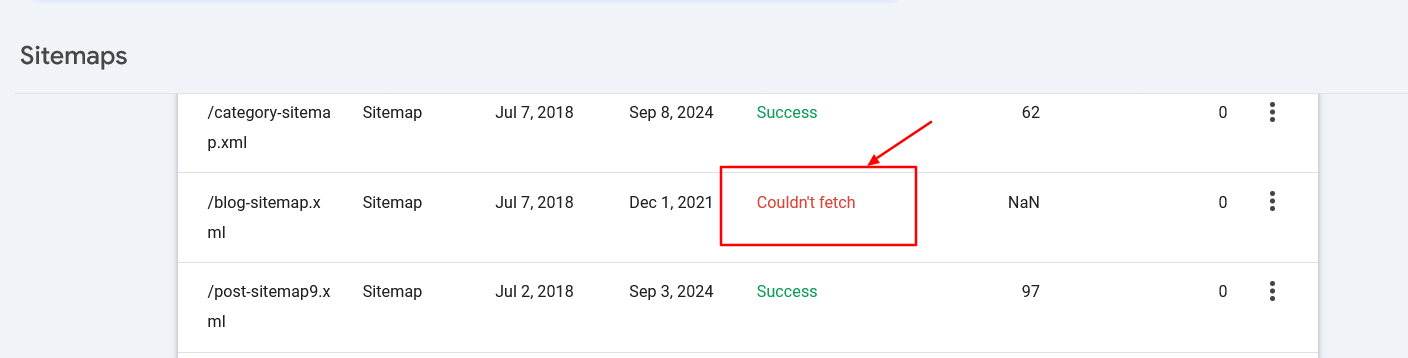 Sitemap fetch mistake successful hunt console
Sitemap fetch mistake successful hunt console
9. When To Use Crawl-Delay
The crawl-delay directive successful robots.txt specifies the fig of seconds a bot should hold earlier crawling the adjacent page. While Googlebot does not admit the crawl-delay directive, different bots whitethorn respect it.
It helps forestall server overload by controlling however often bots crawl your site.
For example, if you privation ClaudeBot to crawl your contented for AI grooming but privation to debar server overload, you tin acceptable a crawl hold to negociate the interval betwixt requests.
This instructs the ClaudeBot idiosyncratic cause to hold 60 seconds betwixt requests erstwhile crawling the website.
Of course, determination whitethorn beryllium AI bots that don’t respect crawl hold directives. In that case, you whitethorn request to usage a web firewall to complaint bounds them.
Troubleshooting Robots.txt
Once you’ve composed your robots.txt, you tin usage these tools to troubleshoot if the syntax is close oregon if you didn’t accidentally artifact an important URL.
1. Google Search Console Robots.txt Validator
Once you’ve updated your robots.txt, you indispensable cheque whether it contains immoderate mistake oregon accidentally blocks URLs you privation to beryllium crawled, specified arsenic resources, images, oregon website sections.
Navigate Settings > robots.txt, and you volition find the built-in robots.txt validator. Below is the video of however to fetch and validate your robots.txt.
2. Google Robots.txt Parser
This parser is authoritative Google’s robots.txt parser which is utilized successful Search Console.
It requires precocious skills to instal and tally connected your section computer. But it is highly recommended to instrumentality clip and bash it arsenic instructed connected that leafage due to the fact that you tin validate your changes successful the robots.txt record earlier uploading to your server successful enactment with the authoritative Google parser.
Centralized Robots.txt Management
Each domain and subdomain indispensable person its ain robots.txt, arsenic Googlebot doesn’t admit basal domain robots.txt for a subdomain.
It creates challenges erstwhile you person a website with a twelve subdomains, arsenic it means you should support a clump of robots.txt files separately.
However, it is imaginable to big a robots.txt record connected a subdomain, specified arsenic https://cdn.example.com/robots.txt, and acceptable up a redirect from https://www.example.com/robots.txt to it.
You tin bash vice versa and big it lone nether the basal domain and redirect from subdomains to the root.
Search engines volition dainty the redirected record arsenic if it were located connected the basal domain. This attack allows centralized absorption of robots.txt rules for some your main domain and subdomains.
It helps marque updates and attraction much efficient. Otherwise, you would request to usage a abstracted robots.txt record for each subdomain.
Conclusion
A decently optimized robots.txt record is important for managing a website’s crawl budget. It ensures that hunt engines similar Googlebot walk their clip connected invaluable pages alternatively than wasting resources connected unnecessary ones.
On the different hand, blocking AI bots and scrapers utilizing robots.txt tin importantly trim server load and prevention computing resources.
Make definite you ever validate your changes to debar unexpected crawability issues.
However, retrieve that portion blocking unimportant resources via robots.txt whitethorn assistance summation crawl efficiency, the main factors affecting crawl fund are high-quality contented and leafage loading speed.
Happy crawling!
More resources:
- Crawler Traps: Causes, Solutions & Prevention – A Developer’s Deep Dive
- 8 Common Robots.txt Issues And How To Fix Them
- 9 Tips to Optimize Crawl Budget for SEO
- 7 SEO Crawling Tool Warnings & Errors You Can Safely Ignore
- The Ultimate Technical SEO Audit Workbook
Featured Image: BestForBest/Shutterstock

![Win Higher-Quality Links: The PR Approach To SEO Success [Webinar] via @sejournal, @lorenbaker](https://www.searchenginejournal.com/wp-content/uploads/2025/03/featured-1-716.png)





 English (US)
English (US)