
ARTICLE AD BOX
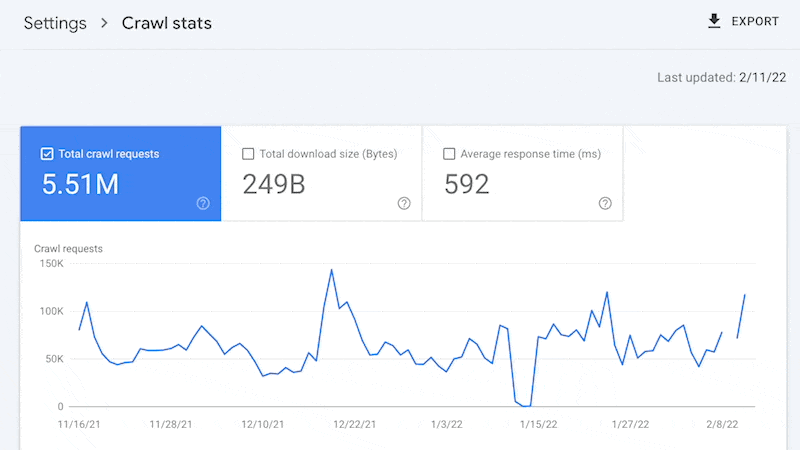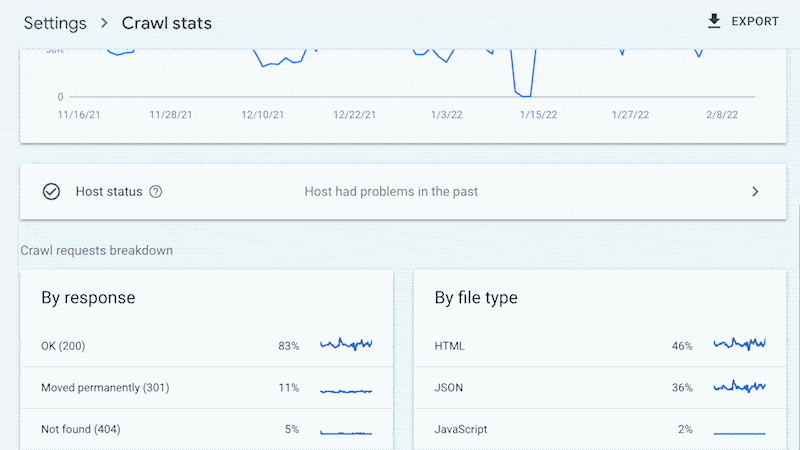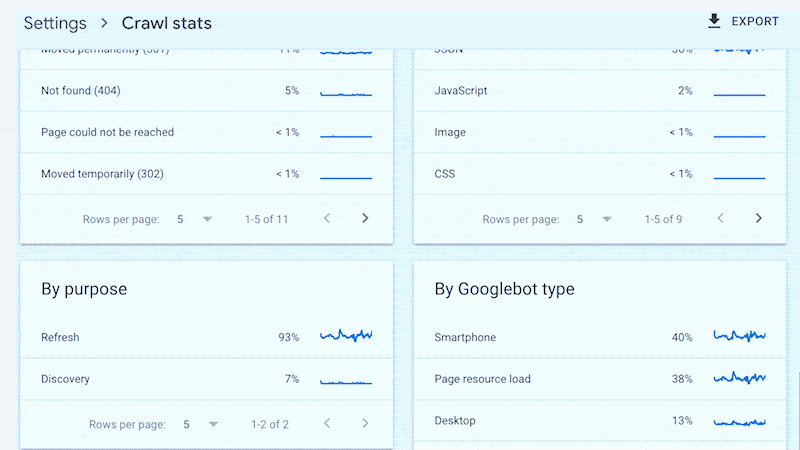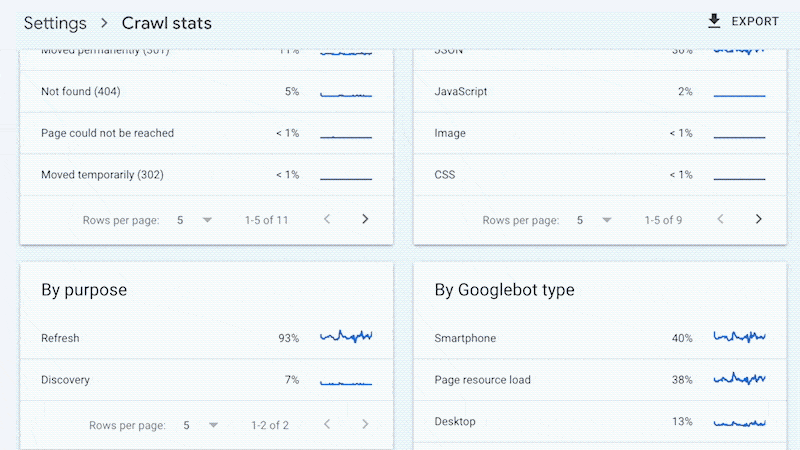
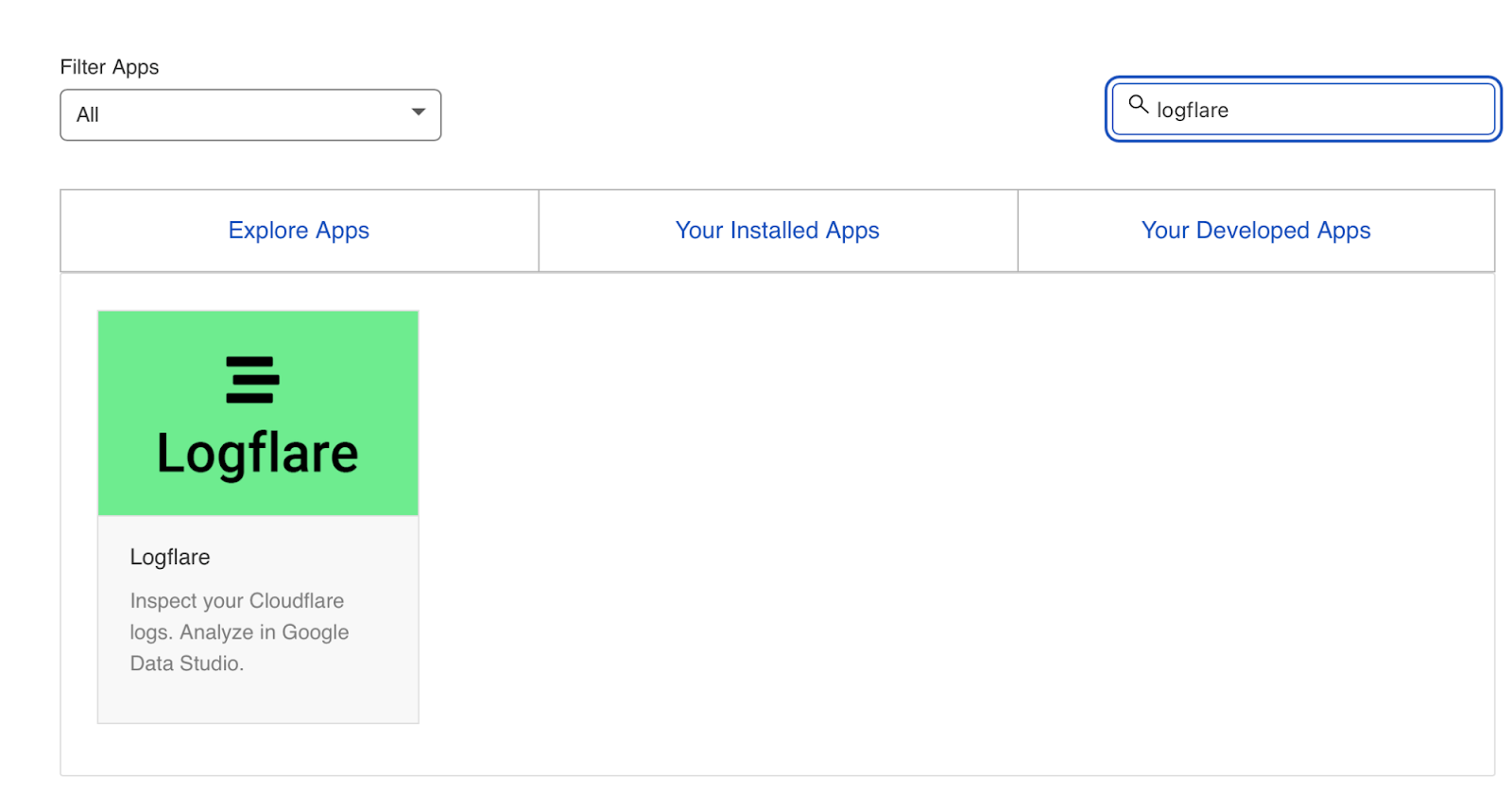
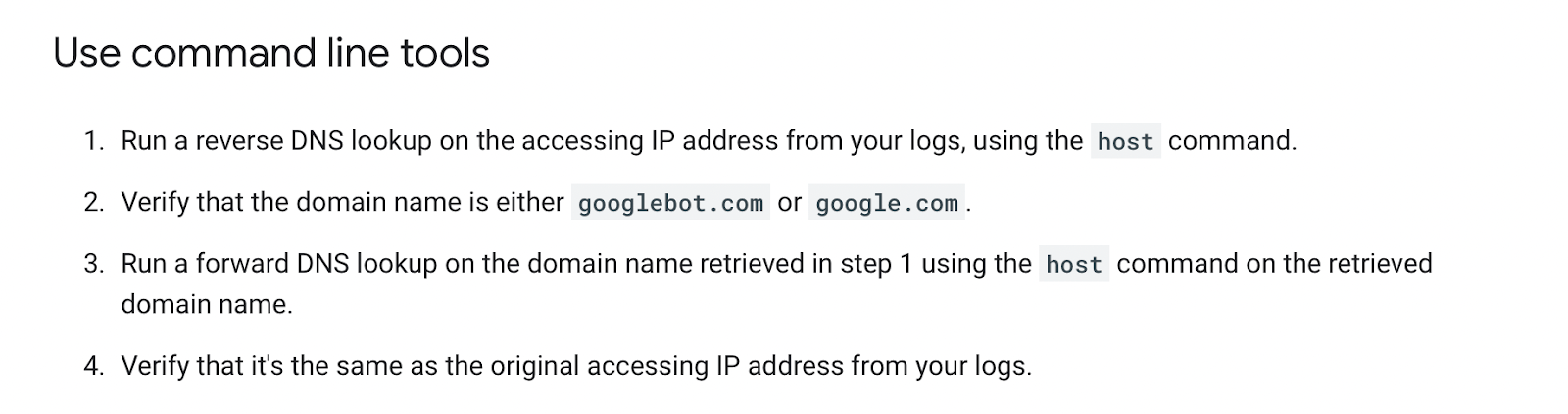
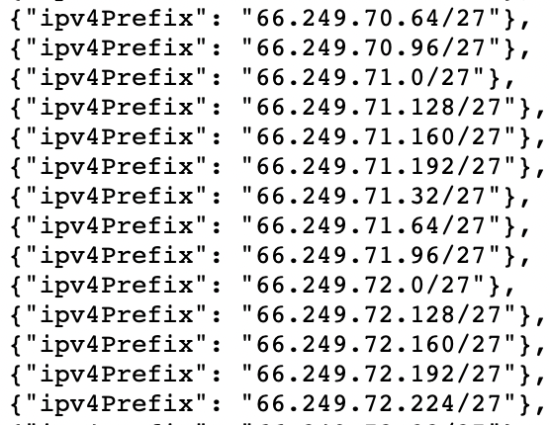
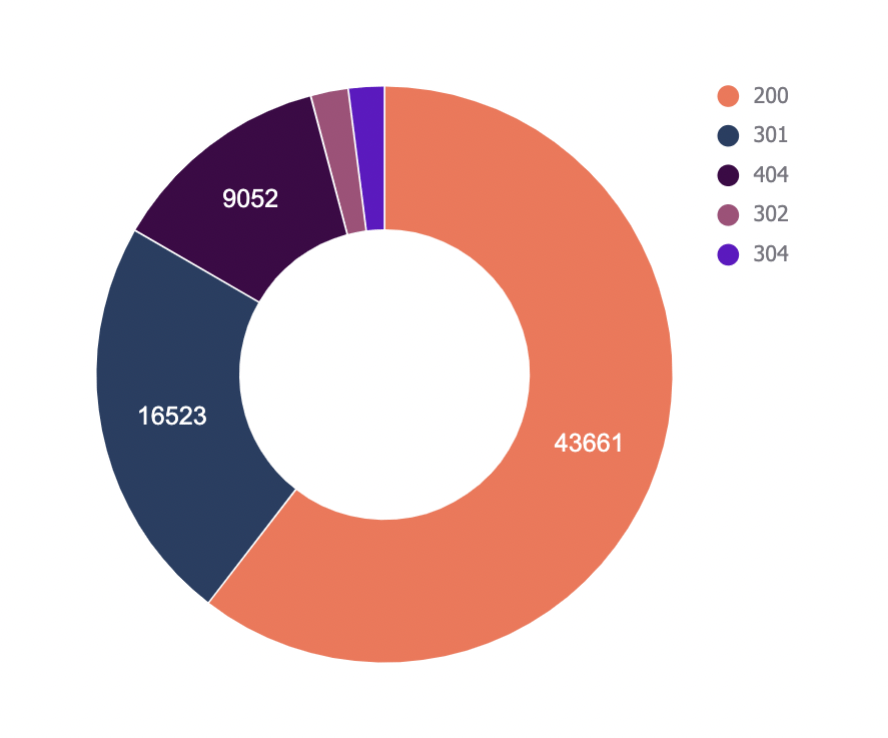
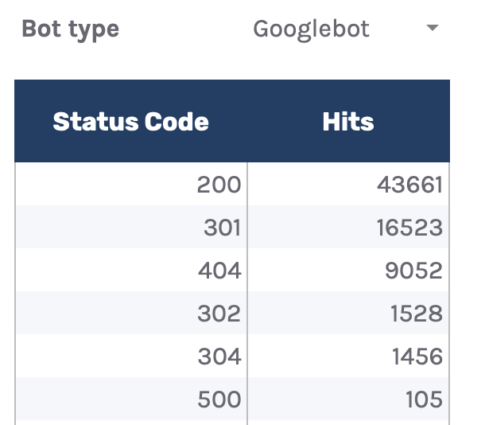
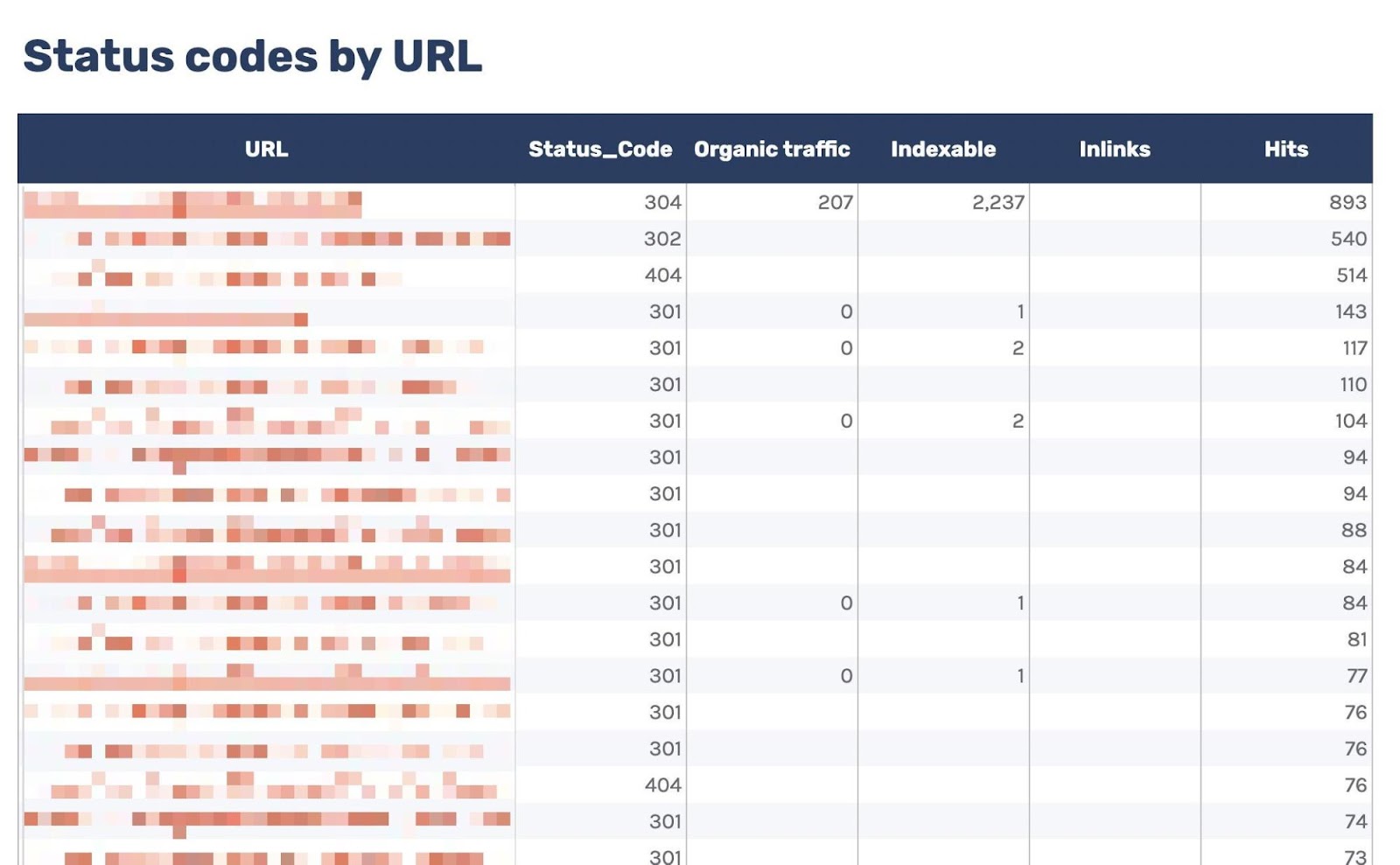
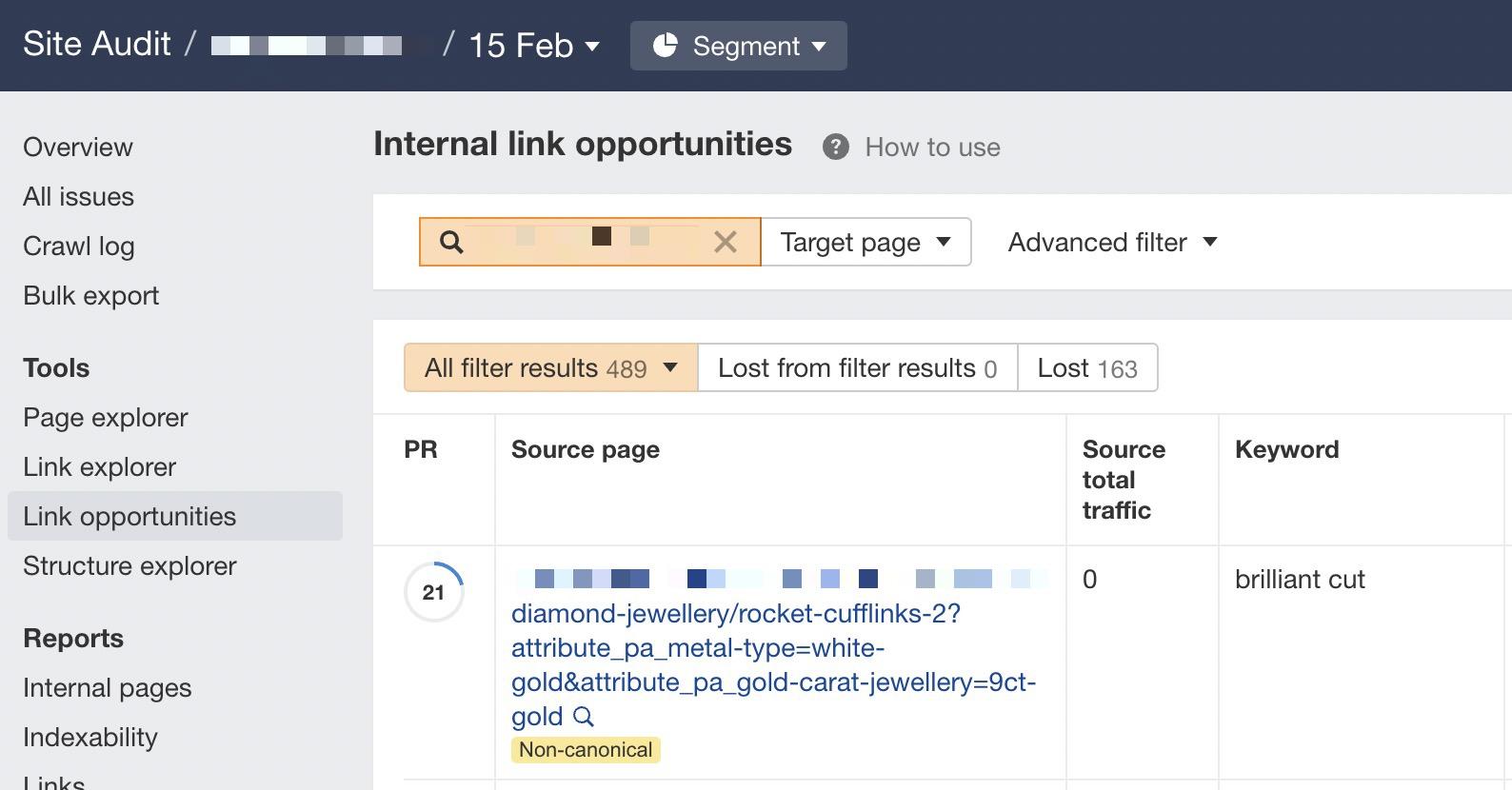
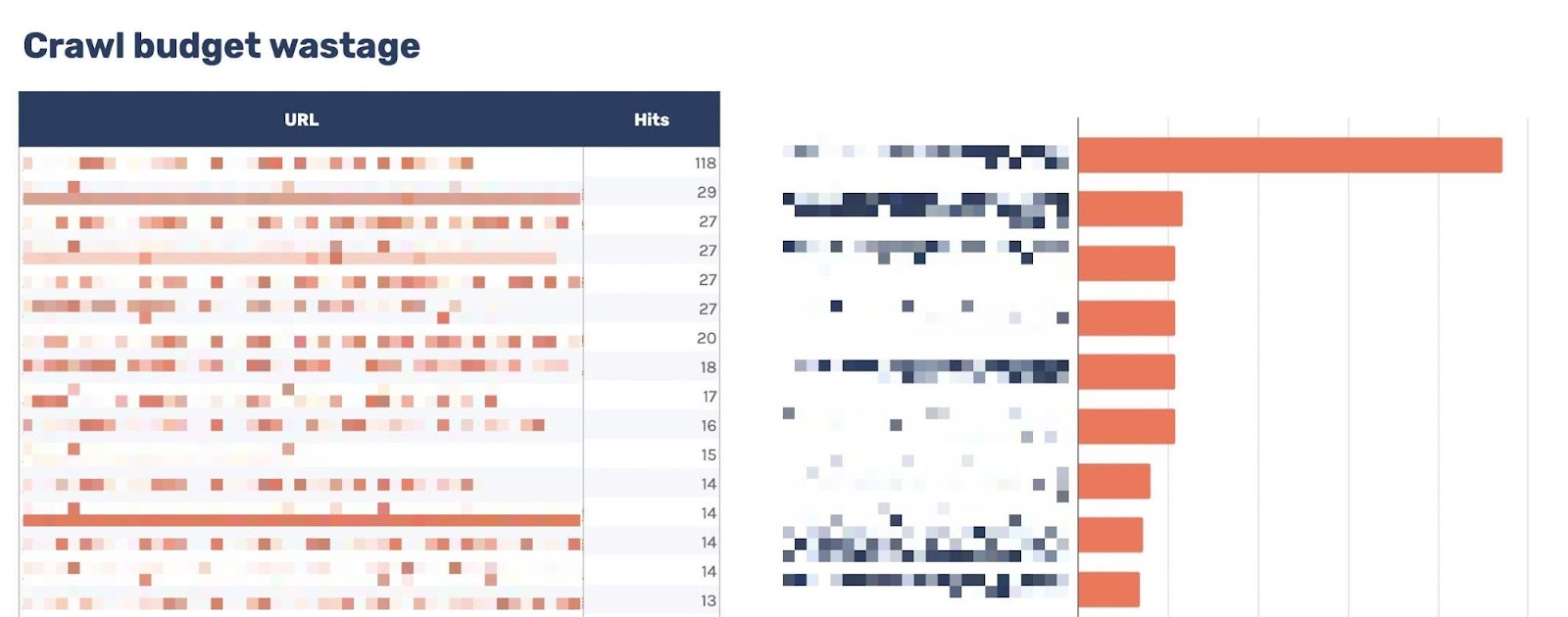
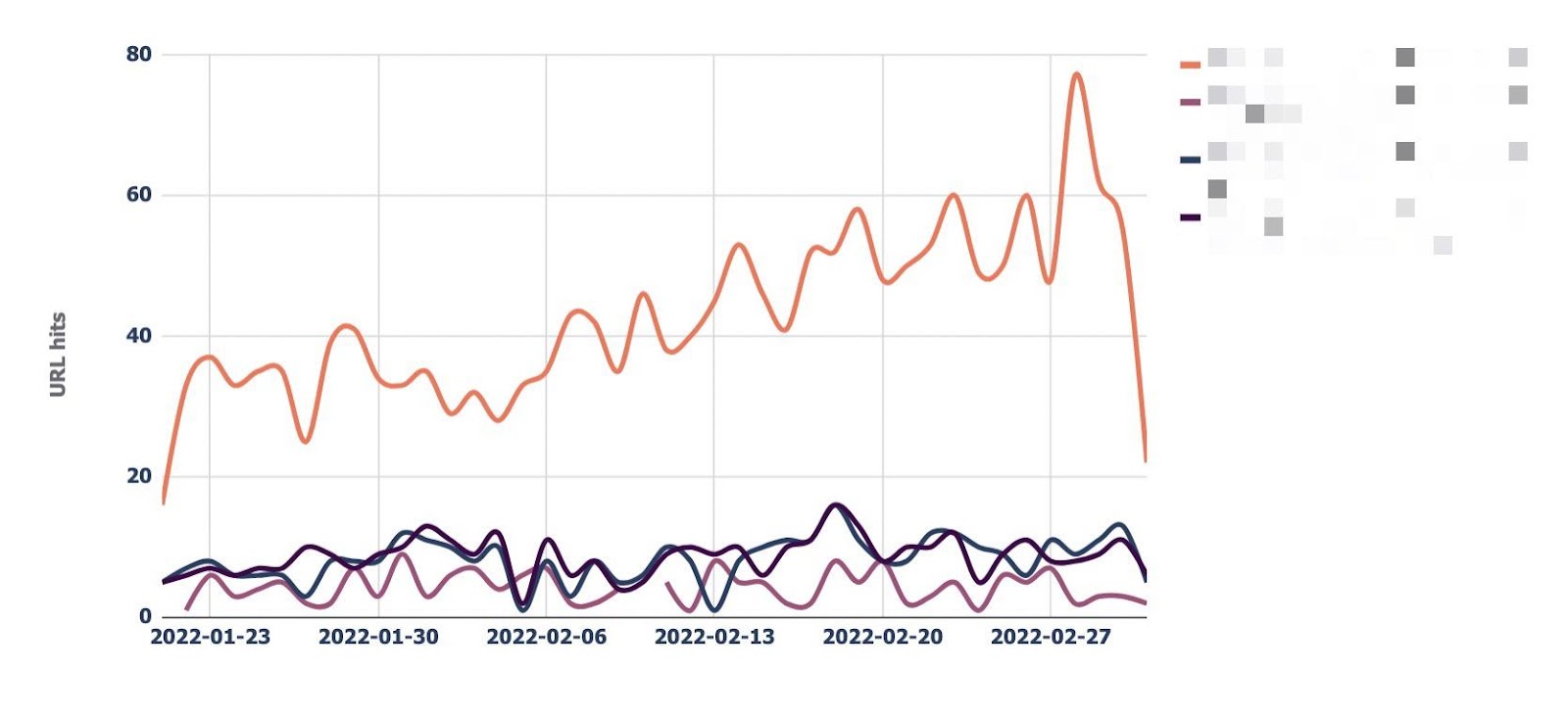
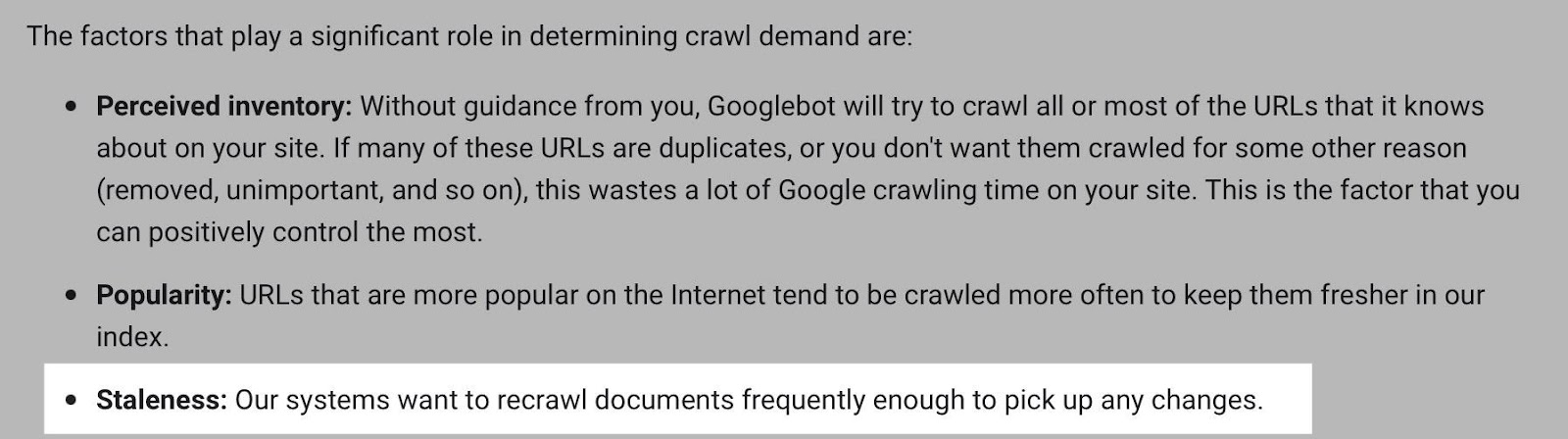
Log files have been receiving expanding designation from method SEOs implicit the past 5 years, and for a bully reason. They’re the most trustworthy source of accusation to recognize the URLs that hunt engines person crawled, which tin beryllium captious accusation to assistance diagnose problems with method SEO. Google itself recognizes their importance, releasing caller features successful Google Search Console and making it casual to spot samples of information that would antecedently lone beryllium disposable by analyzing logs. In addition, Google Search Advocate John Mueller has publically stated however overmuch bully accusation log files hold. @glenngabe Log files are truthful underrated, truthful overmuch bully accusation in them. With each this hype astir the information successful log files, you whitethorn privation to recognize logs better, however to analyze them, and whether the sites you’re moving connected will benefit from them. This nonfiction volition answer all of that and more. Here’s what we’ll beryllium discussing: A server log record is simply a record created and updated by a server that records the activities it has performed. A fashionable server log record is an access log file, which holds a past of HTTP requests to the server (by some users and bots). When a non-developer mentions a log file, entree logs are the ones they’ll usually beryllium referring to. Developers, however, find themselves spending much clip looking astatine mistake logs, which study issues encountered by the server. The supra is important: If you petition logs from a developer, the archetypal happening they’ll inquire is, “Which ones?” Therefore, always beryllium circumstantial with log record requests. If you privation logs to analyze crawling, ask for entree logs. Access log files incorporate tons of accusation astir each petition made to the server, specified arsenic the following: What servers see successful entree logs varies by the server type and sometimes what developers have configured the server to store successful log files. Common formats for log files see the following: Other forms exist, but these are the main ones you’ll encounter. Now that we’ve got a basic understanding of log files, let’s see how they payment SEO. Here are immoderate key ways: All sites will payment from log record investigation to immoderate degree, but the magnitude of payment varies massively depending connected site size. This is as log files primarily payment sites by helping you better manage crawling. Google itself states managing the crawl fund is something larger-scale or often changing sites will payment from. The aforesaid is existent for log file analysis. For example, smaller sites tin apt usage the “Crawl stats” data provided successful Google Search Console and person each of the benefits mentioned above—without ever needing to interaction a log file. Yes, Google won’t supply you with all URLs crawled (like with log files), and the trends investigation is constricted to three months of data. However, smaller sites that alteration infrequently besides request little ongoing method SEO. It’ll likely suffice to person a tract auditor observe and diagnose issues. For example, a cross-analysis from a tract crawler, XML sitemaps, Google Analytics, and Google Search Console volition likely discover each orphan pages. You can also usage a tract auditor to observe mistake presumption codes from interior links. There are a fewer cardinal reasons I’m pointing this out: In astir cases, to analyze log files, you’ll archetypal person to petition access to log files from a developer. The developer is past apt going to person a fewer issues, which they’ll bring to your attention. These include: These issues volition bring to question whether storing, merging, filtering, and transferring log files are worth the dev effort, particularly if developers already person a agelong database of priorities (which is often the case). Developers volition apt enactment the onus on the SEO to explain/build a lawsuit for why developers should put clip successful this, which you volition request to prioritize among different SEO focuses. These issues are precisely wherefore log record investigation doesn’t hap frequently. Log files you person from developers are also often formatted successful unsupported ways by fashionable log record investigation tools, making investigation much difficult. Thankfully, determination are bundle solutions that simplify this process. My favorite is Logflare, a Cloudflare app that tin store log files successful a BigQuery database that you own. Now it’s clip to commencement analyzing your logs. I’m going to amusement you however to bash this successful the discourse of Logflare specifically; however, the tips connected however to usage log information volition enactment with any logs. The template I’ll stock soon besides works with immoderate logs. You’ll just request to marque definite the columns successful the information sheets match up. Logflare is elemental to acceptable up. And with the BigQuery integration, it stores information long term. You’ll own the data, making it easy accessible for everyone. There’s one difficulty. You request to swap retired your domain sanction servers to usage Cloudflare ones and negociate your DNS there. For most, this is fine. However, if you’re moving with a much enterprise-level site, it’s improbable you tin convince the server infrastructure team to change the sanction servers to simplify log analysis. I won’t go through each measurement connected however to get Logflare working. But to get started, each you request to bash is caput to the Cloudflare Apps portion of your dashboard. And past hunt for Logflare. The setup past this constituent is self-explanatory (create an account, springiness your task a name, take the information to send, etc.). The lone other portion I urge pursuing is Logflare’s usher to setting up BigQuery. Bear successful mind, however, that BigQuery does person a cost that’s based connected the queries you bash and the magnitude of information you store. Sidenote. It’s worthy noting that 1 significant advantage of the BigQuery backend is that you own the data. That means you tin circumvent PII issues by configuring Logflare not to nonstop PII similar IP addresses and delete PII from BigQuery utilizing an SQL query. We’ve now stored log files (via Logflare oregon an alternate method). Next, we request to extract logs precisely from the idiosyncratic agents we privation to analyze. For most, this volition beryllium Googlebot. Before we bash that, we person different hurdle to leap across. Many bots unreal to be Googlebot to get past firewalls (if you person one). In addition, immoderate auditing tools bash the aforesaid to get an close reflection of the contented your tract returns for the idiosyncratic agent, which is indispensable if your server returns antithetic HTML for Googlebot, e.g., if you’ve acceptable up dynamic rendering. If you aren’t utilizing Logflare, identifying Googlebot volition necessitate a reverse DNS lookup to verify the petition did travel from Google. Google has a useful usher on validating Googlebot manually here. You tin bash this connected a one-off basis, utilizing a reverse IP lookup tool and checking the domain sanction returned. However, we request to bash this successful bulk for each rows successful our log files. This besides requires you to lucifer IP addresses from a list provided by Google. The easiest mode to bash this is by utilizing server firewall regularisation sets maintained by 3rd parties that artifact fake bots (resulting successful fewer/no fake Googlebots in your log files). A popular 1 for Nginx is “Nginx Ultimate Bad Bot Blocker.” Alternatively, thing you’ll enactment on the database of Googlebot IPs is the IPV4 addresses each statesman with “66.” While it won’t beryllium 100% accurate, you can also cheque for Googlebot by filtering for IP addresses starting with “6” when analyzing the information wrong your logs. Cloudflare’s pro program (currently $20/month) has built-in firewall features that tin artifact fake Googlebot requests from accessing your site. Cloudflare disables these features by default, but you tin find them by heading to Firewall > Managed Rules > enabling “Cloudflare Specials” > select “Advanced”: Next, alteration the hunt benignant from “Description” to “ID” and hunt for “100035.” Cloudflare volition present contiguous you with a database of options to artifact fake hunt bots. Set the applicable ones to “Block,” and Cloudflare volition cheque each requests from hunt bot idiosyncratic agents are legitimate, keeping your log files clean. Finally, we present person entree to log files, and we cognize the log files accurately bespeak genuine Googlebot requests. I urge analyzing your log files wrong Google Sheets/Excel to commencement with because you’ll apt beryllium utilized to spreadsheets, and it’s simple to cross-analyze log files with different sources similar a site crawl. There is nary 1 close mode to bash this. You tin usage the following: You tin besides bash this wrong a Data Studio report. I find Data Studio adjuvant for monitoring information implicit time, and Google Sheets/Excel is amended for a one-off investigation erstwhile method auditing. Open BigQuery and caput to your project/dataset. Select the “Query” dropdown and unfastened it successful a new tab. Next, you’ll request to constitute immoderate SQL to extract the information you’ll beryllium analyzing. To make this easier, archetypal transcript the contents of the FROM portion of the query. And past you tin adhd that wrong the query I’ve written for you below: SELECT DATE(timestamp) AS Date, req.url AS URL, req_headers.cf_connecting_ip AS IP, req_headers.user_agent AS User_Agent, resp.status_code AS Status_Code, resp.origin_time AS Origin_Time, resp_headers.cf_cache_status AS Cache_Status, resp_headers.content_type AS Content_Type FROM `[Add Your from code here]`, UNNEST(metadata) m, UNNEST(m.request) req, UNNEST(req.headers) req_headers, UNNEST(m.response) resp, UNNEST(resp.headers) resp_headers WHERE DATE(timestamp) >= "2022-01-03" AND (req_headers.user_agent LIKE '%Googlebot%' OR req_headers.user_agent LIKE '%bingbot%') ORDER BY timestamp DESC This query selects each the columns of information that are useful for log record investigation for SEO purposes. It besides lone pulls information for Googlebot and Bingbot. Sidenote. If determination are different bots you privation to analyze, conscionable adhd different OR req_headers.user_agent LIKE ‘%bot_name%’ wrong the WHERE statement. You tin besides easy alteration the commencement date by updating the WHERE DATE(timestamp) >= “2022–03-03” line. Select “Run” at the top. Then take to prevention the results. Next, prevention the information to a CSV successful Google Drive (this is the champion enactment owed to the larger file size). And then, erstwhile BigQuery has tally the occupation and saved the file, unfastened the record with Google Sheets. We’re present going to commencement with immoderate analysis. I urge utilizing my Google Sheets template. But I’ll explicate what I’m doing, and you tin physique the study yourself if you want. The template consists of 2 information tabs to transcript and paste your information into, which I then use for each different tabs utilizing the Google Sheets QUERY function. Sidenote. If you privation to spot however I’ve completed the reports that we’ll tally done aft mounting up, prime the archetypal compartment successful each table. To commencement with, transcript and paste the output of your export from BigQuery into the “Data — Log files” tab. Note that determination are aggregate columns added to the extremity of the expanse (in darker grey) to marque investigation a small easier (like the bot name and first URL directory). If you person a tract auditor, I urge adding more data to the Google Sheet. Mainly, you should add these: To get this information retired of Ahrefs’ Site Audit, caput to Page Explorer and prime “Manage Columns.” I past urge adding the columns shown below: Then export each of that data. And transcript and paste into the “Data — Ahrefs” sheet. The archetypal happening we’ll analyse is status codes. This information volition reply whether hunt bots are wasting crawl fund connected non-200 URLs. Note that this doesn’t ever constituent toward an issue. Sometimes, Google tin crawl aged 301s for galore years. However, it tin item an contented if you’re internally linking to galore non-200 presumption codes. The “Status Codes — Overview” tab has a QUERY function that summarizes the log record information and displays the results successful a chart. There is besides a dropdown to filter by bot benignant and see which ones are hitting non-200 presumption codes the most. Of course, this study alone doesn’t assistance america lick the issue, truthful I’ve added different tab, “URLs — Overview.” You tin usage this to filter for URLs that instrumentality non-200 presumption codes. As I’ve besides included information from Ahrefs’ Site Audit, you tin spot whether you’re internally linking to immoderate of those non-200 URLs successful the “Inlinks” column. If you spot a batch of interior links to the URL, you tin past usage the Internal nexus opportunities report to spot these incorrect interior links by simply copying and pasting the URL successful the hunt barroom with “Target page” selected. The champion mode to item crawl budget wastage from log files that isn’t due to crawling non-200 presumption codes is to find often crawled non-indexable URLs (e.g., they’re canonicalized or noindexed). Since we’ve added information from our log files and Ahrefs’ Site Audit, spotting these URLs is straightforward. Head to the “Crawl fund wastage” tab, and you’ll find highly crawled HTML files that instrumentality a 200 but are non-indexable. Now that you person this data, you’ll privation to analyse wherefore the bot is crawling the URL. Here are immoderate common reasons: It’s communal for larger sites, particularly those with faceted navigation, to nexus to galore non-indexable URLs internally. If the deed numbers successful this study are precise precocious and you judge you’re wasting your crawl budget, you’ll apt request to region interior links to the URLs oregon block crawling with the robots.txt. If you person circumstantial URLs connected your tract that are incredibly important to you, you whitethorn privation to watch how often hunt engines crawl them. The “URL monitor” tab does conscionable that, plotting the regular inclination of hits for up to 5 URLs that you can add. You tin besides filter by bot type, making it casual to show however often Bing oregon Google crawls a URL. Sidenote. You can also usage this study to cheque URLs you’ve precocious redirected. Simply adhd the aged URL and caller URL successful the dropdown and spot however rapidly Googlebot notices the change. Often, the advice present is that it’s a atrocious happening if Google doesn’t crawl a URL frequently. That simply isn’t the case. While Google tends to crawl fashionable URLs much frequently, it volition apt crawl a URL little if it doesn’t alteration often. Still, it’s adjuvant to monitor URLs similar this if you request contented changes picked up quickly, specified as on a quality site’s homepage. In fact, if you announcement Google is recrawling a URL excessively frequently, I’ll advocate for trying to assistance it better negociate crawl complaint by doing things similar adding <lastmod> to XML sitemaps. Here’s what it looks like: <?xml version="1.0" encoding="UTF-8"?> <urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"> <url> <loc>https://www.logexample.com/example</loc> <lastmod>2022-10-04</lastmod> </url> </urlset> You tin past update the <lastmod> property whenever the contented of the leafage changes, signaling Google to recrawl. Another mode to usage log files is to observe orphan URLs, i.e., URLs that you privation hunt engines to crawl and scale but haven’t internally linked to. We tin bash this by checking for 200 presumption codification HTML URLs with nary interior links recovered by Ahrefs’ Site Audit. You tin spot the study I’ve created for this named “Orphan URLs.” There is 1 caveat here. As Ahrefs hasn’t discovered these URLs but Googlebot has, these URLs whitethorn not beryllium URLs we privation to nexus to due to the fact that they’re non-indexable. I urge copying and pasting these URLs utilizing the “Custom URL list” functionality erstwhile mounting up crawl sources for your Ahrefs project. This way, Ahrefs volition present see these orphan URLs recovered successful your log files and study immoderate issues to you successful your next crawl: Suppose you’ve implemented structured URLs that bespeak however you’ve organized your tract (e.g., /features/feature-page/). In that case, you tin besides analyze log files based connected the directory to spot if Googlebot is crawling definite sections of the tract much than others. I’ve implemented this benignant of investigation successful the “Directories — Overview” tab of the Google Sheet. You tin spot I’ve besides included information connected the fig of interior links to the directories, arsenic good arsenic full integrated traffic. You tin usage this to spot whether Googlebot is spending much clip crawling low-traffic directories than high-value ones. But again, carnivore successful caput this whitethorn occur, arsenic immoderate URLs wrong specific directories alteration much often than others. Still, it’s worthy further investigating if you spot an odd trend. In summation to this report, determination is besides a “Directories — Crawl trend” report if you privation to spot the crawl inclination per directory for your site. Head to the “CF cache status” tab, and you’ll spot a summary of however often Cloudflare is caching your files connected the edge servers. When Cloudflare caches contented (HIT successful the supra chart), the petition nary longer goes to your root server and is served straight from its planetary CDN. This results successful amended Core Web Vitals, particularly for planetary sites. Sidenote. It’s besides worthy having a caching setup connected your root server (such arsenic Varnish, Nginx FastCGI, oregon Redis full-page cache). This is truthful that adjacent erstwhile Cloudflare hasn’t cached a URL, you’ll inactive payment from immoderate caching. If you see a ample magnitude of “Miss” or “Dynamic” responses, I urge investigating further to recognize wherefore Cloudflare isn’t caching content. Common causes can be: Sidenote. I thoroughly recommend mounting up HTML edge-caching via Cloudflare, which importantly reduces TTFB. You tin bash this easy with WordPress and Cloudflare’s Automatic Platform Optimization. The last study (found successful the “Bots — Overview” tab) shows you which bots crawl your tract the most: In the “Bots — Crawl trend” report, you tin spot however that inclination has changed over time. This study tin assistance cheque if there’s an summation successful bot enactment connected your site. It’s besides adjuvant when you’ve precocious made a important change, specified as a URL migration, and privation to spot if bots person accrued their crawling to cod new data. You should present person a bully thought of the investigation you tin bash with your log files erstwhile auditing a site. Hopefully, you’ll find it casual to usage my template and bash this investigation yourself. Anything unsocial you’re doing with your log files that I haven’t mentioned? Tweet me.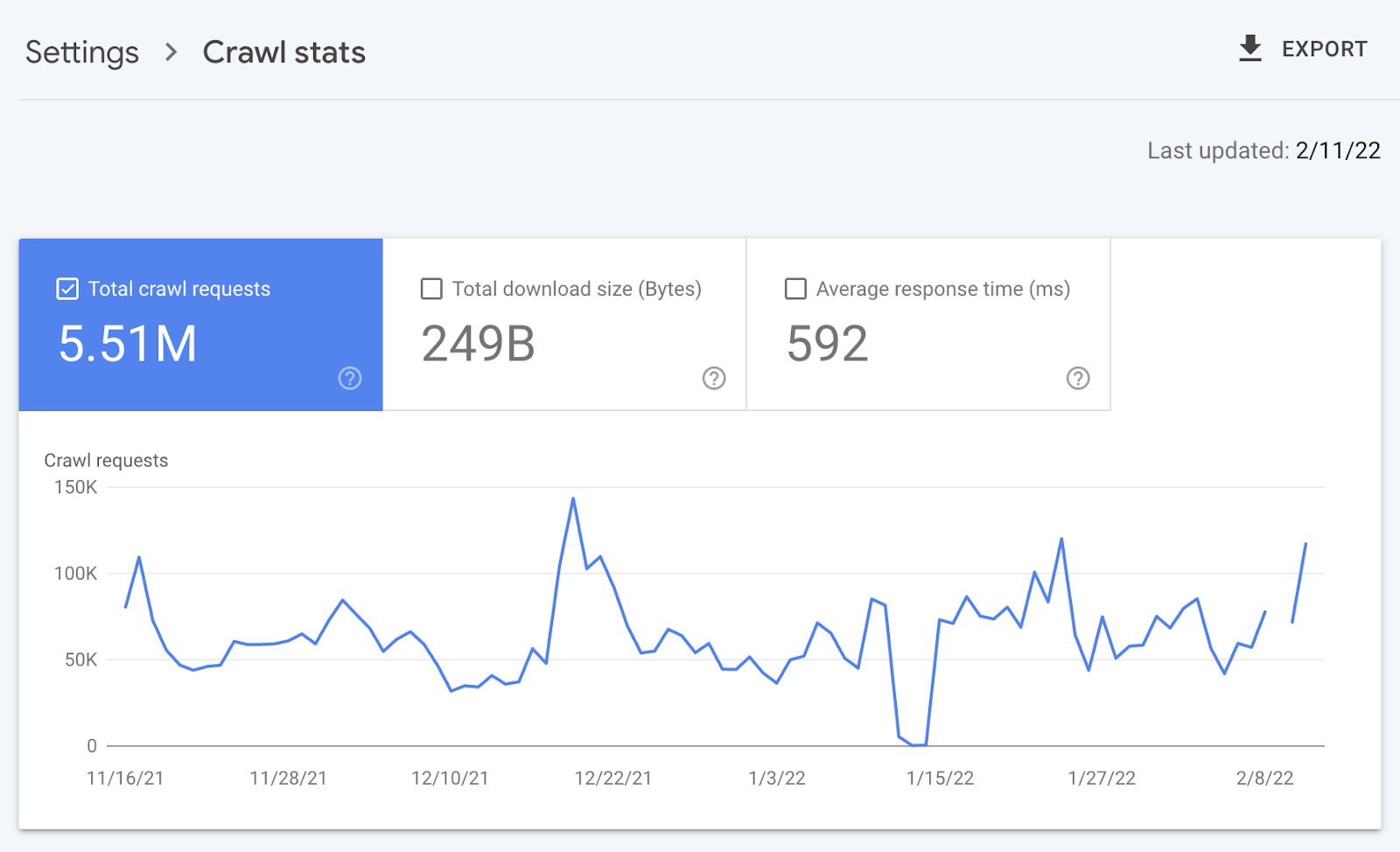
1. Start by mounting up Logflare (optional)
2. Verify Googlebot
I’m not utilizing Logflare
I’m utilizing Cloudflare/Logflare

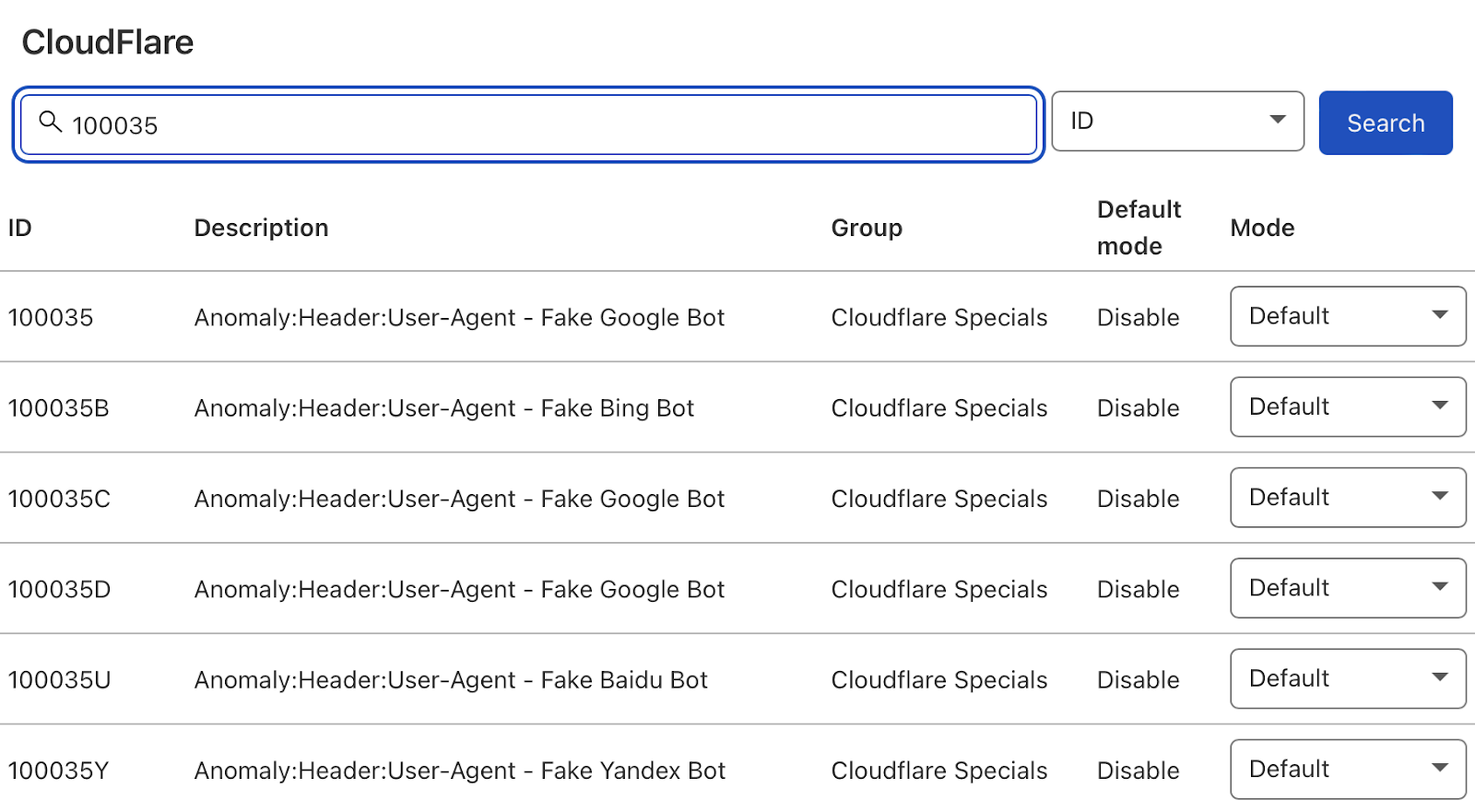
3. Extract information from log files

4. Add to Google Sheets
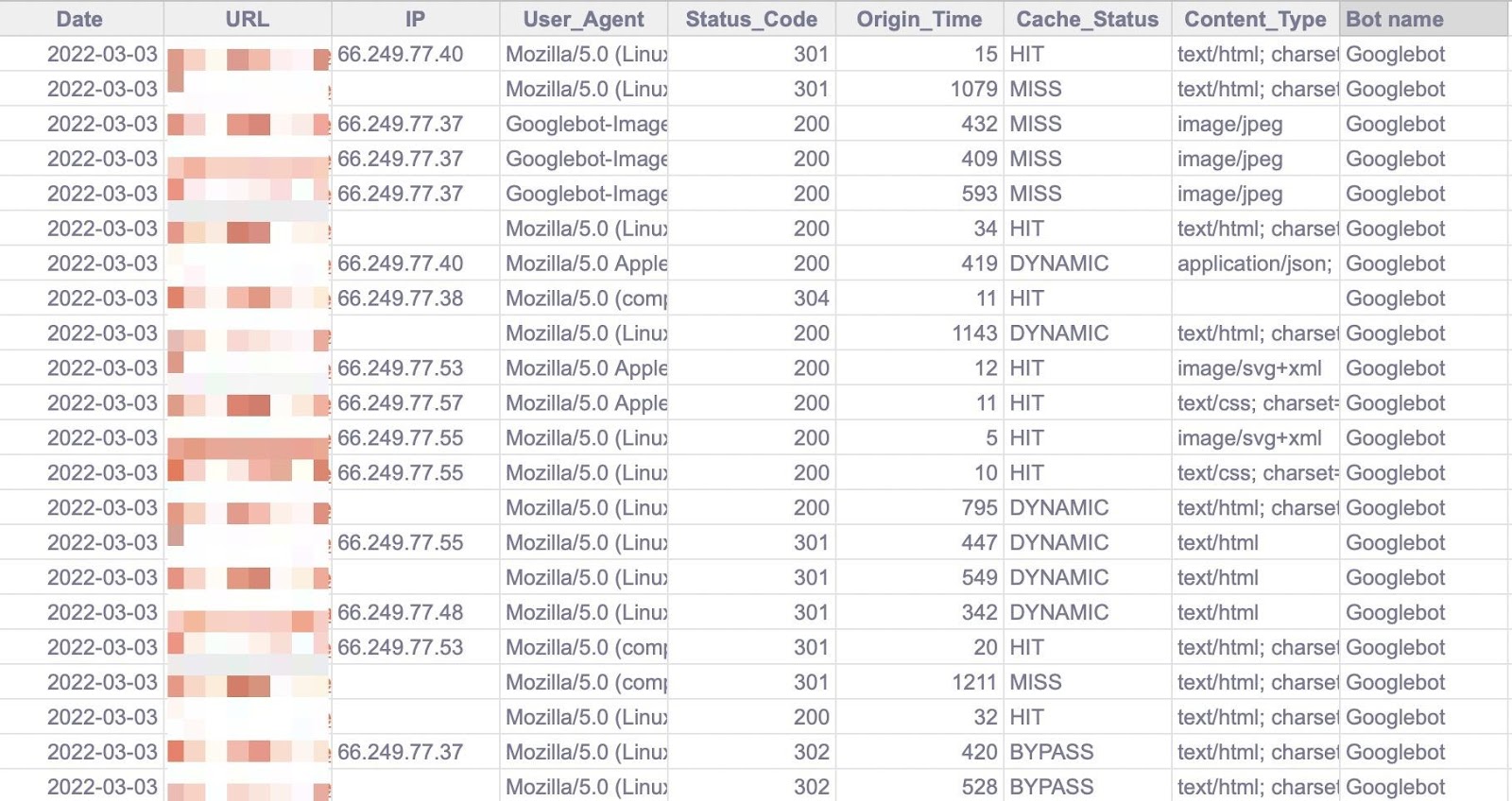
5. Add Ahrefs data
6. Check for presumption codes
7. Detect crawl fund wastage
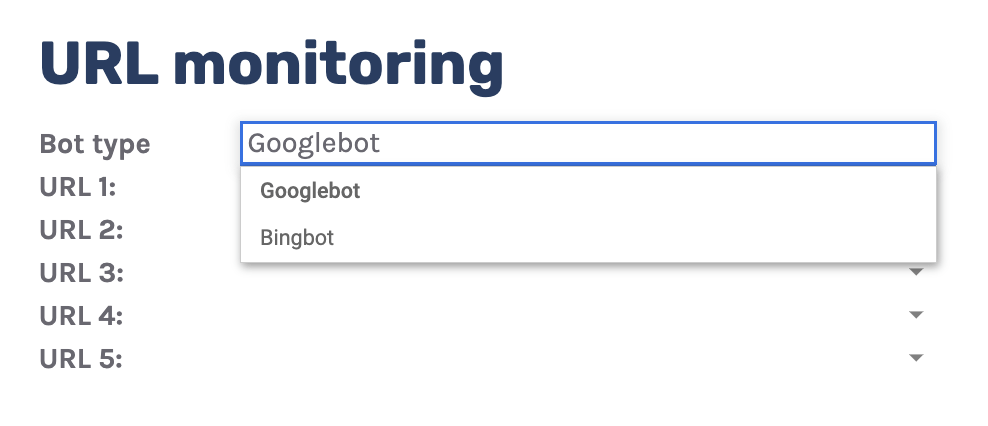
8. Monitor important URLs
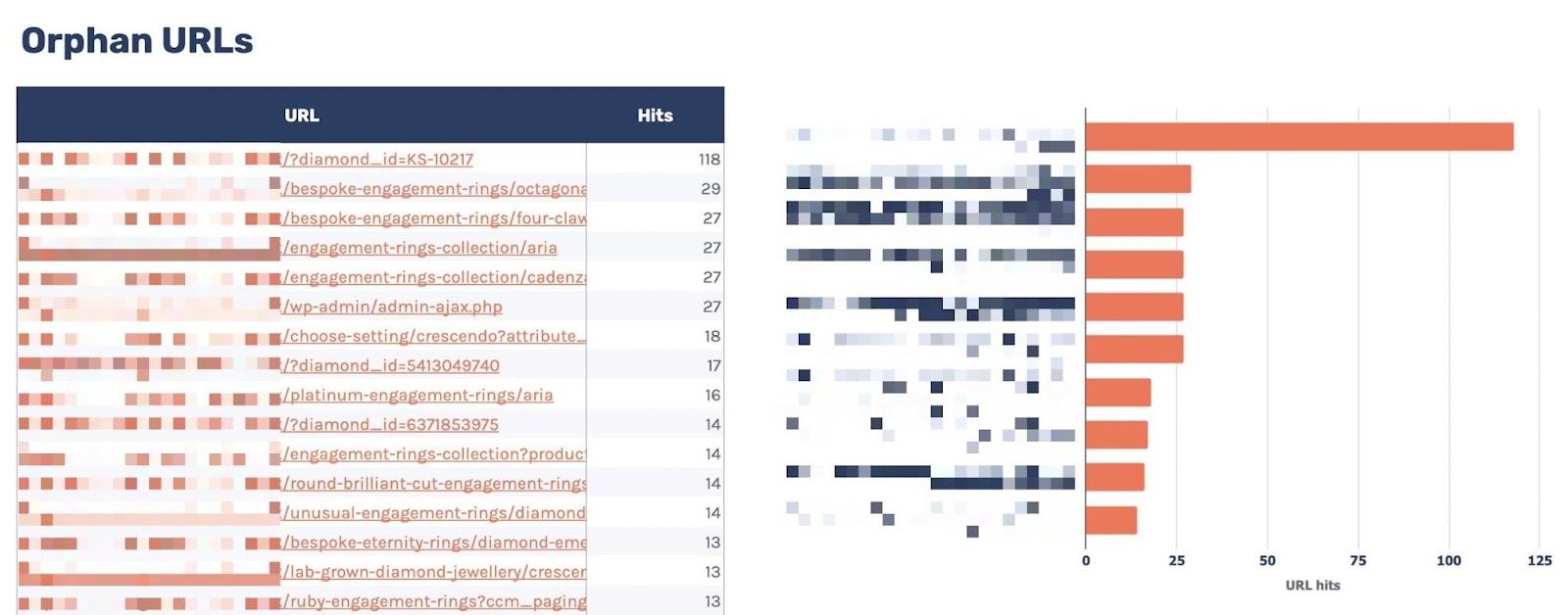
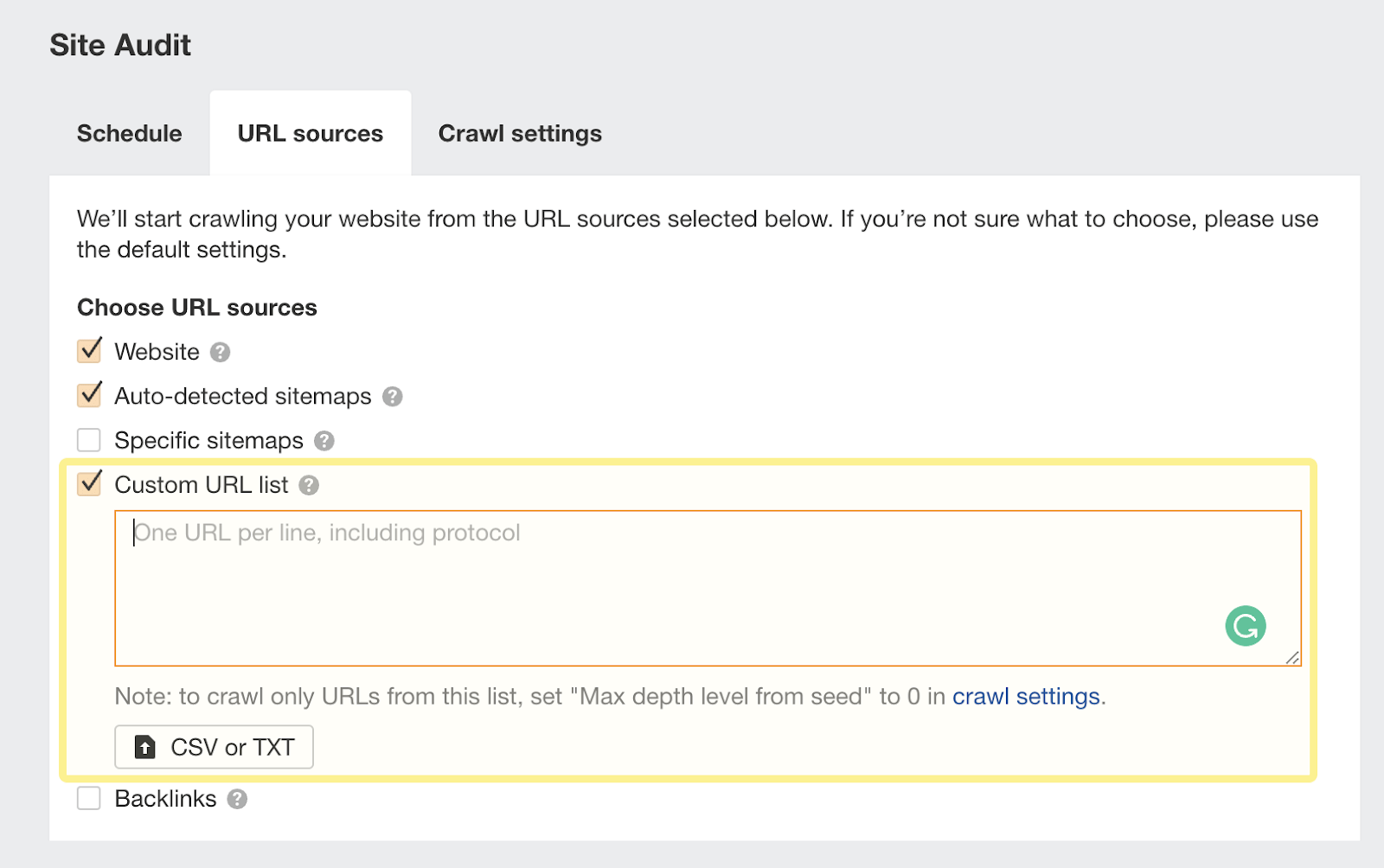
9. Find orphan URLs

10. Monitor crawling by directory
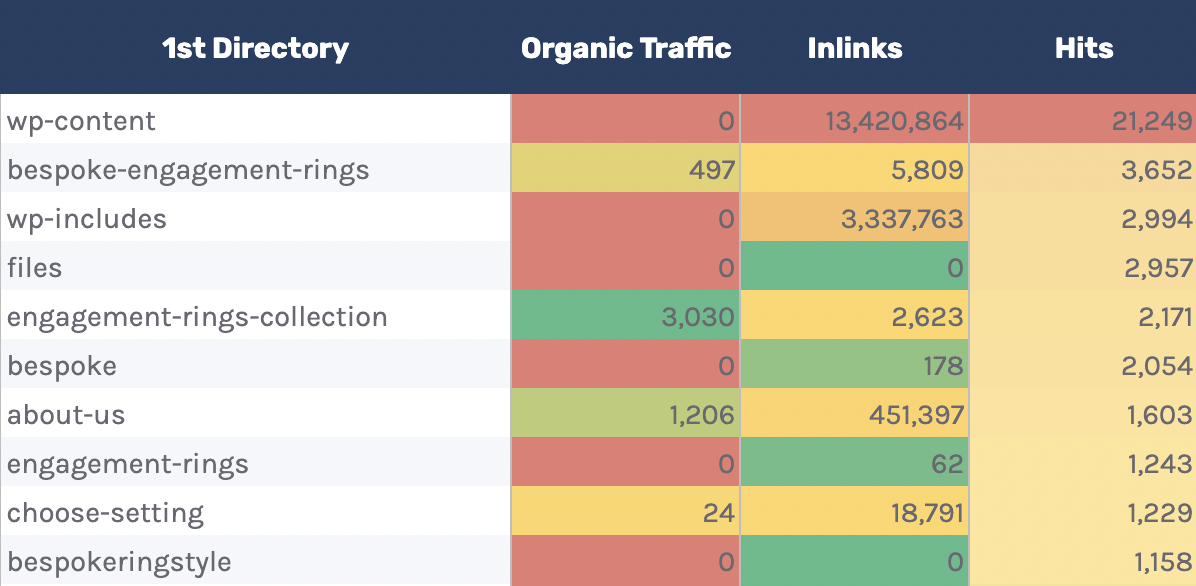
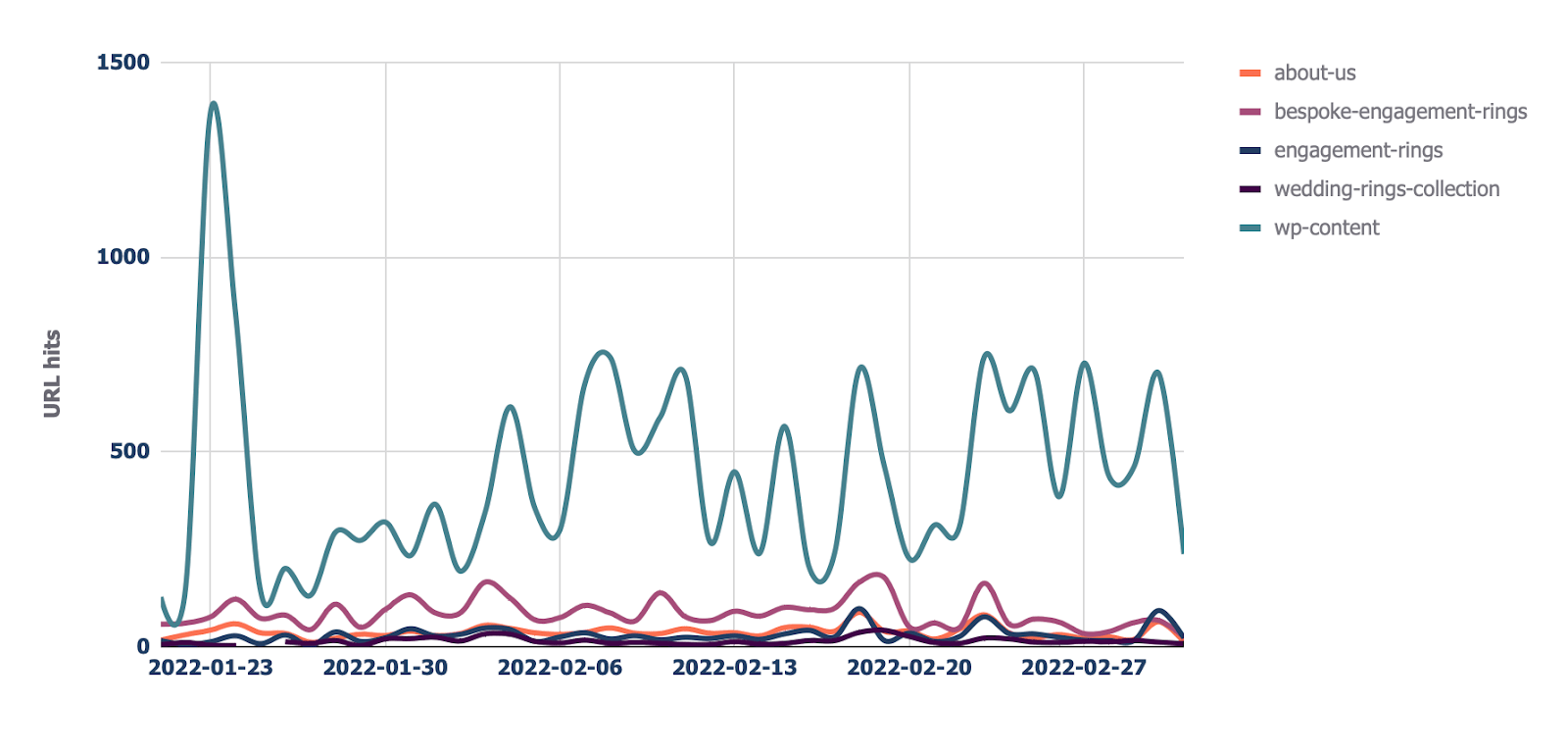
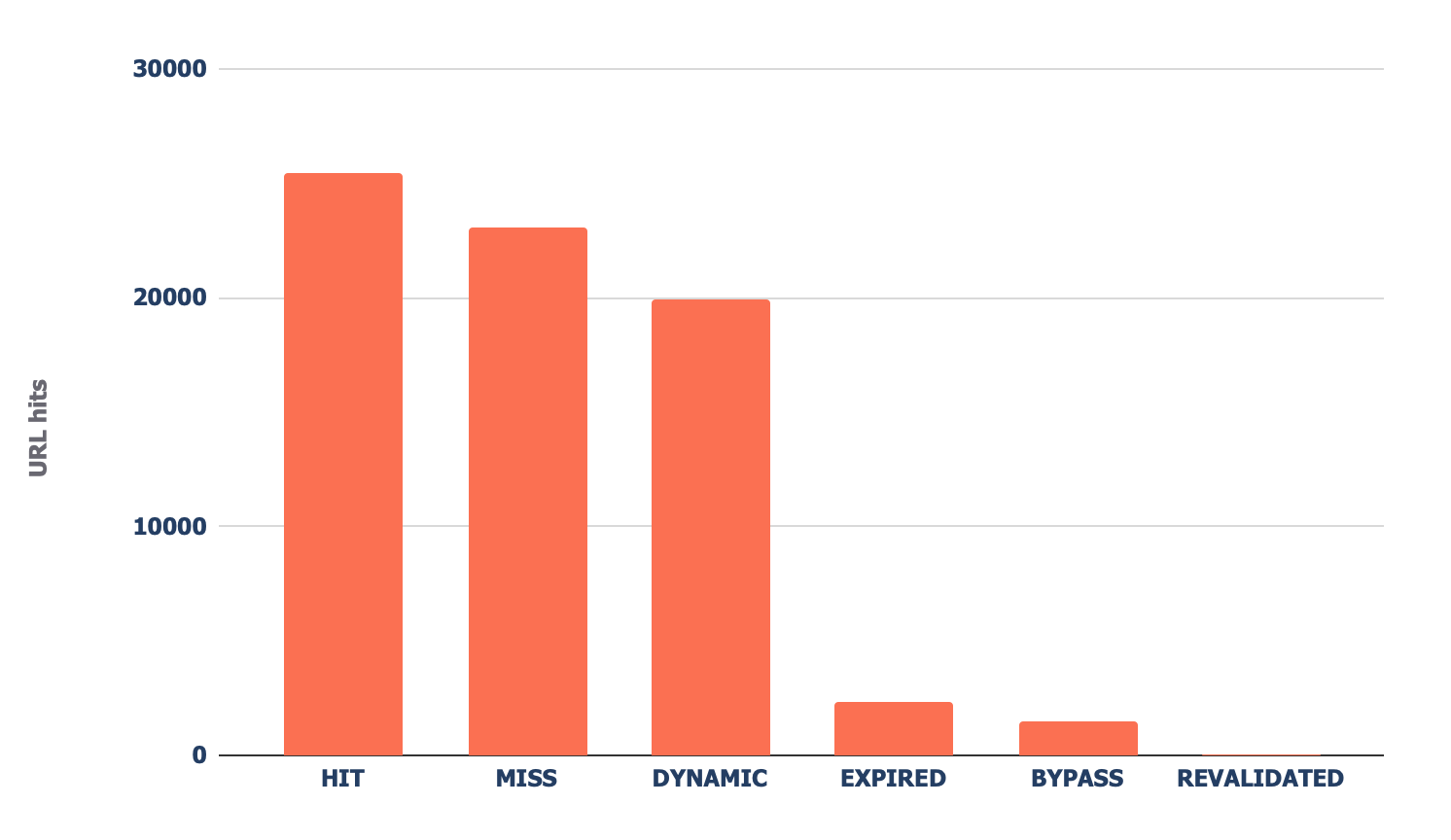
11. View Cloudflare cache ratios
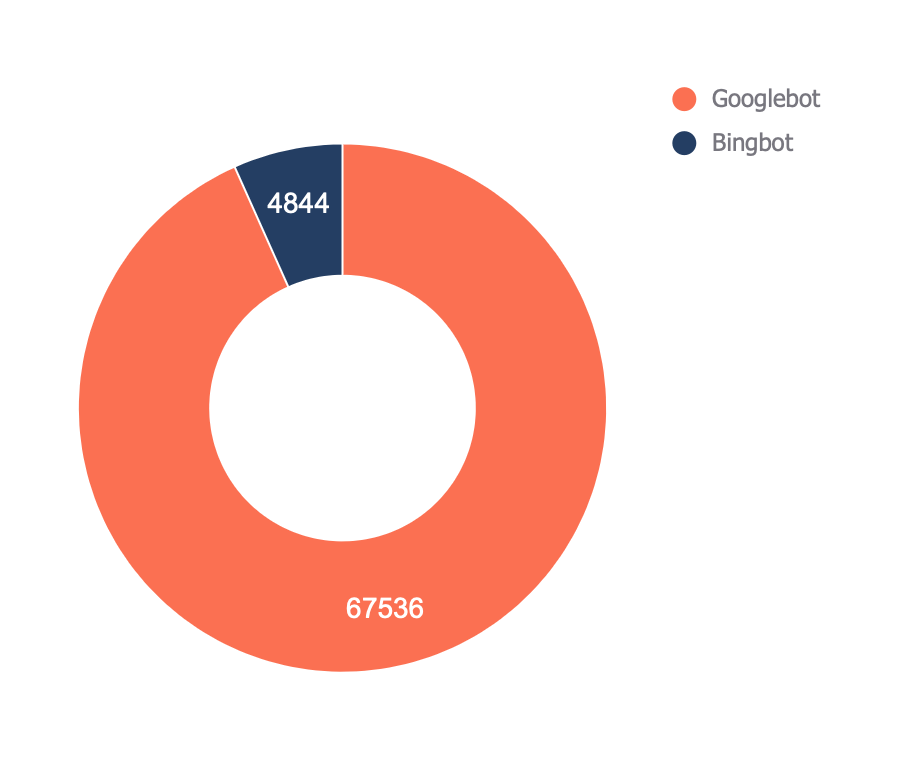
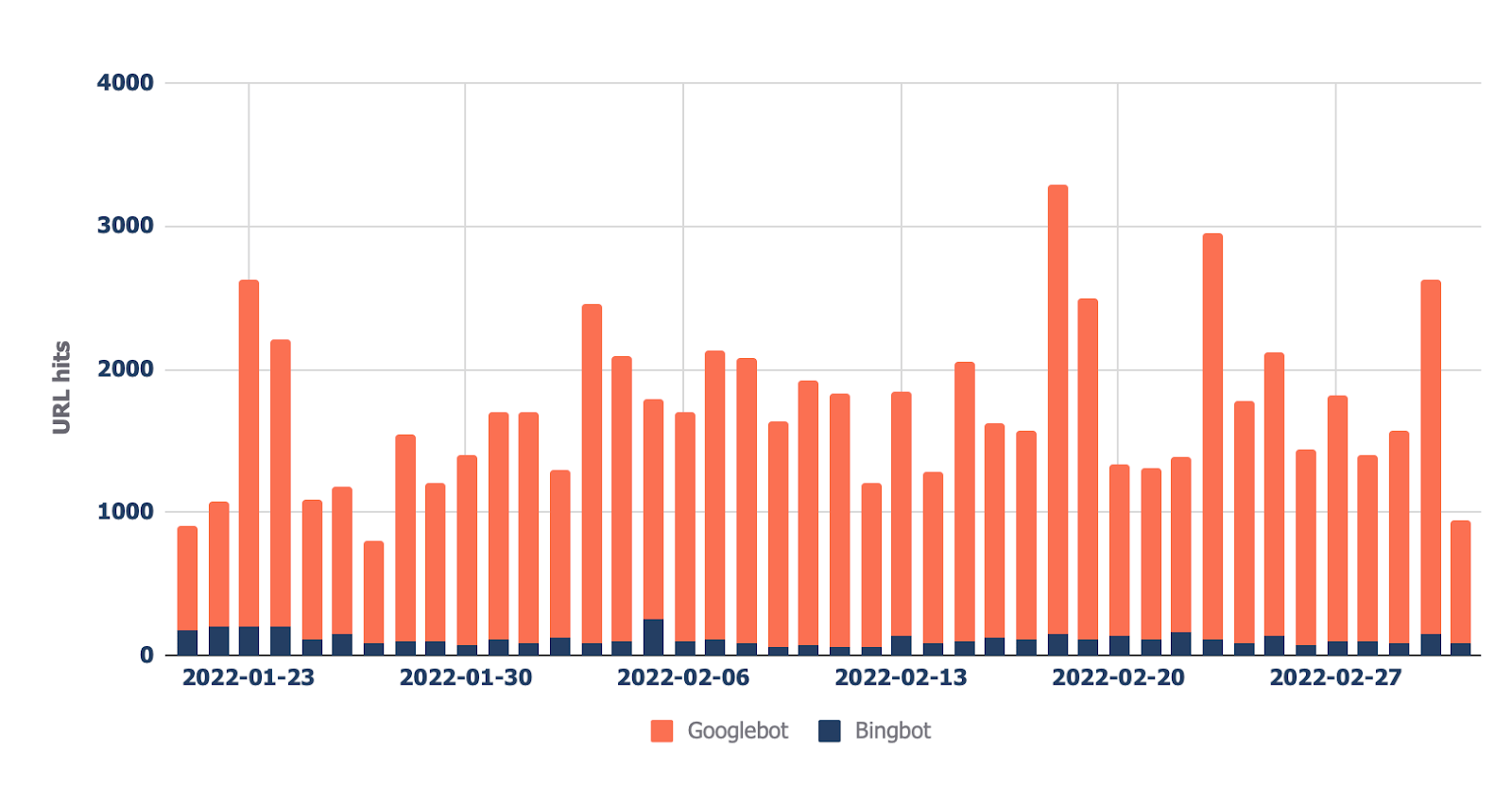
12. Check which bots crawl your tract the most
Final thoughts








 English (US)
English (US)