
ARTICLE AD BOX
Wondering wherefore immoderate of your pages don’t amusement up successful Google’s hunt results?
Crawlability problems could beryllium the culprits.
In this guide, we’ll screen what crawlability problems are, however they impact SEO, and however to hole them.
Let’s get started.
What Are Crawlability Problems?
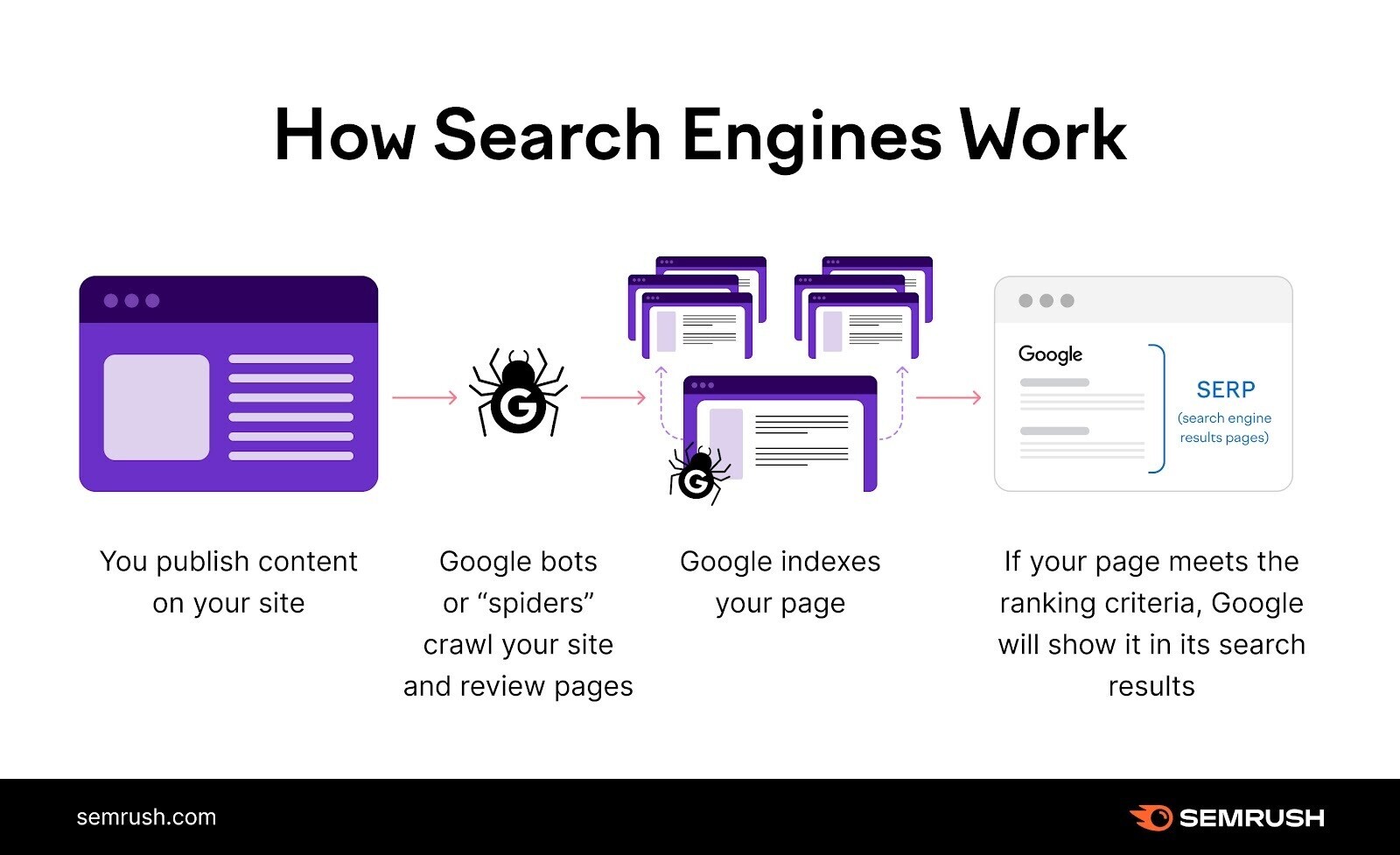
Crawlability problems are issues that forestall hunt engines from accessing your website’s pages.
Search engines similar Google usage automated bots to work and analyse your pages—this is called crawling.

But these bots whitethorn brushwood obstacles that hinder their quality to decently entree your pages if determination are crawlability problems.
Common crawlability problems include:
- Nofollow links (which archer Google not to travel the nexus oregon walk ranking spot to that page)
- Redirect loops (when 2 pages redirect to each different to make an infinite loop)
- Bad tract structure
- Slow tract speed
How Do Crawlability Issues Affect SEO?
Crawlability problems tin drastically impact your SEO game.
Why?
Because crawlability problems marque it truthful that immoderate (or all) of your pages are practically invisible to hunt engines.
They can’t find them. Which means they can’t scale them—i.e., prevention them successful a database to show successful applicable hunt results.
This means a imaginable nonaccomplishment of hunt motor (organic) postulation and conversions.
Your pages indispensable beryllium both crawlable and indexable to fertile successful hunt engines.
15 Crawlability Problems & How to Fix Them
1. Pages Blocked In Robots.txt
Search engines archetypal look astatine your robots.txt file. This tells them which pages they should and shouldn’t crawl.
If your robots.txt record looks similar this, it means your full website is blocked from crawling:
User-agent: *
Disallow: /
Fixing this occupation is simple. Just regenerate the “disallow” directive with “allow.” Which should alteration hunt engines to entree your full website.
Like this:
User-agent: *
Allow: /
In different cases, lone definite pages oregon sections are blocked. For instance:
User-agent: *
Disallow: /products/
Here, each the pages successful the “products” subfolder are blocked from crawling.
Solve this occupation by removing the subfolder oregon leafage specified—search engines disregard the bare “disallow” directive.
User-agent: *
Disallow:
Or you could usage the “allow” directive alternatively of “disallow” to instruct hunt engines to crawl your full tract similar we did earlier.
2. Nofollow Links
The nofollow tag tells hunt engines not to crawl the links connected a webpage.
And the tag looks similar this:
<meta name="robots" content="nofollow">
If this tag is contiguous connected your pages, the different pages that they nexus to mightiness not get crawled. Which creates crawlability problems connected your site.
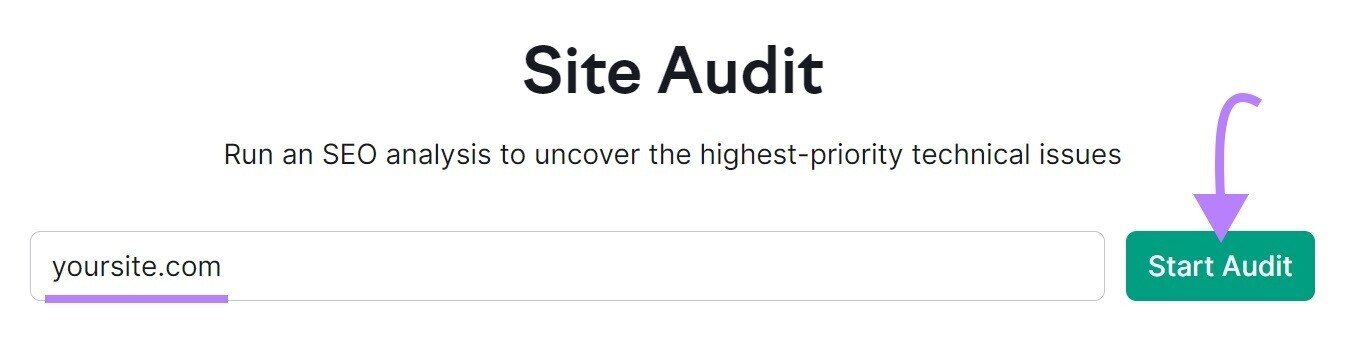
Check for nofollow links similar this with Semrush’s Site Audit tool.
Open the tool, participate your website, and click “Start Audit.”
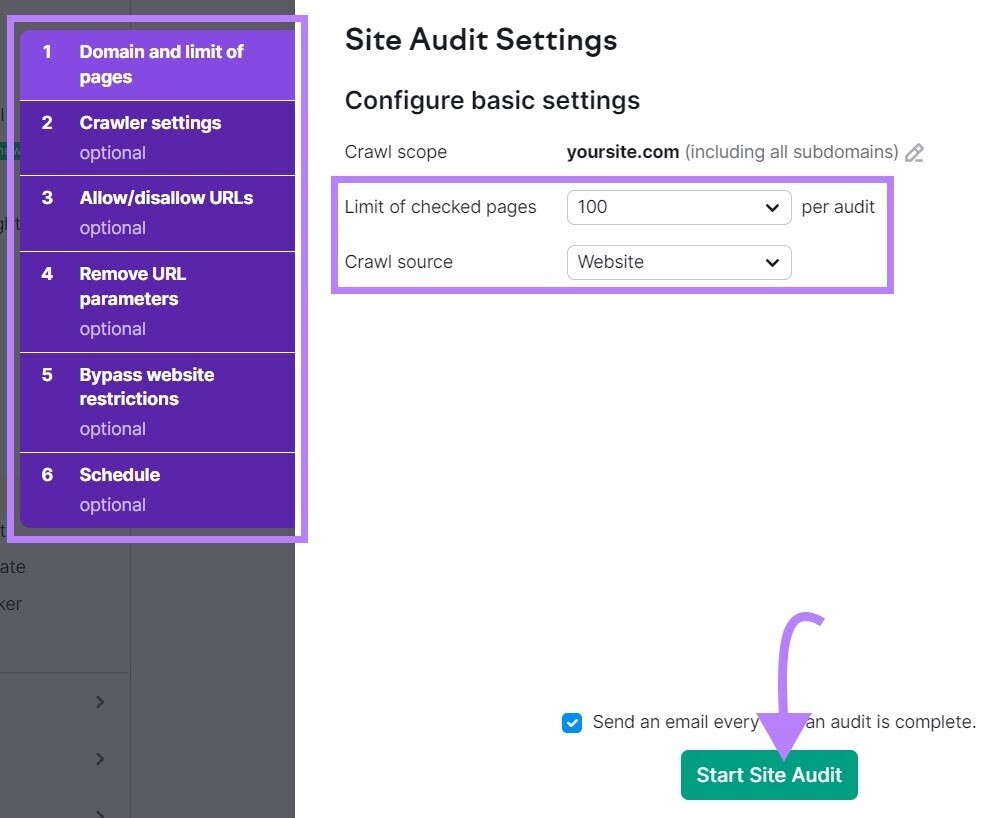
The “Site Audit Settings” model volition appear.
From here, configure the basal settings and click “Start Site Audit.”
Once the audit is complete, navigate to the “Issues” tab and hunt for “nofollow.”
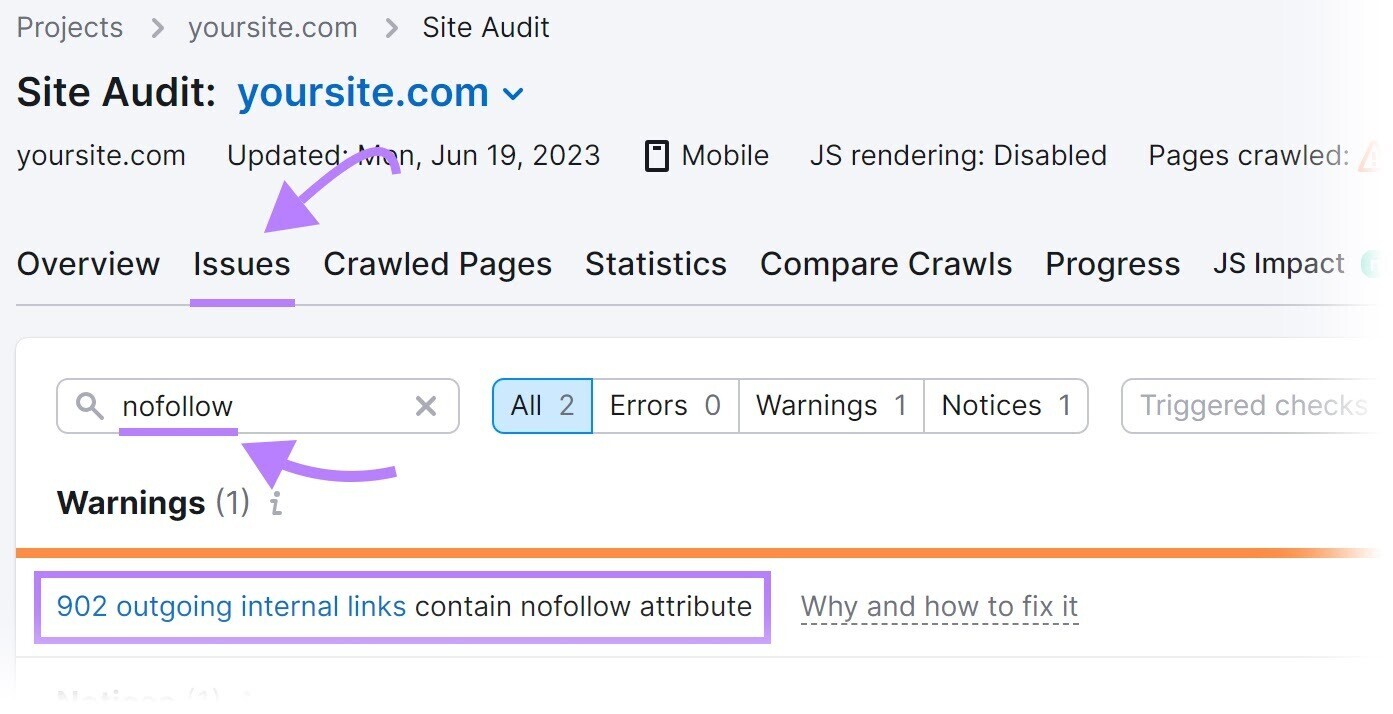
If nofollow links are detected, click “# outgoing interior links incorporate nofollow attribute” to presumption a database of pages that person a nofollow tag.
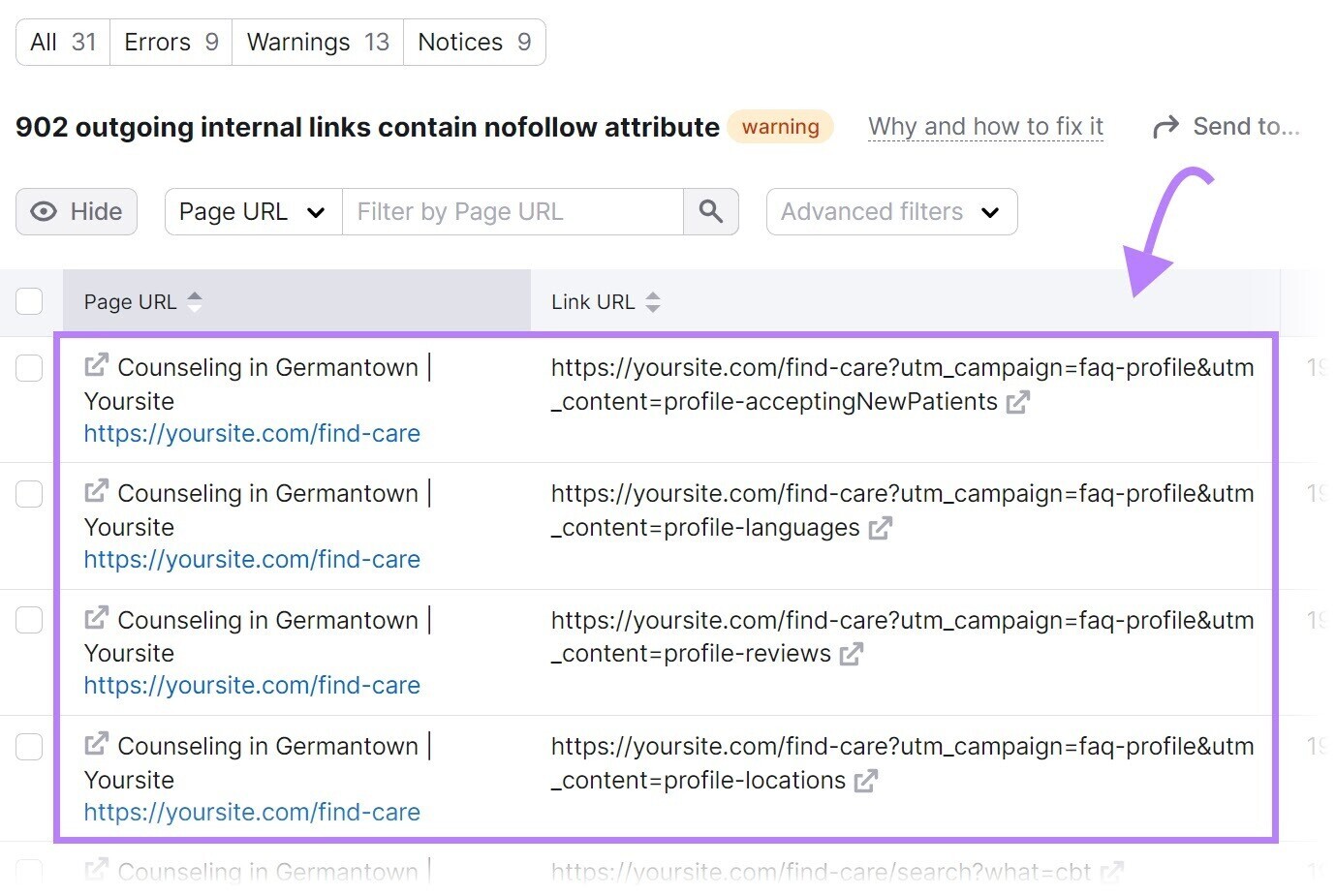
Review the pages and region the nofollow tags if they shouldn’t beryllium there.
3. Bad Site Architecture
Site architecture is however your pages are organized crossed your website.
A bully tract architecture ensures each leafage is conscionable a fewer clicks distant from the homepage—and that determination are nary orphan pages (i.e., pages with no internal links pointing to them). To assistance hunt engines easy entree each pages.
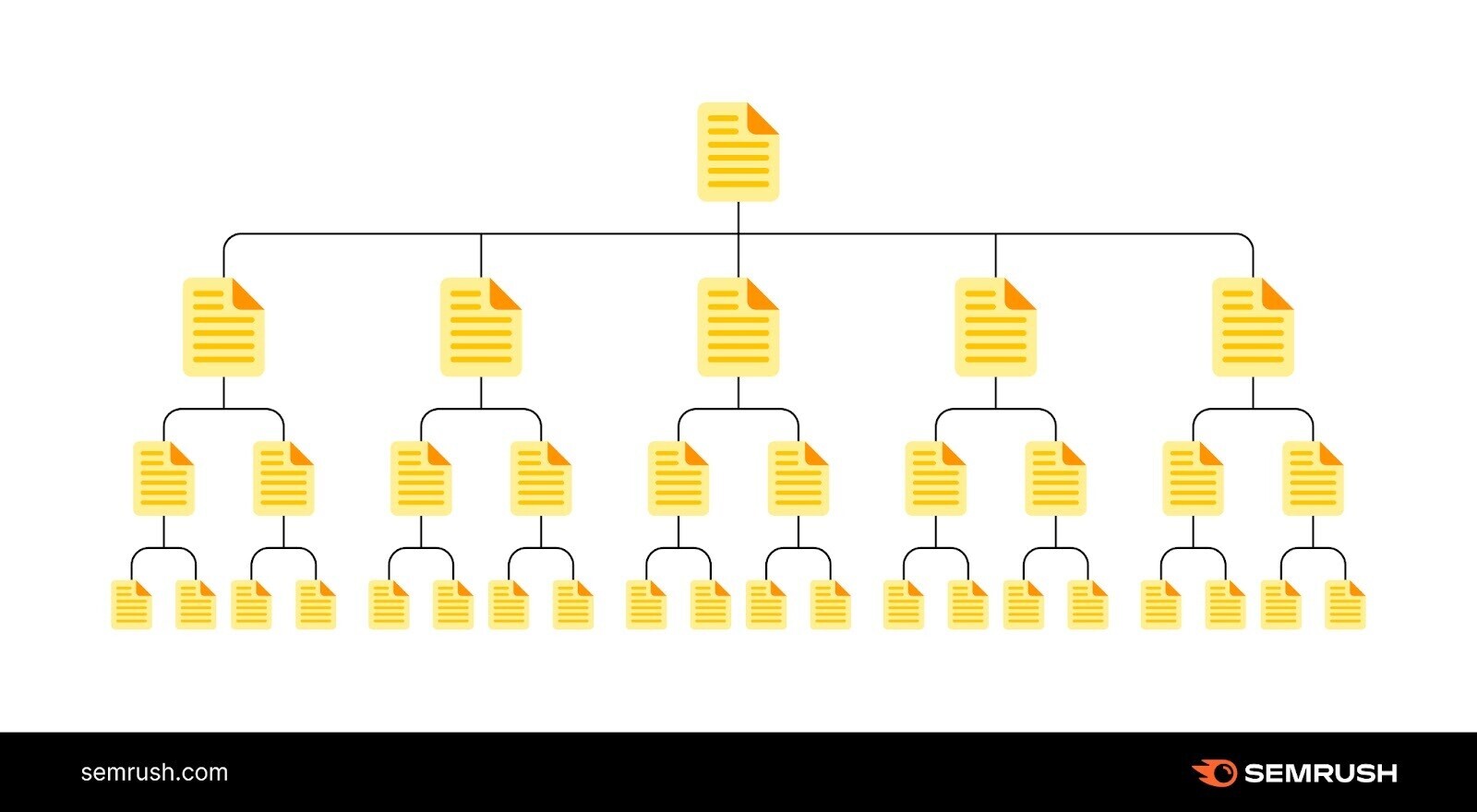
But a atrocious tract site architecture tin make crawlability issues.
Notice the illustration tract operation depicted below. It has orphan pages.
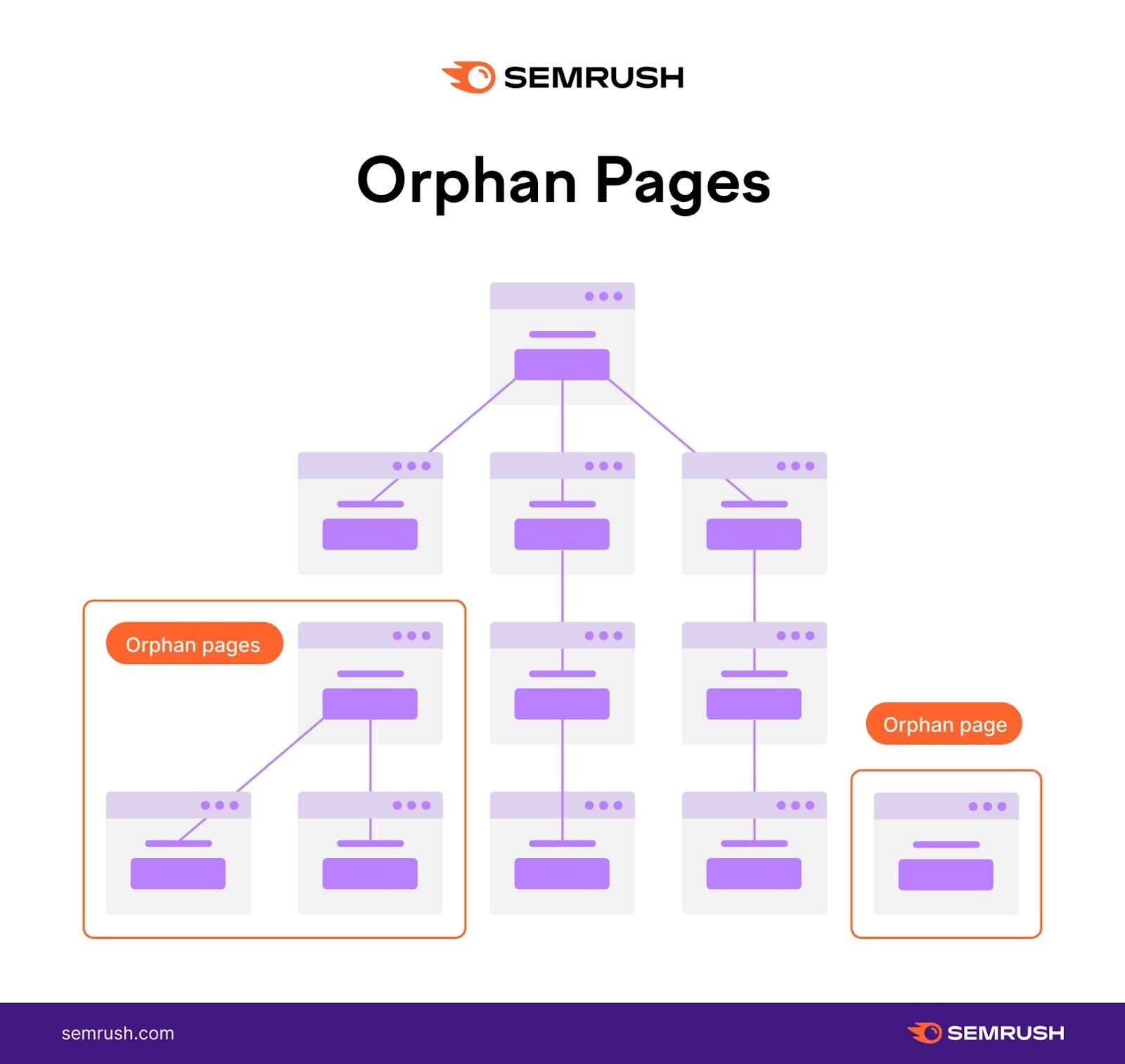
Because there’s nary linked way to them from the homepage, they whitethorn spell unnoticed erstwhile hunt engines crawl the site.
The solution is straightforward: Create a tract operation that logically organizes your pages successful a hierarchy done interior links.
Like this:
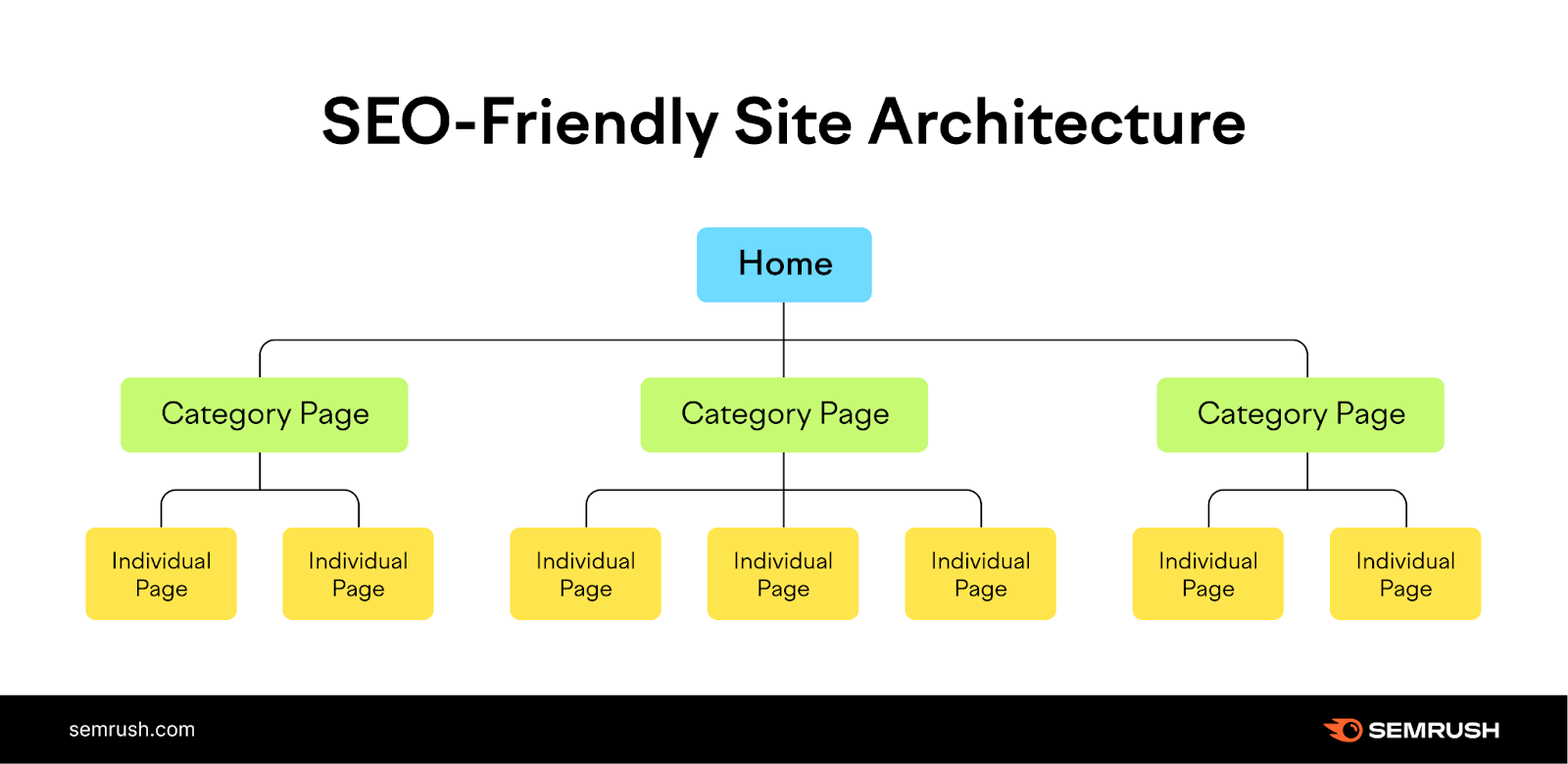
In the illustration above, the homepage links to class pages, which past nexus to idiosyncratic pages connected your site.
And this provides a wide way for crawlers to find each your important pages.
4. Lack of Internal Links
Pages without interior links tin make crawlability problems.
Search engines volition person occupation discovering those pages.
So, place your orphan pages. And adhd interior links to them to debar crawlability issues.
Find orphan pages utilizing Semrush’s Site Audit tool.
Configure the tool to tally your archetypal audit.
Then, spell to the “Issues” tab and hunt for “orphan.”
You’ll spot whether determination are immoderate orphan pages contiguous connected your site.
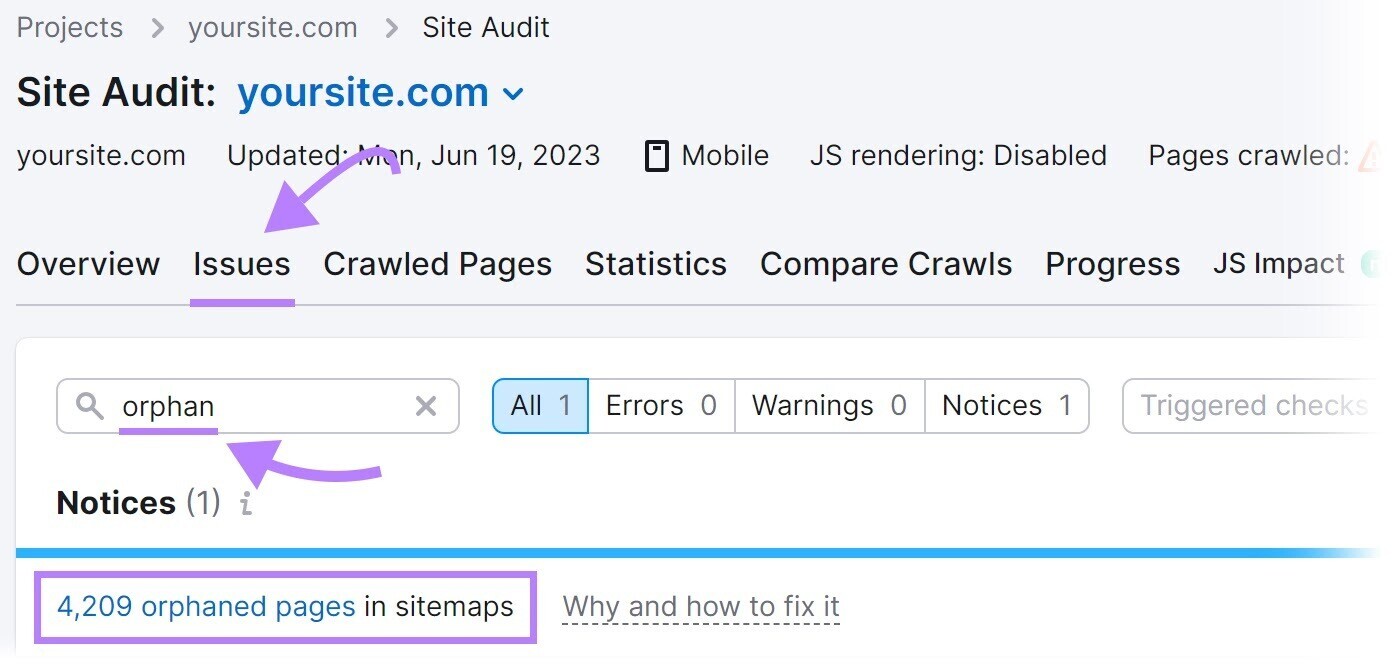
To lick this problem, adhd interior links to orphan pages from different applicable pages connected your site.
5. Bad Sitemap Management
A sitemap provides a database of pages connected your tract that you privation hunt engines to crawl, index, and rank.
If your sitemap excludes immoderate pages you privation to beryllium found, they mightiness spell unnoticed. And make crawlability issues. A instrumentality specified as XML Sitemaps Generator tin assistance you see each pages meant to beryllium crawled.
Enter your website URL, and the instrumentality volition make a sitemap for you automatically.
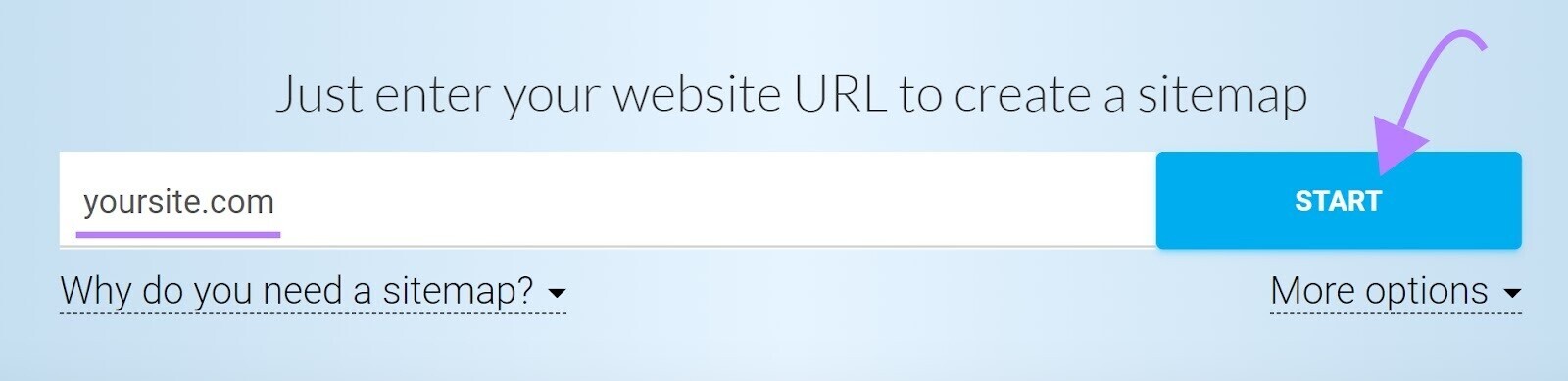
Then, prevention the record arsenic “sitemap.xml” and upload it to the basal directory of your website.
For example, if your website is www.example.com, past your sitemap URL should beryllium accessed astatine www.example.com/sitemap.xml.
Finally, taxable your sitemap to Google successful your Google Search Console account.
To bash that, access your account.
Click “Sitemaps” successful the left-hand menu. Then, participate your sitemap URL and click “Submit.”

6. ‘Noindex’ Tags
A “noindex” meta robots tag instructs hunt engines not to scale a page.
And the tag looks similar this:
<meta name="robots" content="noindex">
Although the noindex tag is intended to power indexing, it tin make crawlability issues if you permission it connected your pages for a agelong time.
Google treats long-term “noindex” tags arsenic nofollow tags, arsenic confirmed by Google’s John Mueller.
Over time, Google volition halt crawling the links connected those pages altogether.
So, if your pages aren’t getting crawled, semipermanent noindex tags could beryllium the culprit.
Identify these pages utilizing Semrush’s Site Audit tool.
Set up a project successful the instrumentality to tally your archetypal crawl.
Once it’s complete, caput implicit to the “Issues” tab and hunt for “noindex.”
The instrumentality volition database pages connected your tract with a “noindex” tag.
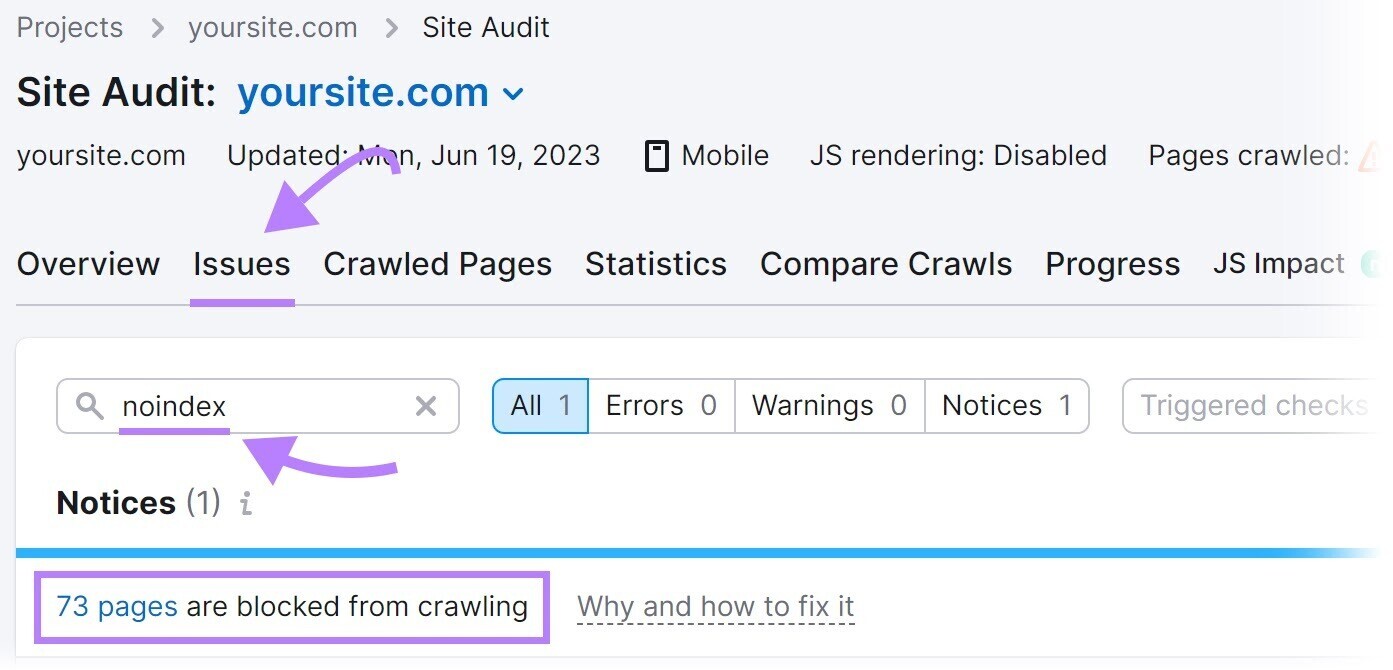
Review these pages and region the “noindex” tag wherever appropriate.
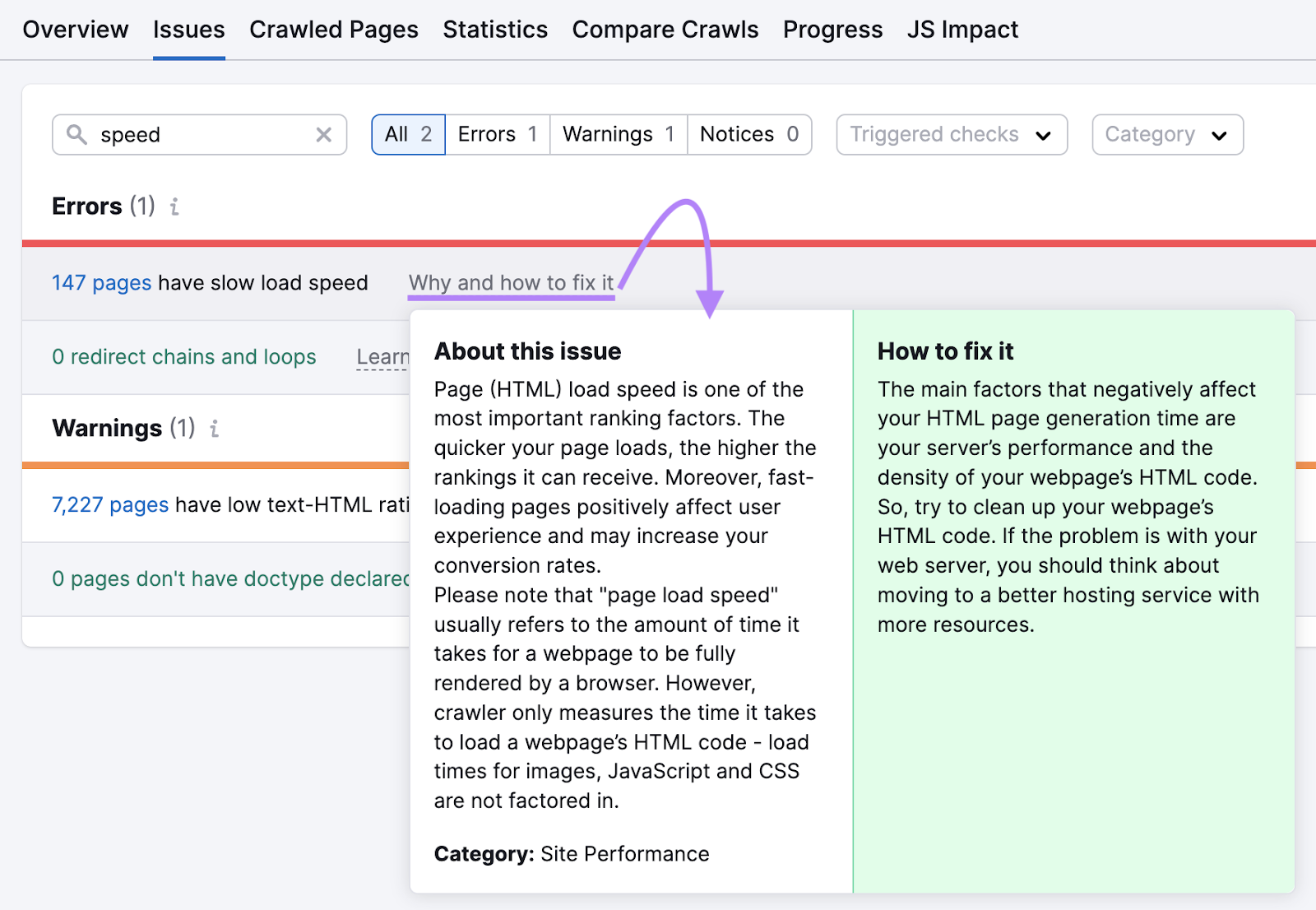
7. Slow Site Speed
When hunt motor bots sojourn your site, they person constricted clip and resources to give to crawling—commonly referred to arsenic a crawl budget.
Slow tract velocity means it takes longer for pages to load. And reduces the fig of pages bots tin crawl wrong that crawl session.
Which means important pages could beryllium excluded.
Work to lick this occupation by improving your wide website show and speed.
Start with our usher to page velocity optimization.
8. Internal Broken Links
Internal broken links are hyperlinks that constituent to dormant pages connected your site.
They instrumentality a 404 mistake similar this:
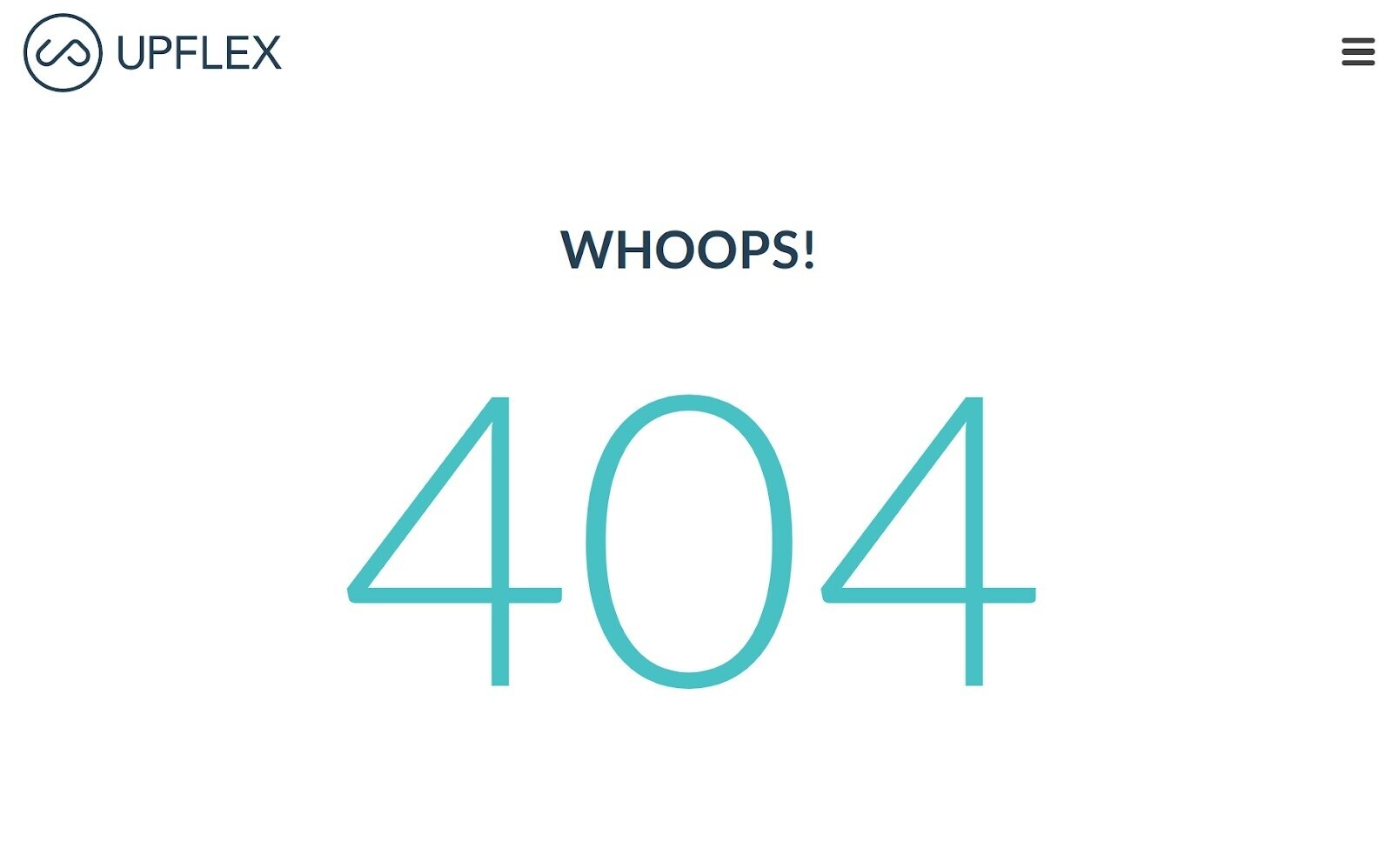
Broken links tin person a important interaction connected website crawlability. Because they forestall hunt motor bots from accessing the linked pages.
To find breached links connected your site, usage the Site Audit tool.
Navigate to the “Issues” tab and hunt for “broken.”
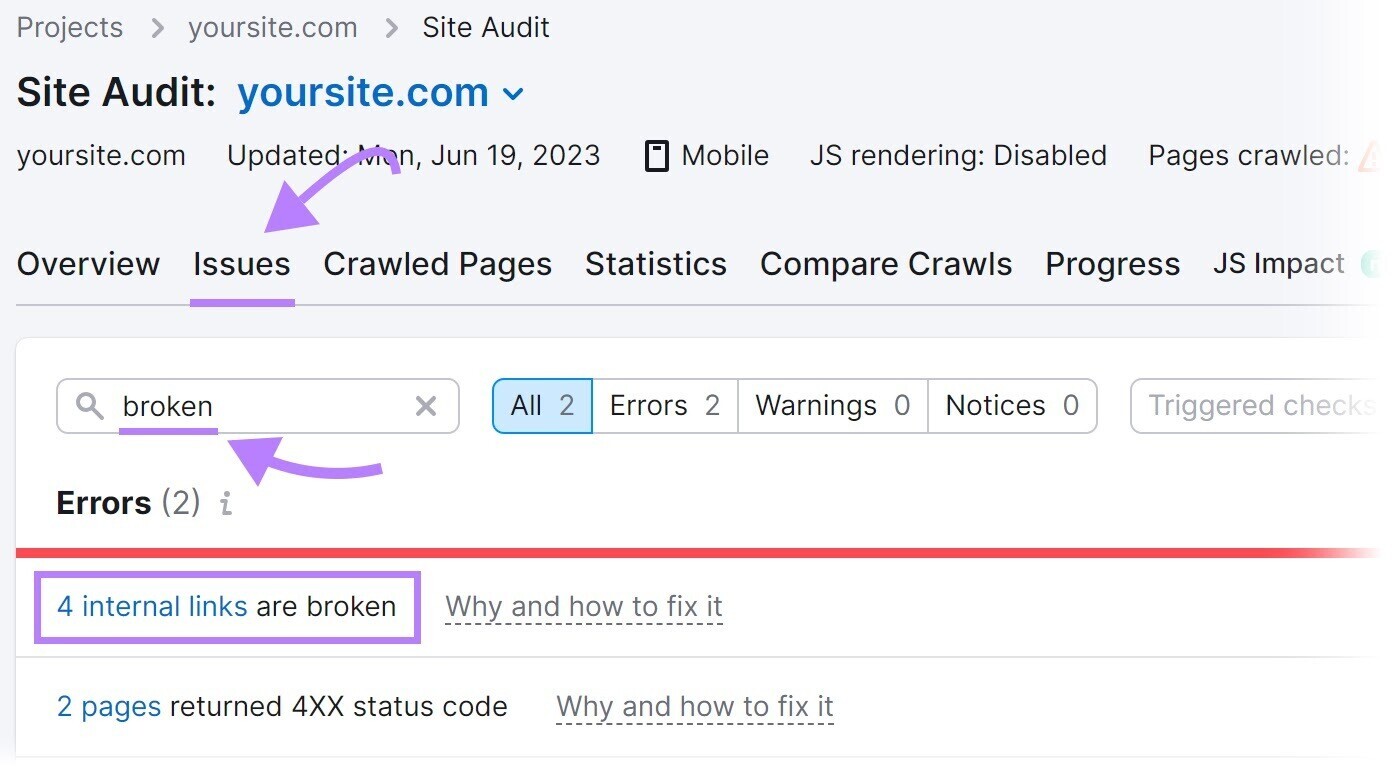
Next, click “# interior links are broken.” And you’ll spot a study listing each your breached links.
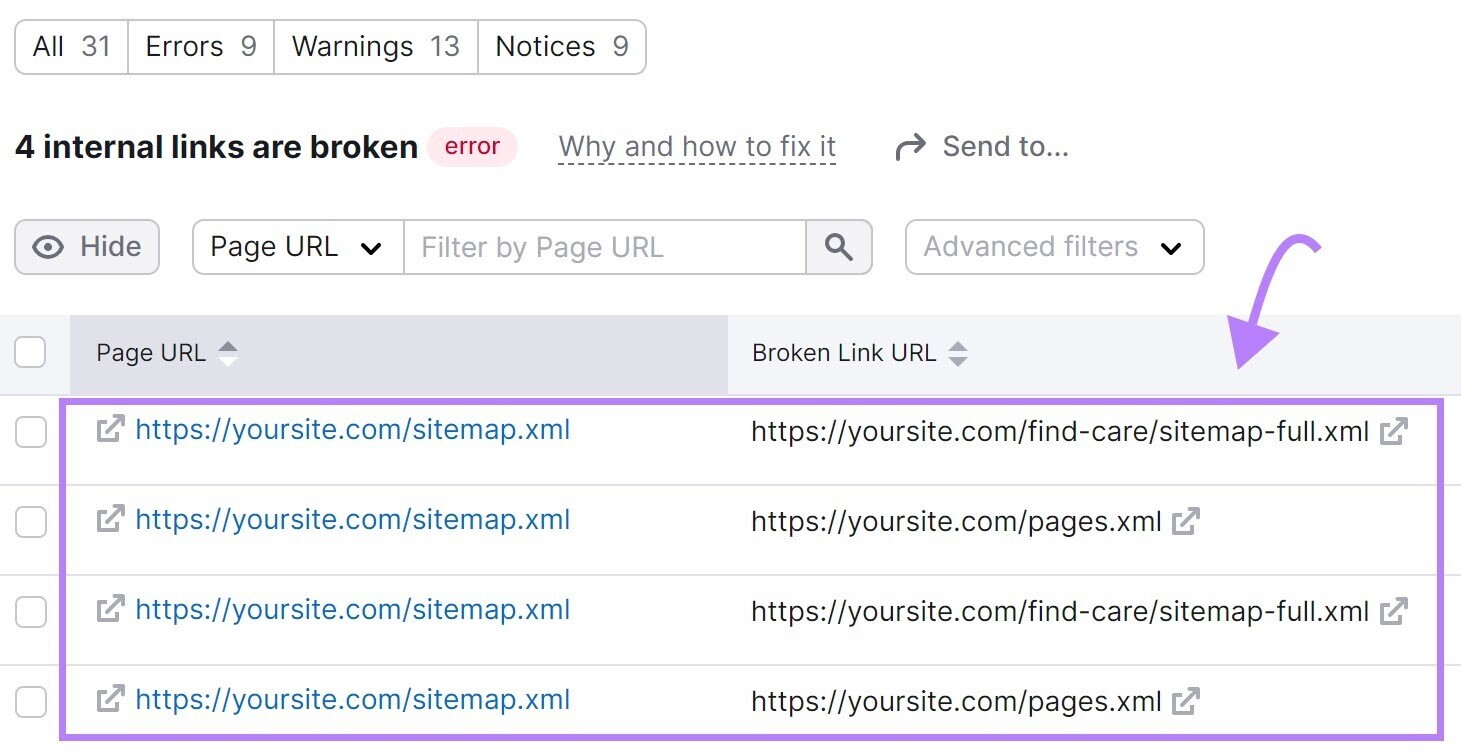
To hole these breached links, substitute a antithetic link, reconstruct the missing page, oregon adhd a 301 redirect to different applicable leafage connected your site.
9. Server-Side Errors
Server-side errors (like 500 HTTP presumption codes) disrupt the crawling process due to the fact that they mean the server couldn't fulfill the request. Which makes it hard for bots to crawl your website's content.
Semrush’s Site Audit instrumentality tin assistance you lick for server-side errors.
Search for “5xx” successful the “Issues” tab.
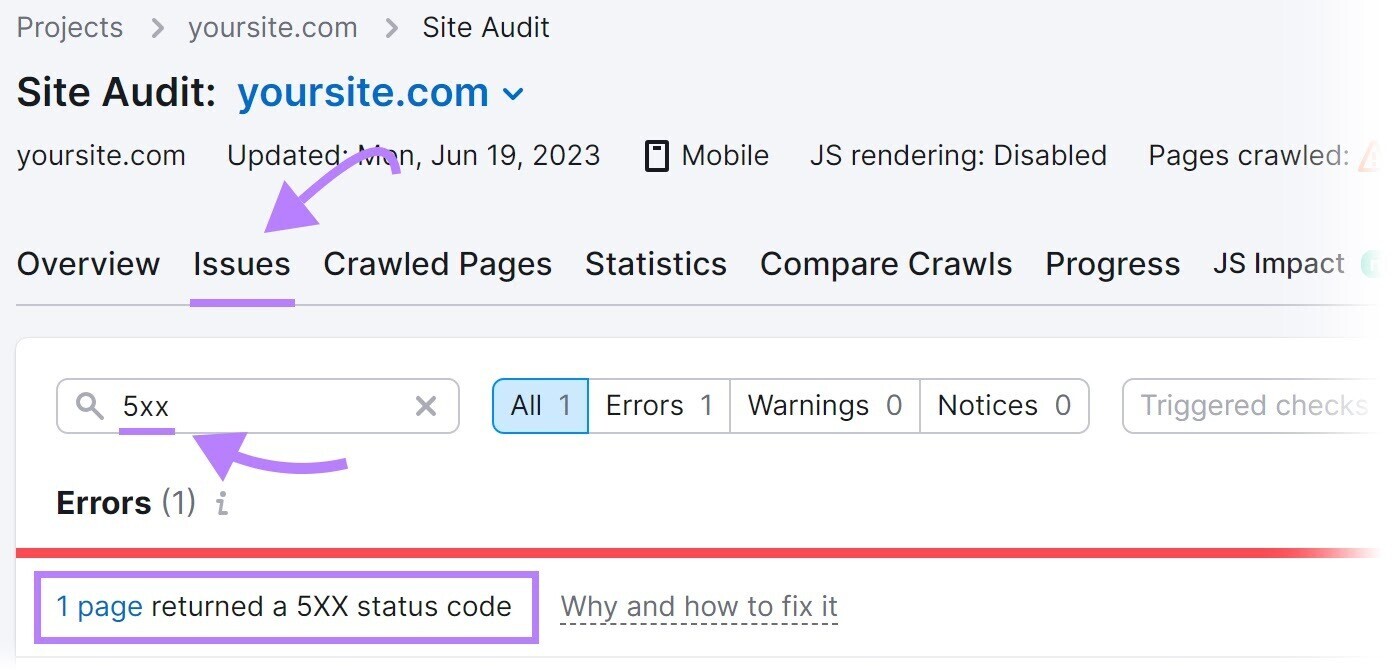
If errors are present, click “# pages returned a 5XX presumption code” to presumption a implicit database of affected pages.
Then, nonstop this database to your developer to configure the server properly.
10. Redirect Loops
A redirect loop is erstwhile 1 leafage redirects to another, which past redirects backmost to the archetypal page. And forms a continuous loop.
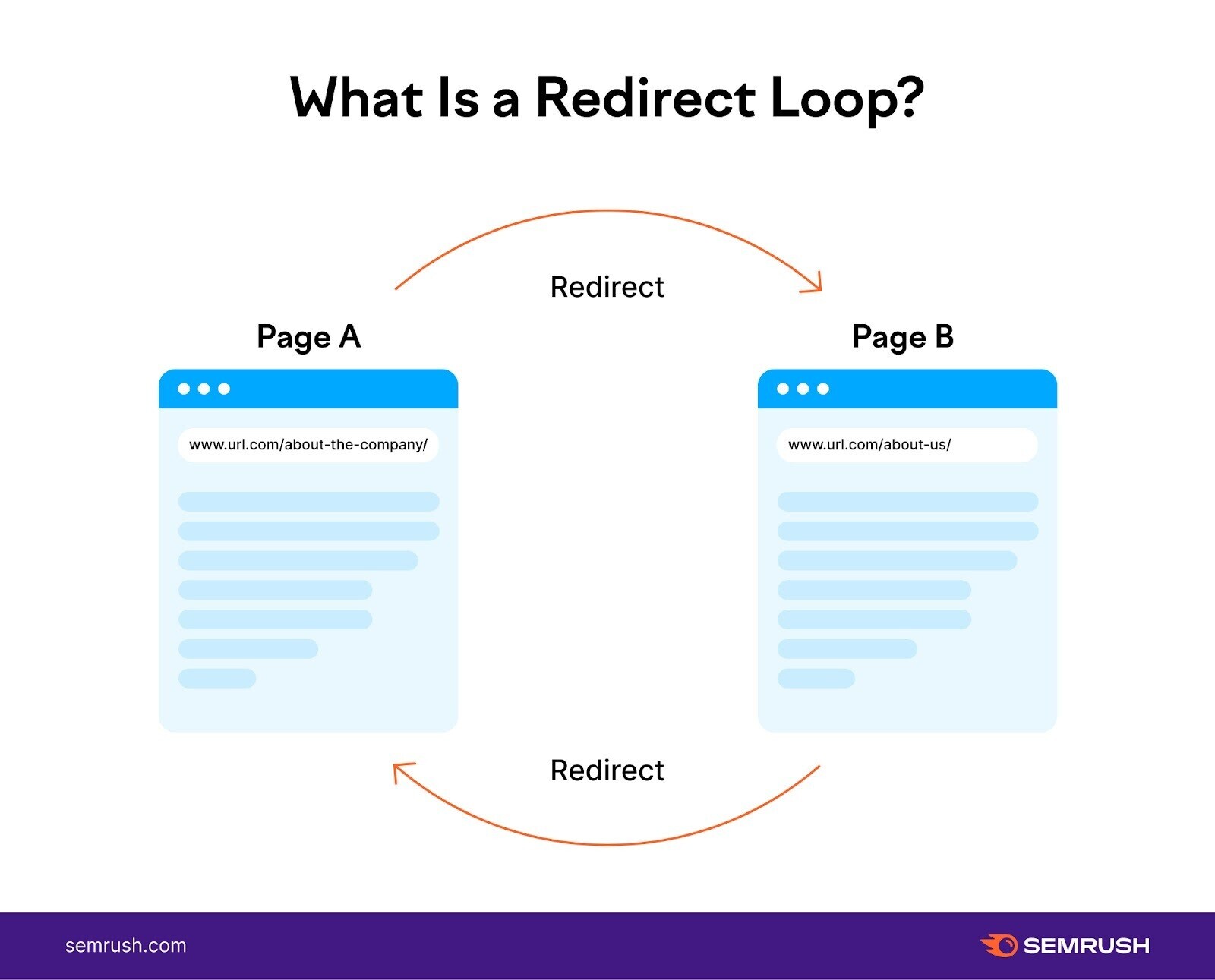
Redirect loops forestall hunt motor bots from reaching a last destination by trapping them successful an endless rhythm of redirects betwixt 2 (or more) pages. Which wastes important crawl fund clip that could beryllium spent connected important pages.
Solve this by identifying and fixing redirect loops connected your tract with the Site Audit tool.
Search for “redirect” successful the “Issues” tab.
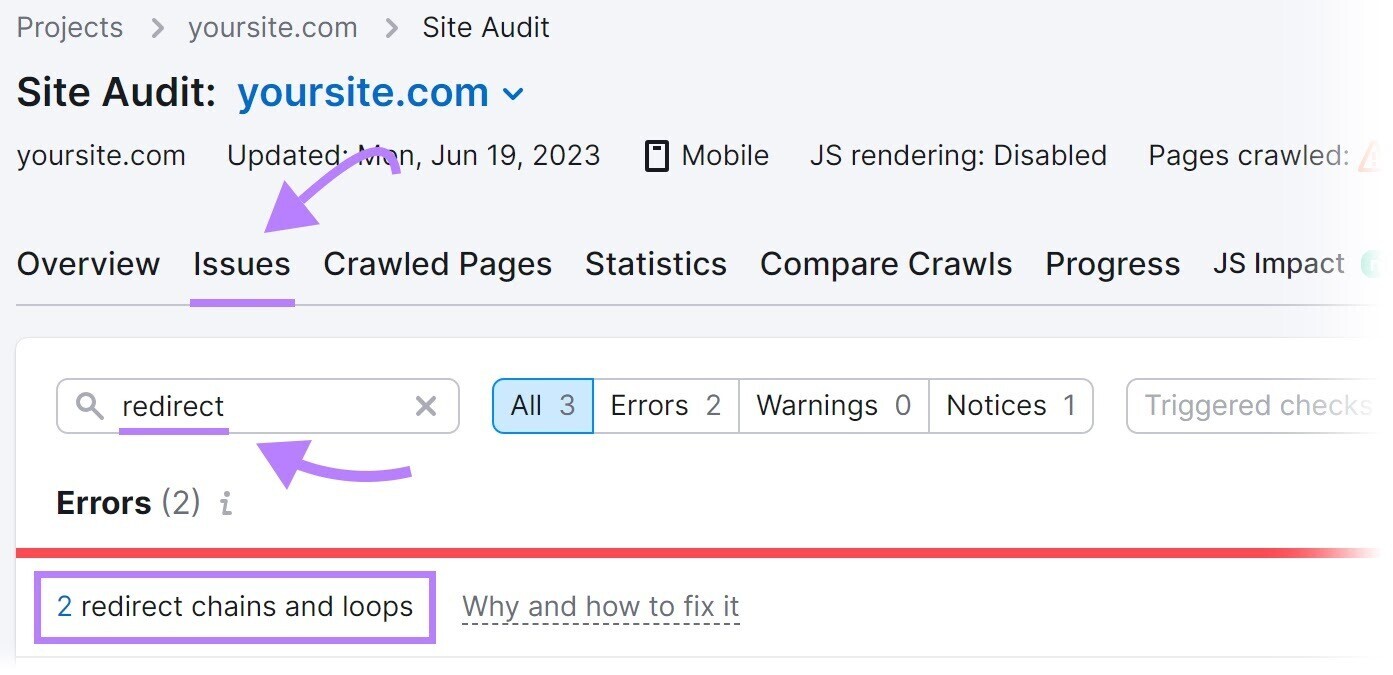
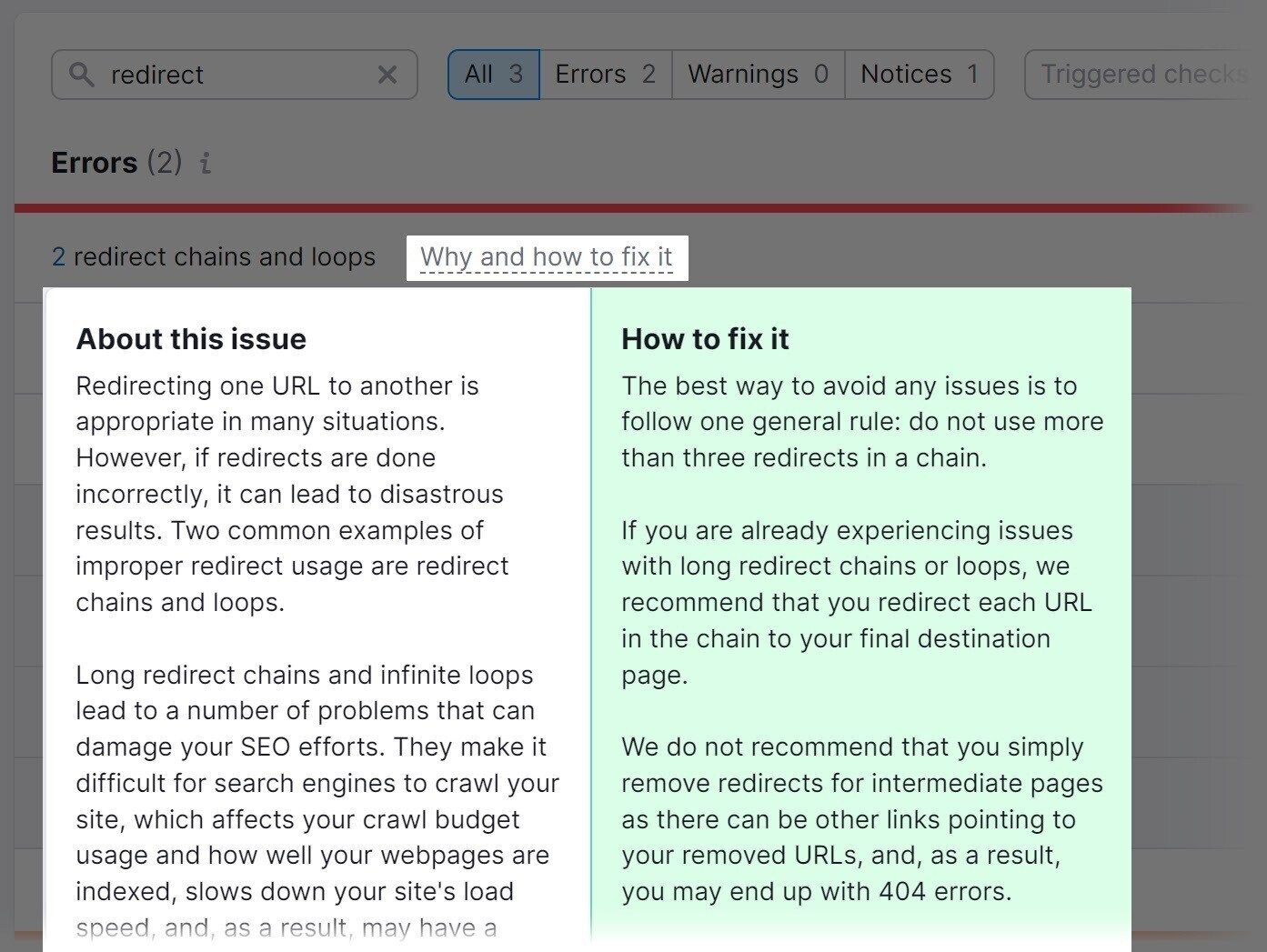
The instrumentality volition show redirect loops. And connection proposal connected however to code them erstwhile you click “Why and however to hole it.”
11. Access Restrictions
Pages with entree restrictions (like those down login forms oregon paywalls) tin forestall hunt motor bots from crawling them.
As a result, those pages whitethorn not look successful hunt results, limiting their visibility to users.
It makes consciousness to person definite pages restricted.
For example, membership-based websites oregon subscription platforms often person restricted pages that are accessible lone to paying members oregon registered users.
This allows the tract to supply exclusive content, peculiar offers, oregon personalized experiences. To make a consciousness of worth and incentivize users to subscribe oregon go members.
But if important portions of your website are restricted, that’s a crawlability mistake.
So, measure the request for restricted entree for each leafage and support them connected pages that genuinely necessitate them. Remove restrictions connected those that don’t.
12. URL Parameters
URL parameters (also known arsenic query strings) are parts of a URL that assistance with tracking and enactment and travel a question people (?). Like example.com/shoes?color=blue
And they tin importantly interaction your website’s crawlability.
How?
URL parameters tin make an astir infinite fig of URL variations.
You’ve astir apt seen that connected ecommerce class pages. When you use filters (size, color, brand, etc.), the URL often changes to bespeak these selections.
And if your website has a ample catalog, abruptly you person thousands oregon adjacent millions of URLs crossed your site.
If they aren’t managed well, Google volition discarded the crawl fund connected the parameterized URLs. Which whitethorn effect successful immoderate of your different important pages not being crawled.
So, you request to determine which URL parameters are adjuvant for hunt and should beryllium crawled. Which you tin bash by knowing whether radical are searching for the circumstantial contented the leafage generates erstwhile a parameter is applied.
For example, radical often similar to hunt by the colour they’re looking for erstwhile buying online.
For example, “black shoes.”
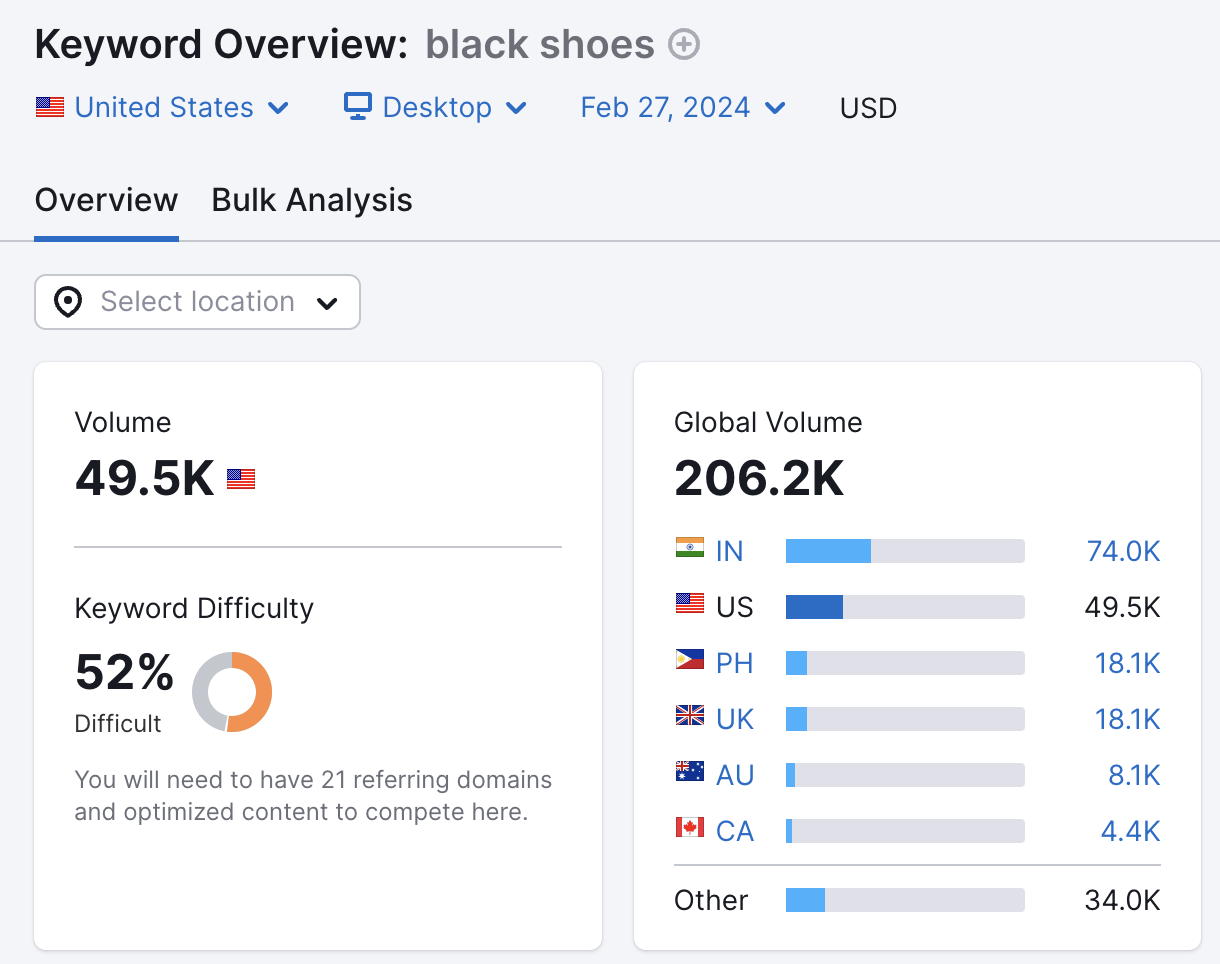
This means the “color” parameter is helpful. And a URL similar example.com/shoes?color=black should beryllium crawled.
But immoderate parameters aren’t adjuvant for hunt and shouldn’t beryllium crawled.
For example, the “rating” parameter that filters the products by their lawsuit ratings. Such arsenic example.com/shoes?rating=5.
Almost cipher searches for shoes by the lawsuit rating.
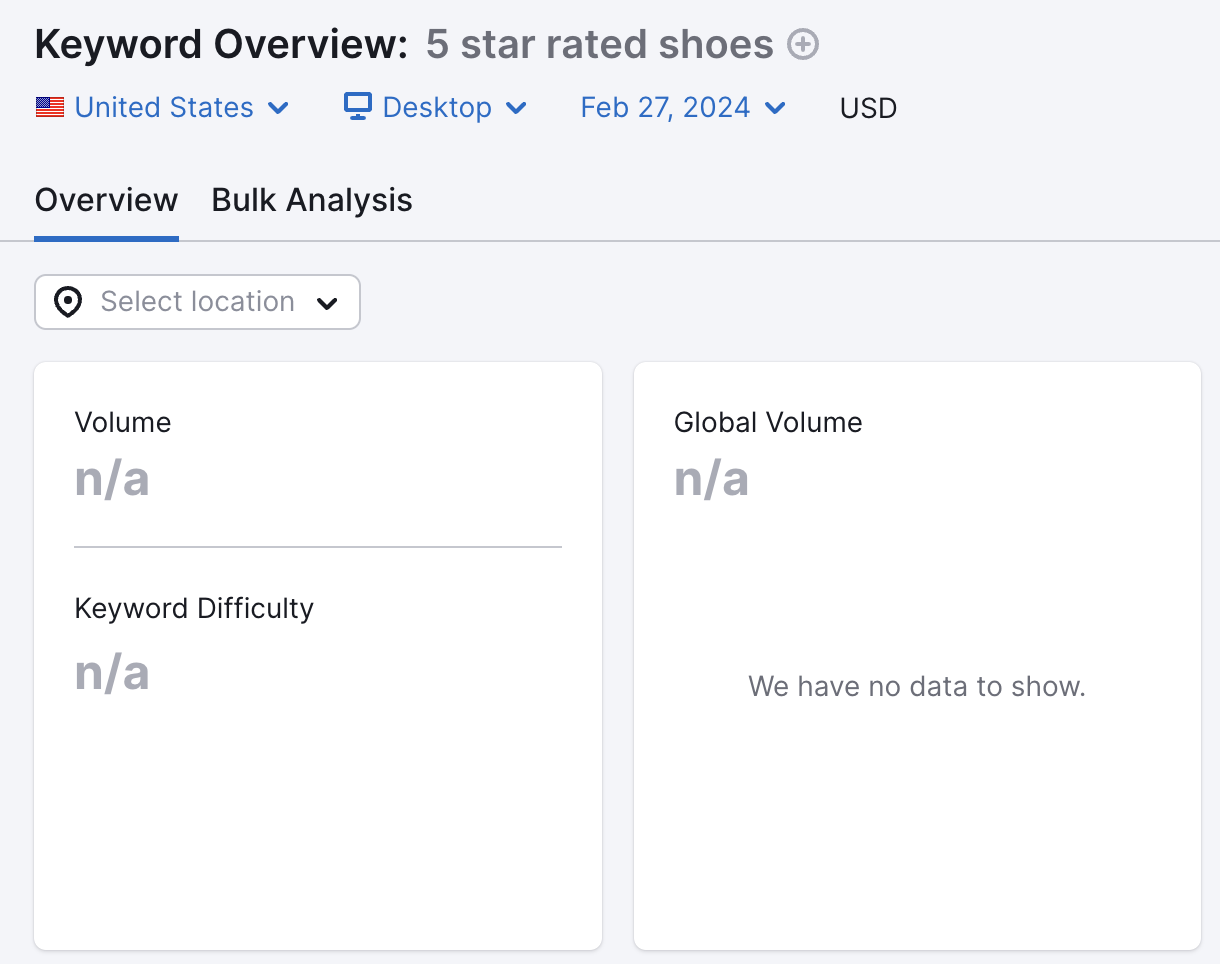
That means you should forestall URLs that aren’t adjuvant for hunt from being crawled. Either by utilizing a robots.txt record oregon utilizing the nofollow tag for interior links to those parameterized URLs.
Doing truthful volition guarantee your crawl fund is being spent efficiently. And connected the close pages.
13. JavaScript Resources Blocked successful Robots.txt
Many modern websites are built utilizing JavaScript (a fashionable programming language). And that codification is contained successful .js files.
But blocking entree to these .js files via robots.txt tin inadvertently make crawlability issues. Especially if you artifact indispensable JavaScript files.
For example, if you artifact a JavaScript record that loads the main contented of a page, the crawlers whitethorn not beryllium capable to spot that content.
So, reappraisal your robots.txt record to guarantee that you’re not blocking thing important.
Or usage Semrush’s Site Audit tool.
Go to the “Issues” tab and hunt for “blocked.”
If issues are detected, click connected the bluish links.
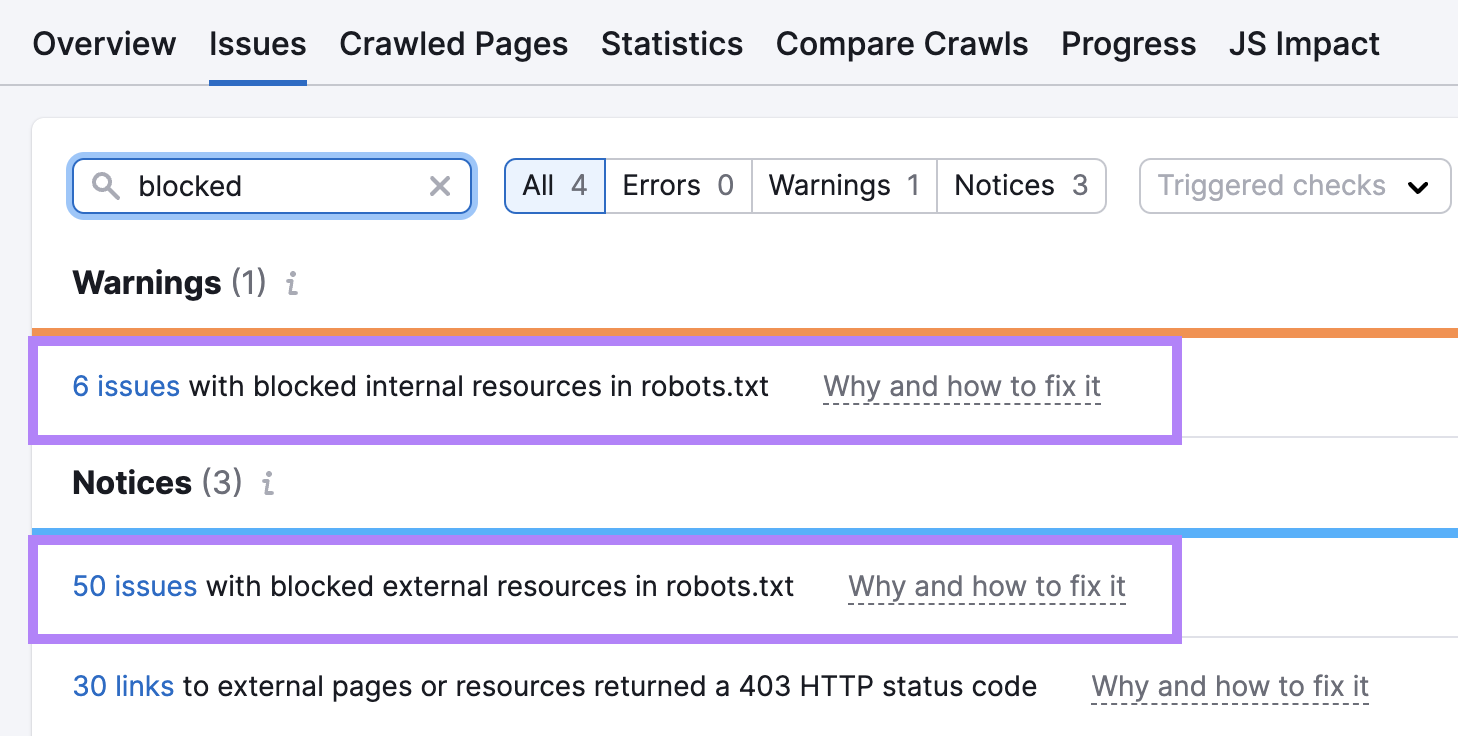
And you’ll spot the nonstop resources that are blocked.
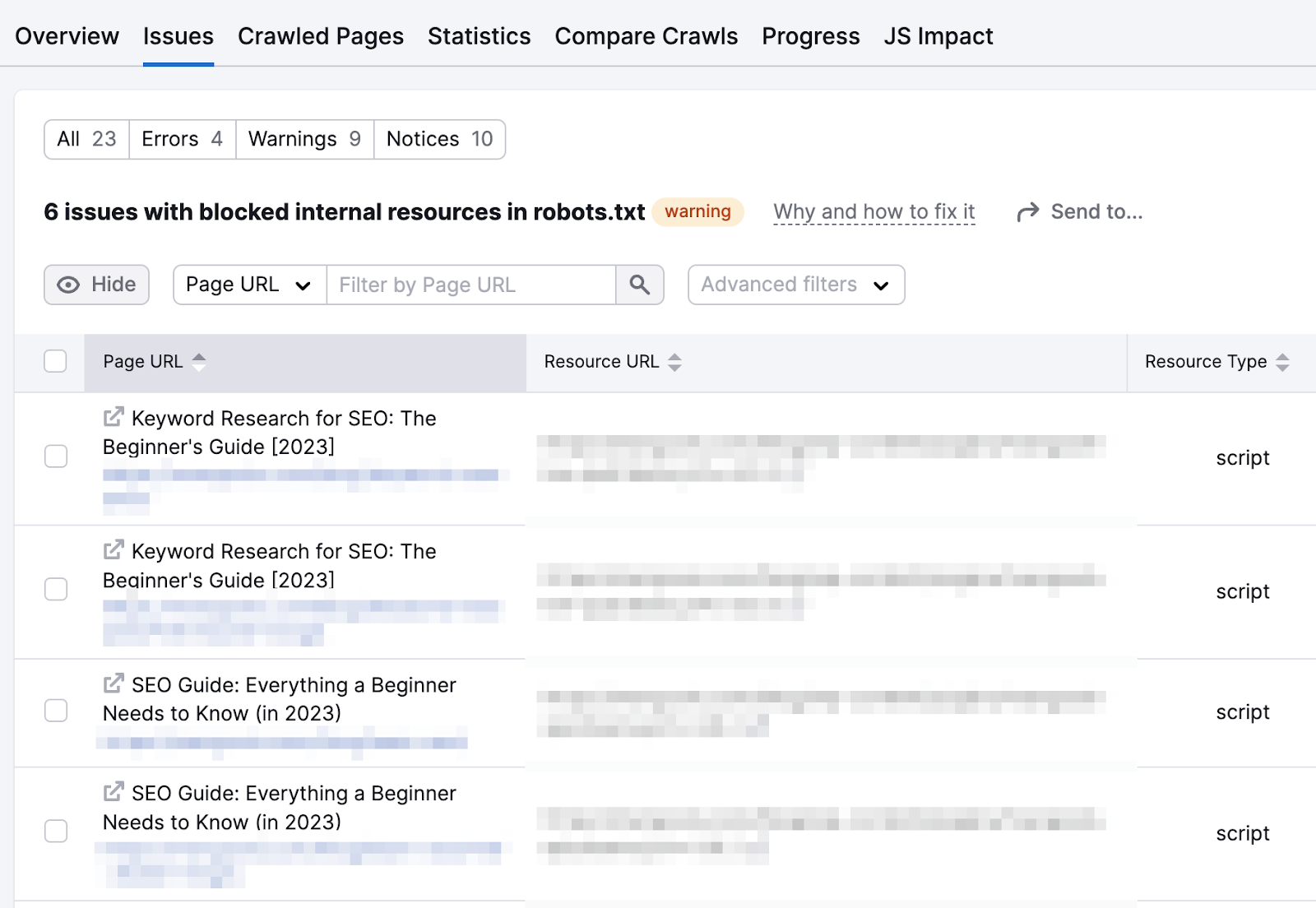
At this point, it’s champion to get assistance from your developer.
They tin archer you which JavaScript files are captious for your website's functionality and contented visibility. And shouldn’t beryllium blocked.
14. Duplicate Content
Duplicate contented refers to identical oregon astir identical contented that appears connected aggregate pages crossed your website.
For example, ideate you people a blog station connected your site. And that station is accessible via aggregate URLs:
- example.com/blog/your-post
- example.com/news/your-post
- example/articles/your-post
Even though the contented is the same, the URLs are different. And hunt engines volition purpose to crawl each of them.
This wastes crawl fund that could beryllium amended spent connected different important pages connected your website. Use Semrush’s Site Audit to place and destruct these problems.
Go to the “Issues” tab and hunt for “duplicate content.” And you’ll spot whether determination are immoderate errors detected.
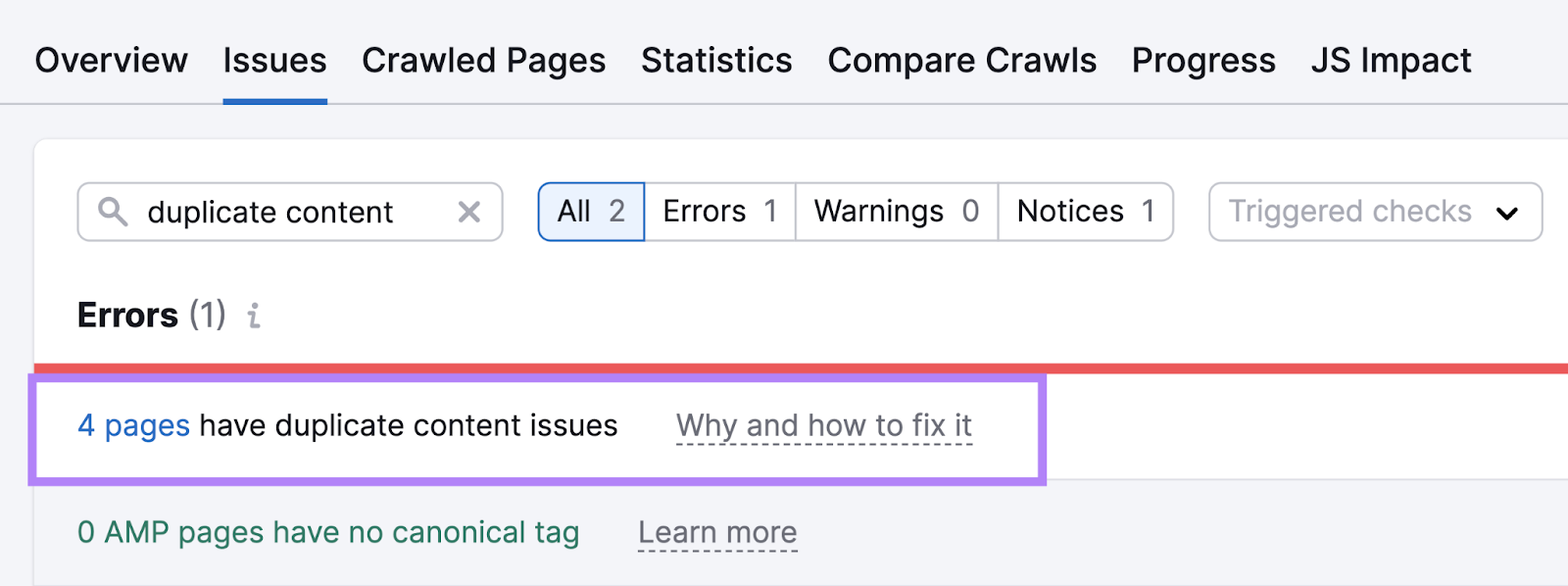
Click the “# pages person duplicate contented issues” nexus to spot a database of each the affected pages.
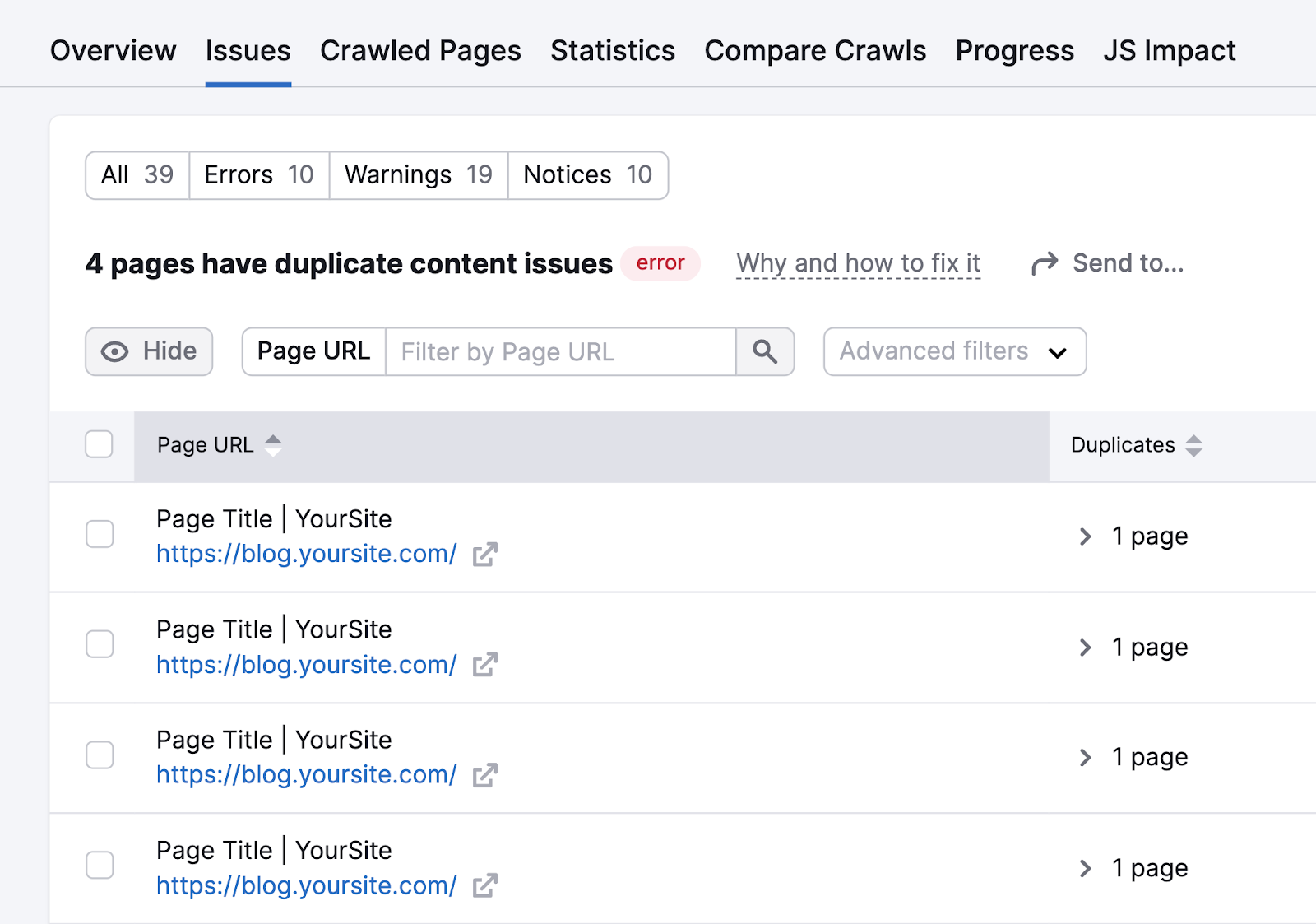
If the duplicates are mistakes, redirect those pages to the main URL that you privation to keep.
If the duplicates are indispensable (like if you’ve intentionally placed the aforesaid contented successful aggregate sections to code antithetic audiences), you tin instrumentality canonical tags. Which assistance hunt engines place the main leafage you privation to beryllium indexed.
15. Poor Mobile Experience
Google uses mobile-first indexing. This means they look astatine the mobile mentation of your tract implicit the desktop mentation erstwhile crawling and indexing your site.
If your tract takes a agelong clip to load connected mobile devices, it tin impact your crawlability. And Google whitethorn request to allocate much clip and resources to crawl your full site.
Plus, if your tract isn’t responsive—meaning it doesn’t accommodate to antithetic surface sizes oregon enactment arsenic intended connected mobile devices—Google whitethorn find it harder to recognize your contented and entree different pages.
So, reappraisal your tract to spot however it works connected mobile. And find slow-loading pages connected your tract with Semrush’s Site Audit tool.
Navigate to the “Issues” tab and hunt for “speed.”
The instrumentality volition amusement the mistake if you person affected pages. And connection proposal connected however to amended their speed.
Stay Ahead of Crawlability Issues
Crawlability problems aren’t a one-time thing. Even if you lick them now, they mightiness recur successful the future. Especially if you person a ample website that undergoes predominant changes.
That's wherefore regularly monitoring your site's crawlability is truthful important.
With our Site Audit tool, you tin execute automated checks connected your site’s crawlability.
Just navigate to the audit settings for your tract and crook connected play audits.
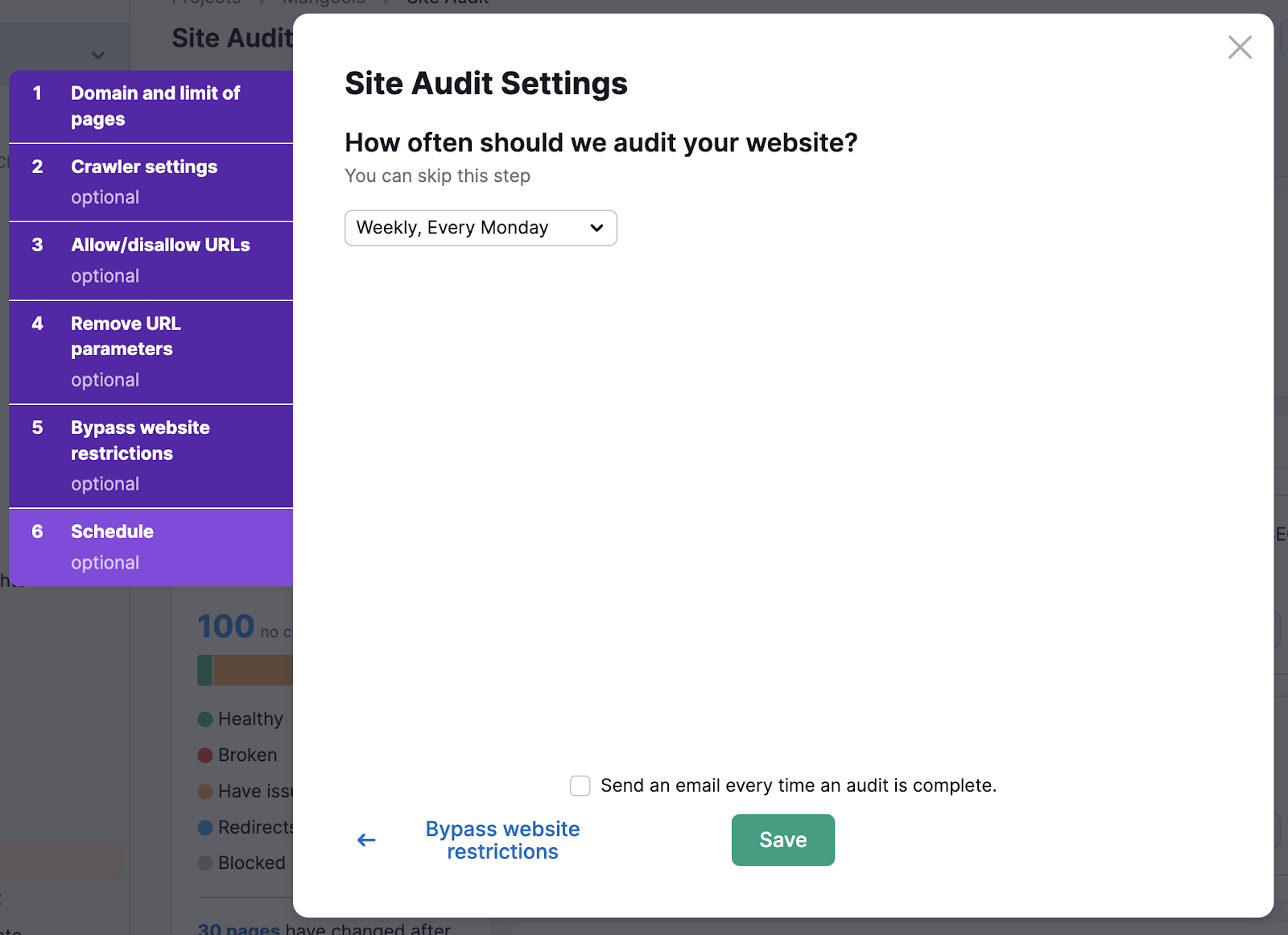
Now, you don’t person to interest astir missing immoderate crawability issues.








 English (US)
English (US)