ARTICLE AD BOX
Crawl fund is simply a captious SEO conception for ample websites with millions of pages oregon medium-sized websites with a fewer 1000 pages that alteration daily.
An illustration of a website with millions of pages would beryllium eBay.com, and websites with tens of thousands of pages that update often would beryllium idiosyncratic reviews and standing websites akin to Gamespot.com.
There are truthful galore tasks and issues an SEO adept has to see that crawling is often enactment connected the backmost burner.
But crawl fund tin and should beryllium optimized.
In this article, you volition learn:
- How to amended your crawl fund on the way.
- Go implicit the changes to crawl fund arsenic a conception successful the past mates of years.
(Note: If you person a website with conscionable a fewer 100 pages, and pages are not indexed, we urge speechmaking our nonfiction connected communal issues causing indexing problems, arsenic it is surely not due to the fact that of crawl budget.)
What Is Crawl Budget?
Crawl fund refers to the fig of pages that hunt motor crawlers (i.e., spiders and bots) sojourn wrong a definite timeframe.
There are definite considerations that spell into crawl budget, specified arsenic a tentative balance betwixt Googlebot’s attempts to not overload your server and Google’s wide tendency to crawl your domain.
Crawl fund optimization is simply a bid of steps you tin instrumentality to summation ratio and the complaint astatine which hunt engines’ bots sojourn your pages.
Why Is Crawl Budget Optimization Important?
Crawling is the archetypal measurement to appearing successful search. Without being crawled, caller pages and leafage updates won’t beryllium added to hunt motor indexes.
The much often that crawlers sojourn your pages, the quicker updates and caller pages look successful the index. Consequently, your optimization efforts volition instrumentality little clip to instrumentality clasp and commencement affecting your rankings.
Google’s scale contains hundreds of billions of pages and is increasing each day. It costs hunt engines to crawl each URL, and with the increasing fig of websites, they privation to trim computational and retention costs by reducing the crawl rate and indexation of URLs.
There is besides a increasing urgency to trim c emissions for clime change, and Google has a semipermanent strategy to amended sustainability and reduce c emissions.
These priorities could marque it hard for websites to beryllium crawled efficaciously successful the future. While crawl fund isn’t thing you request to interest astir with tiny websites with a fewer 100 pages, assets absorption becomes an important contented for monolithic websites. Optimizing crawl fund means having Google crawl your website by spending arsenic fewer resources arsenic possible.
So, let’s sermon however you tin optimize your crawl fund successful today’s world.
Table of Content
- 1. Disallow Crawling Of Action URLs In Robots.Txt
- 2. Watch Out For Redirect Chains
- 3. Use Server Side Rendering (HTML) Whenever Possible
- 4. Improve Page Speed
- 5. Take Care of Your Internal Links
- 6. Update Your Sitemap
- 7. Implement 304 Status Code
- 8. Hreflang Tags Are Vital
- 9. Monitoring and Maintenance
1. Disallow Crawling Of Action URLs In Robots.Txt
You whitethorn beryllium surprised, but Google has confirmed that disallowing URLs volition not impact your crawl budget. This means Google will inactive crawl your website astatine the aforesaid rate. So wherefore bash we sermon it here?
Well, if you disallow URLs that are not important, you fundamentally archer Google to crawl utile parts of your website astatine a higher rate.
For example, if your website has an interior hunt diagnostic with query parameters similar /?q=google, Google volition crawl these URLs if they are linked from somewhere.
Similarly, successful an e-commerce site, you mightiness person facet filters generating URLs similar /?color=red&size=s.
These query drawstring parameters tin make an infinite fig of unsocial URL combinations that Google whitethorn effort to crawl.
Those URLs fundamentally don’t person unsocial contented and conscionable filter the information you have, which is large for idiosyncratic acquisition but not for Googlebot.
Allowing Google to crawl these URLs wastes crawl fund and affects your website’s wide crawlability. By blocking them via robots.txt rules, Google volition absorption its crawl efforts connected much utile pages connected your site.
Here is however to artifact interior search, facets, oregon immoderate URLs containing query strings via robots.txt:
Disallow: *?*s=* Disallow: *?*color=* Disallow: *?*size=*Each regularisation disallows immoderate URL containing the respective query parameter, careless of different parameters that whitethorn beryllium present.
- * (asterisk) matches immoderate series of characters (including none).
- ? (Question Mark): Indicates the opening of a query string.
- =*: Matches the = motion and immoderate consequent characters.
This attack helps debar redundancy and ensures that URLs with these circumstantial query parameters are blocked from being crawled by hunt engines.
Note, however, that this method ensures immoderate URLs containing the indicated characters volition beryllium disallowed nary substance wherever the characters appear. This tin pb to unintended disallows. For example, query parameters containing a azygous quality volition disallow immoderate URLs containing that quality careless of wherever it appears. If you disallow ‘s’, URLs containing ‘/?pages=2’ volition beryllium blocked due to the fact that *?*s= matches besides ‘?pages=’. If you privation to disallow URLs with a circumstantial azygous character, you tin usage a operation of rules:
Disallow: *?s=* Disallow: *&s=*The captious alteration is that determination is nary asterisk ‘*’ betwixt the ‘?’ and ‘s’ characters. This method allows you to disallow circumstantial nonstop ‘s’ parameters successful URLs, but you’ll request to adhd each saltation individually.
Apply these rules to your circumstantial usage cases for immoderate URLs that don’t supply unsocial content. For example, successful lawsuit you person wishlist buttons with “?add_to_wishlist=1” URLs, you request to disallow them by the rule:
Disallow: /*?*add_to_wishlist=*This is simply a no-brainer and a earthy archetypal and astir important measurement recommended by Google.
An illustration beneath shows however blocking those parameters helped to trim the crawling of pages with query strings. Google was trying to crawl tens of thousands of URLs with antithetic parameter values that didn’t marque sense, starring to non-existent pages.
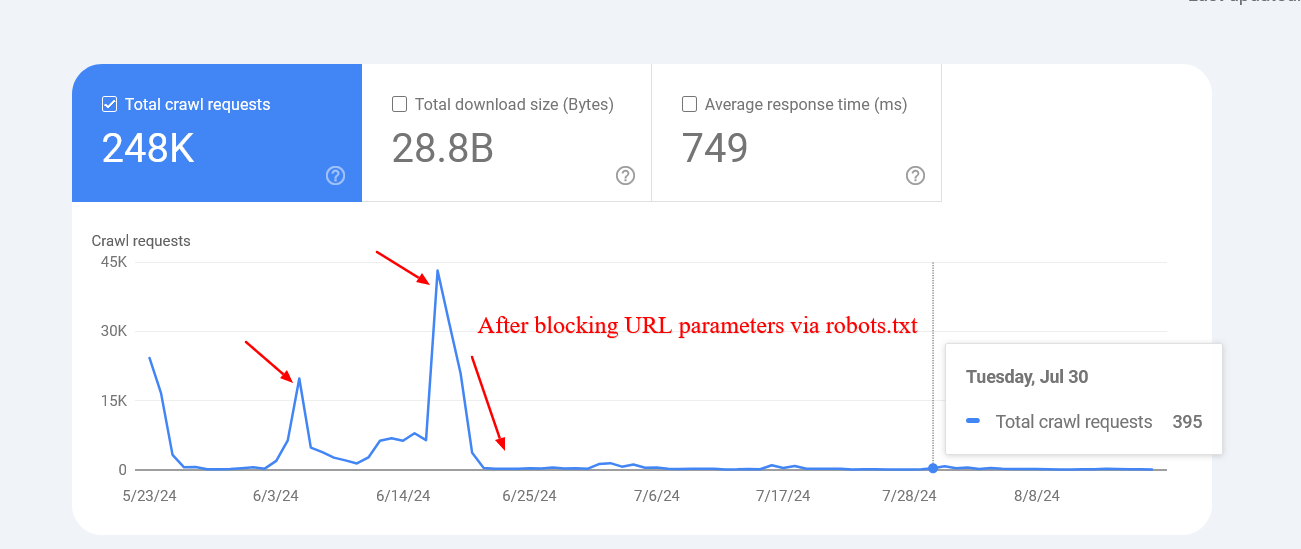 Reduced crawl complaint of URLs with parameters aft blocking via robots.txt.
Reduced crawl complaint of URLs with parameters aft blocking via robots.txt.
However, sometimes disallowed URLs mightiness inactive beryllium crawled and indexed by hunt engines. This whitethorn look strange, but it isn’t mostly origin for alarm. It usually means that different websites nexus to those URLs.
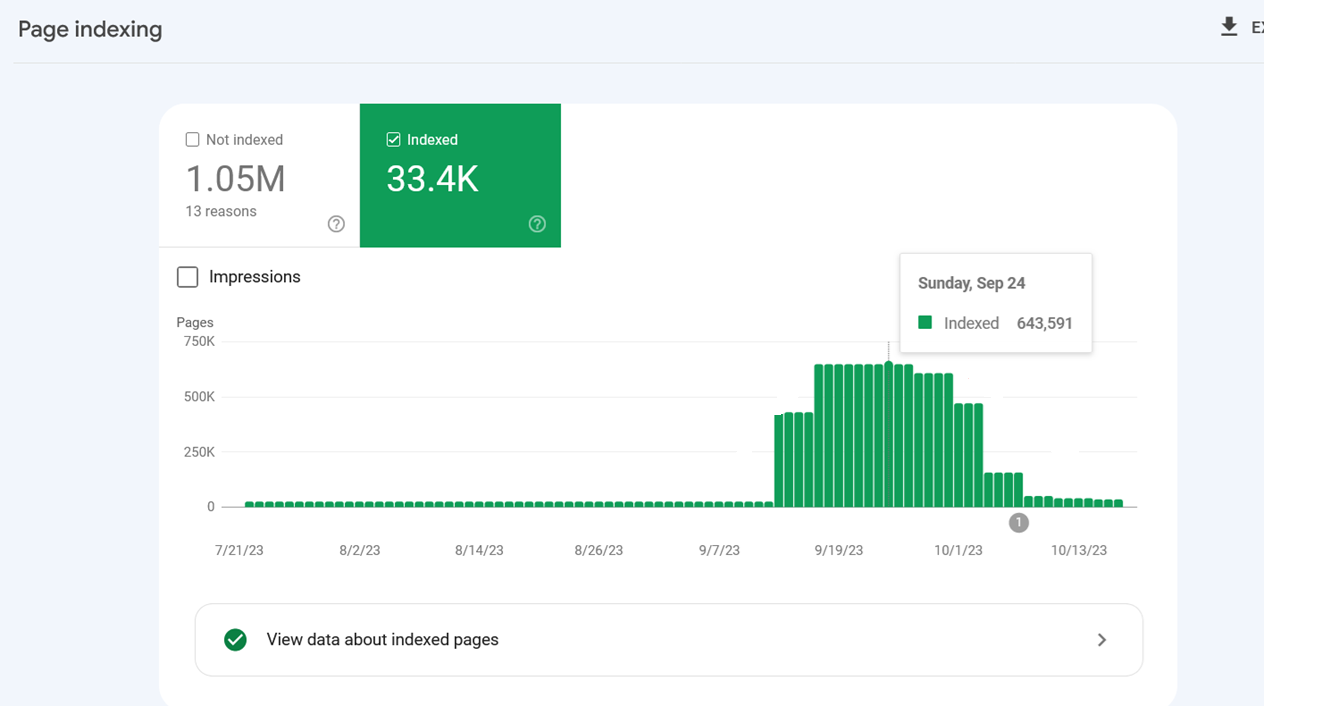 Indexing spiked due to the fact that Google indexed interior hunt URLs aft they were blocked via robots.txt.
Indexing spiked due to the fact that Google indexed interior hunt URLs aft they were blocked via robots.txt.
Google confirmed that the crawling enactment volition driblet implicit clip successful these cases.
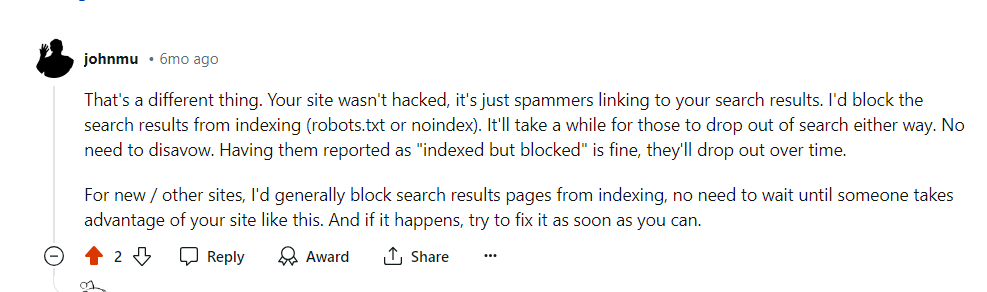 Google’s remark connected Reddit, July 2024
Google’s remark connected Reddit, July 2024
Another important payment of blocking these URLs via robots.txt is redeeming your server resources. When a URL contains parameters that bespeak the beingness of dynamic content, requests volition go to the server alternatively of the cache. This increases the load connected your server with each leafage crawled.
Please retrieve not to usage “noindex meta tag” for blocking since Googlebot has to execute a petition to spot the meta tag oregon HTTP effect code, wasting crawl budget.
1.2. Disallow Unimportant Resource URLs In Robots.txt
Besides disallowing enactment URLs, you whitethorn privation to disallow JavaScript files that are not portion of the website layout oregon rendering.
For example, if you person JavaScript files liable for opening images successful a popup erstwhile users click, you tin disallow them successful robots.txt truthful Google doesn’t discarded fund crawling them.
Here is an illustration of the disallow regularisation of JavaScript file:
Disallow: /assets/js/popup.js
However, you should ne'er disallow resources that are portion of rendering. For example, if your contented is dynamically loaded via JavaScript, Google needs to crawl the JS files to scale the contented they load.
Another illustration is REST API endpoints for signifier submissions. Say you person a signifier with enactment URL “/rest-api/form-submissions/”.
Potentially, Google whitethorn crawl them. Those URLs are successful nary mode related to rendering, and it would beryllium bully signifier to artifact them.
Disallow: /rest-api/form-submissions/
However, headless CMSs often usage REST APIs to load contented dynamically, truthful marque definite you don’t artifact those endpoints.
In a nutshell, look astatine immoderate isn’t related to rendering and artifact them.
2. Watch Out For Redirect Chains
Redirect chains hap erstwhile aggregate URLs redirect to different URLs that besides redirect. If this goes connected for excessively long, crawlers whitethorn wantonness the concatenation earlier reaching the last destination.
URL 1 redirects to URL 2, which directs to URL 3, and truthful on. Chains tin besides instrumentality the signifier of infinite loops erstwhile URLs redirect to 1 another.
Avoiding these is simply a common-sense attack to website health.
Ideally, you would beryllium capable to debar having adjacent a azygous redirect concatenation connected your full domain.
But it whitethorn beryllium an intolerable task for a ample website – 301 and 302 redirects are bound to appear, and you can’t hole redirects from inbound backlinks simply due to the fact that you don’t person power implicit outer websites.
One oregon 2 redirects present and determination mightiness not wounded much, but agelong chains and loops tin go problematic.
In bid to troubleshoot redirect chains you tin usage 1 of the SEO tools similar Screaming Frog, Lumar, oregon Oncrawl to find chains.
When you observe a chain, the champion mode to hole it is to region each the URLs betwixt the archetypal leafage and the last page. If you person a concatenation that passes done 7 pages, past redirect the archetypal URL straight to the seventh.
Another large mode to trim redirect chains is to regenerate interior URLs that redirect with last destinations successful your CMS.
Depending connected your CMS, determination whitethorn beryllium antithetic solutions successful place; for example, you tin usage this plugin for WordPress. If you person a antithetic CMS, you whitethorn request to usage a customized solution oregon inquire your dev squad to bash it.
3. Use Server Side Rendering (HTML) Whenever Possible
Now, if we’re talking astir Google, its crawler uses the latest mentation of Chrome and is capable to spot content loaded by JavaScript conscionable fine.
But let’s deliberation critically. What does that mean? Googlebot crawls a leafage and resources specified arsenic JavaScript past spends much computational resources to render them.
Remember, computational costs are important for Google, and it wants to trim them arsenic overmuch arsenic possible.
So wherefore render contented via JavaScript (client side) and adhd other computational outgo for Google to crawl your pages?
Because of that, whenever possible, you should instrumentality to HTML.
That way, you’re not hurting your chances with immoderate crawler.
4. Improve Page Speed
As we discussed above, Googlebot crawls and renders pages with JavaScript, which means if it spends less resources to render webpages, the easier it volition beryllium for it to crawl, which depends connected however good optimized your website speed is.
Google says:
Google’s crawling is constricted by bandwidth, time, and availability of Googlebot instances. If your server responds to requests quicker, we mightiness beryllium capable to crawl much pages connected your site.
So utilizing server-side rendering is already a large measurement towards improving leafage speed, but you request to marque definite your Core Web Vital metrics are optimized, particularly server effect time.
5. Take Care of Your Internal Links
Google crawls URLs that are connected the page, and ever support successful caput that antithetic URLs are counted by crawlers arsenic abstracted pages.
If you person a website with the ‘www’ version, marque definite your interior URLs, particularly connected navigation, constituent to the canonical version, i.e. with the ‘www’ mentation and vice versa.
Another communal mistake is missing a trailing slash. If your URLs person a trailing slash astatine the end, marque definite your interior URLs besides person it.
Otherwise, unnecessary redirects, for example, “https://www.example.com/sample-page” to “https://www.example.com/sample-page/” volition effect successful 2 crawls per URL.
Another important facet is to debar broken interior links pages, which tin devour your crawl fund and soft 404 pages.
And if that wasn’t atrocious enough, they besides wounded your idiosyncratic experience!
In this case, again, I’m successful favour of utilizing a instrumentality for website audit.
WebSite Auditor, Screaming Frog, Lumar oregon Oncrawl, and SE Ranking are examples of large tools for a website audit.
6. Update Your Sitemap
Once again, it’s a existent win-win to instrumentality attraction of your XML sitemap.
The bots volition person a overmuch amended and easier clip knowing wherever the interior links lead.
Use lone the URLs that are canonical for your sitemap.
Also, marque definite that it corresponds to the newest uploaded mentation of robots.txt and loads fast.
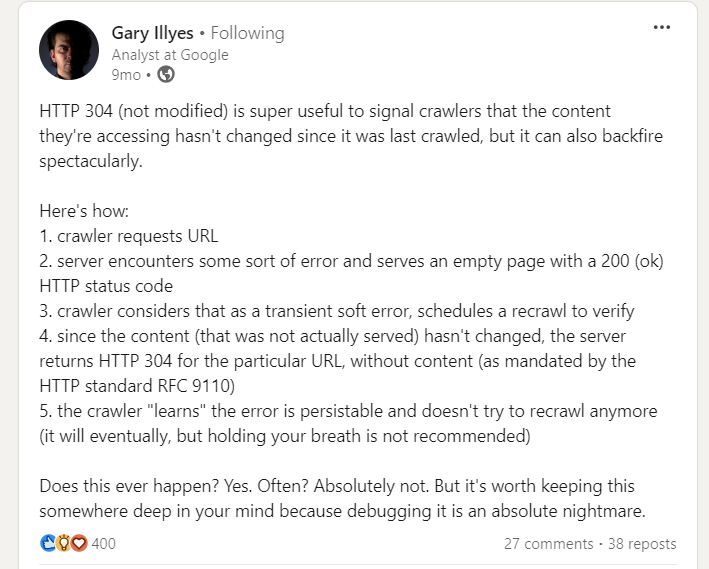
7. Implement 304 Status Code
When crawling a URL, Googlebot sends a day via the “If-Modified-Since” header, which is further accusation astir the past clip it crawled the fixed URL.
If your webpage hasn’t changed since past (specified successful “If-Modified-Since“), you whitethorn instrumentality the “304 Not Modified” status code with nary effect body. This tells hunt engines that webpage contented didn’t change, and Googlebot tin usage the mentation from the past sojourn it has connected the file.
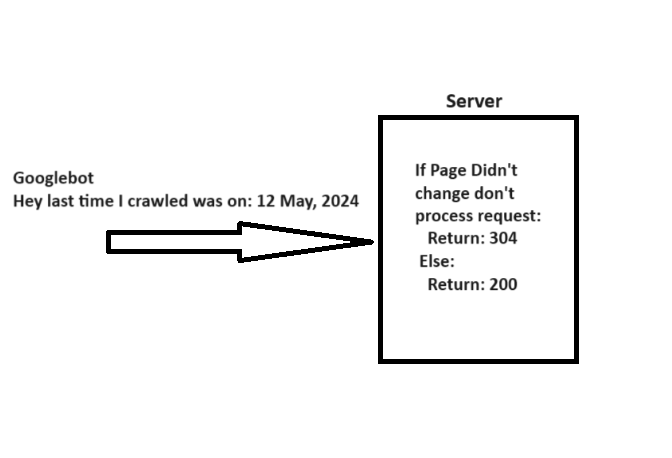 A elemental mentation of however 304 not modified http presumption codification works.
A elemental mentation of however 304 not modified http presumption codification works.
Imagine however galore server resources you tin prevention portion helping Googlebot prevention resources erstwhile you person millions of webpages. Quite big, isn’t it?
However, determination is simply a caveat erstwhile implementing 304 presumption code, pointed retired by Gary Illyes.
 Gary Illes connected LinkedIn
Gary Illes connected LinkedIn
So beryllium cautious. Server errors serving bare pages with a 200 presumption tin origin crawlers to halt recrawling, starring to long-lasting indexing issues.
8. Hreflang Tags Are Vital
In bid to analyse your localized pages, crawlers employment hreflang tags. You should beryllium telling Google astir localized versions of your pages arsenic intelligibly arsenic possible.
First off, usage the <link rel="alternate" hreflang="lang_code" href="url_of_page" /> successful your page’s header. Where “lang_code” is simply a codification for a supported language.
You should usage the <loc> constituent for immoderate fixed URL. That way, you tin constituent to the localized versions of a page.
Read: 6 Common Hreflang Tag Mistakes Sabotaging Your International SEO
9. Monitoring and Maintenance
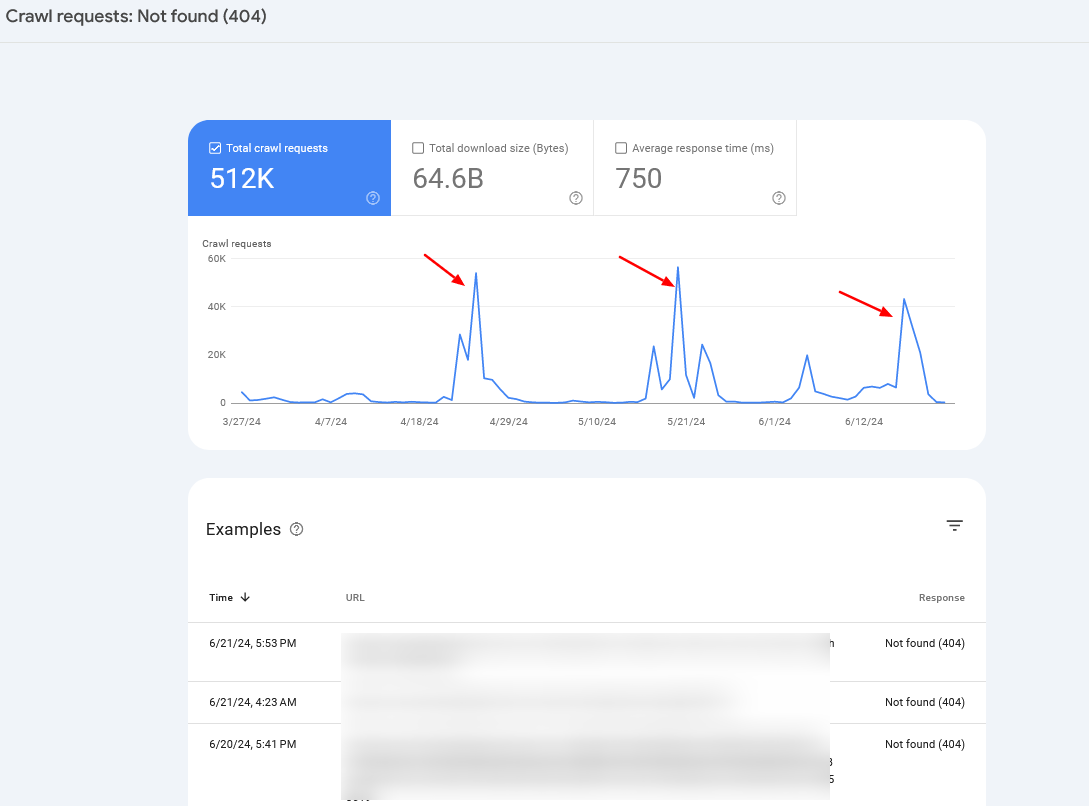
Check your server logs and Google Search Console’s Crawl Stats study to show crawl anomalies and place imaginable problems.
If you announcement periodic crawl spikes of 404 pages, successful 99% of cases, it is caused by infinite crawl spaces, which we person discussed above, oregon indicates other problems your website whitethorn beryllium experiencing.
 Crawl complaint spikes
Crawl complaint spikes
Often, you whitethorn privation to harvester server log accusation with Search Console information to place the basal cause.
Summary
So, if you were wondering whether crawl fund optimization is inactive important for your website, the reply is intelligibly yes.
Crawl fund is, was, and astir apt volition beryllium an important happening to support successful caput for each SEO professional.
Hopefully, these tips volition assistance you optimize your crawl fund and amended your SEO show – but remember, getting your pages crawled doesn’t mean they volition beryllium indexed.
In lawsuit you look indexation issues, I suggest speechmaking the pursuing articles:
- The 5 Most Common Google Indexing Issues by Website Size
- 14 Top Reasons Why Google Isn’t Indexing Your Site
- Google On Fixing Discovered Currently Not Indexed
Featured Image: BestForBest/Shutterstock
All screenshots taken by author

![Win Higher-Quality Links: The PR Approach To SEO Success [Webinar] via @sejournal, @lorenbaker](https://www.searchenginejournal.com/wp-content/uploads/2025/03/featured-1-716.png)





 English (US)
English (US)