
ARTICLE AD BOX
Crawling enterprise sites has each the complexities of immoderate mean crawl positive respective further factors that request to beryllium considered earlier opening the crawl.
The pursuing approaches amusement however to execute a large-scale crawl and execute the fixed objectives, whether it’s portion of an ongoing checkup oregon a tract audit.
1. Make The Site Ready For Crawling
An important happening to see earlier crawling is the website itself.
It’s adjuvant to hole issues that whitethorn dilatory down a crawl earlier starting the crawl.
That whitethorn dependable counterintuitive to hole thing earlier fixing it but erstwhile it comes to truly large sites, a tiny occupation multiplied by 5 cardinal becomes a important problem.
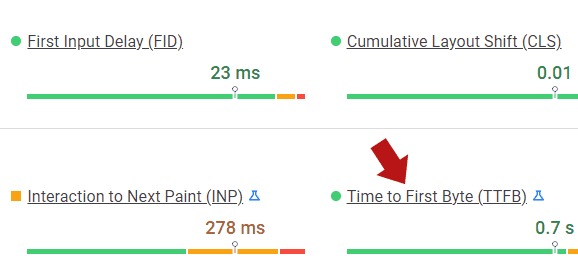
Adam Humphreys, the laminitis of Making 8 Inc. integer selling agency, shared a clever solution helium uses for identifying what is causing a dilatory TTFB (time to archetypal byte), a metric that measures however responsive a web server is.
A byte is simply a portion of data. So the TTFB is the measurement of however agelong it takes for a azygous byte of information to beryllium delivered to the browser.
TTFB measures the magnitude of clip betwixt a server receiving a petition for a record to the clip that the archetypal byte is delivered to the browser, frankincense providing a measurement of however accelerated the server is.
A mode to measurement TTFB is to participate a URL successful Google’s PageSpeed Insights tool, which is powered by Google’s Lighthouse measurement technology.
 Screenshot from PageSpeed Insights Tool, July 2022
Screenshot from PageSpeed Insights Tool, July 2022
Adam shared: “So a batch of times, Core Web Vitals volition emblem a dilatory TTFB for pages that are being audited. To get a genuinely close TTFB speechmaking 1 tin comparison the earthy substance file, conscionable a elemental substance record with nary html, loading up connected the server to the existent website.
Throw immoderate Lorem ipsum oregon thing connected a substance record and upload it past measurement the TTFB. The thought is to spot server effect times successful TTFB and past isolate what resources connected the tract are causing the latency.
More often than not it’s excessive plugins that radical love. I refresh some Lighthouse successful incognito and web.dev/measure to mean retired measurements. When I spot 30–50 plugins oregon tons of JavaScript successful the root code, it’s astir an contiguous occupation earlier adjacent starting immoderate crawling.”
When Adam says he’s refreshing the Lighthouse scores, what helium means is that he’s investigating the URL aggregate times due to the fact that each trial yields a somewhat antithetic people (which is owed to the information that the velocity astatine which information is routed done the Internet is perpetually changing, conscionable similar however the velocity of postulation is perpetually changing).
So what Adam does is cod aggregate TTFB scores and mean them to travel up with a last people that past tells him however responsive a web server is.
If the server is not responsive, the PageSpeed Insights instrumentality tin supply an thought of wherefore the server is not responsive and what needs to beryllium fixed.
2. Ensure Full Access To Server: Whitelist Crawler IP
Firewalls and CDNs (Content Delivery Networks) tin artifact oregon dilatory down an IP from crawling a website.
So it’s important to place each information plugins, server-level intrusion prevention software, and CDNs that whitethorn impede a tract crawl.
Typical WordPress plugins to adhd an IP to the whitelist are Sucuri Web Application Firewall (WAF) and Wordfence.
3. Crawl During Off-Peak Hours
Crawling a tract should ideally beryllium unintrusive.
Under the best-case scenario, a server should beryllium capable to grip being aggressively crawled portion besides serving web pages to existent tract visitors.
But connected the different hand, it could beryllium utile to trial however good the server responds nether load.
This is wherever real-time analytics oregon server log entree volition beryllium utile due to the fact that you tin instantly spot however the server crawl whitethorn beryllium affecting tract visitors, though the gait of crawling and 503 server responses are besides a hint that the server is nether strain.
If it’s so the lawsuit that the server is straining to support up past marque enactment of that effect and crawl the tract during off-peak hours.
A CDN should successful immoderate lawsuit mitigate the effects of an assertive crawl.
4. Are There Server Errors?
The Google Search Console Crawl Stats report should beryllium the archetypal spot to probe if the server is having occupation serving pages to Googlebot.
Any issues successful the Crawl Stats study should person the origin identified and fixed earlier crawling an enterprise-level website.
Server mistake logs are a golden excavation of information that tin uncover a wide scope of errors that whitethorn impact however good a tract is crawled. Of peculiar value is being capable to debug different invisible PHP errors.
5. Server Memory
Perhaps thing that’s not routinely considered for SEO is the magnitude of RAM (random entree memory) that a server has.
RAM is similar short-term memory, a spot wherever a server stores accusation that it’s utilizing successful bid to service web pages to tract visitors.
A server with insufficient RAM volition go slow.
So if a server becomes dilatory during a crawl oregon doesn’t look to beryllium capable to header with a crawling past this could beryllium an SEO occupation that affects however good Google is capable to crawl and scale web pages.
Take a look astatine however overmuch RAM the server has.
A VPS (virtual backstage server) whitethorn request a minimum of 1GB of RAM.
However, 2GB to 4GB of RAM whitethorn beryllium recommended if the website is an online store with precocious traffic.
More RAM is mostly better.
If the server has a capable magnitude of RAM but the server slows down past the occupation mightiness beryllium thing else, similar the bundle (or a plugin) that’s inefficient and causing excessive representation requirements.
6. Periodically Verify The Crawl Data
Keep an oculus retired for crawl anomalies arsenic the website is crawled.
Sometimes the crawler whitethorn study that the server was incapable to respond to a petition for a web page, generating thing similar a 503 Service Unavailable server effect message.
So it’s utile to intermission the crawl and cheque retired what’s going connected that mightiness request fixing successful bid to proceed with a crawl that provides much utile information.
Sometimes it’s not getting to the extremity of the crawl that’s the goal.
The crawl itself is an important information point, truthful don’t consciousness frustrated that the crawl needs to beryllium paused successful bid to hole thing due to the fact that the find is simply a bully thing.
7. Configure Your Crawler For Scale
Out of the box, a crawler similar Screaming Frog whitethorn beryllium acceptable up for velocity which is astir apt large for the bulk of users. But it’ll request to beryllium adjusted successful bid for it to crawl a ample website with millions of pages.
Screaming Frog uses RAM for its crawl which is large for a mean tract but becomes little large for an enterprise-sized website.
Overcoming this shortcoming is casual by adjusting the Storage Setting successful Screaming Frog.
This is the paper way for adjusting the retention settings:
Configuration > System > Storage > Database StorageIf possible, it’s highly recommended (but not perfectly required) to usage an interior SSD (solid-state drive) hard drive.
Most computers usage a modular hard thrust with moving parts inside.
An SSD is the astir precocious signifier of hard thrust that tin transportation information astatine speeds from 10 to 100 times faster than a regular hard drive.
Using a machine with SSD results volition assistance successful achieving an amazingly accelerated crawl which volition beryllium indispensable for efficiently downloading millions of web pages.
To guarantee an optimal crawl it’s indispensable to allocate 4 GB of RAM and nary much than 4 GB for a crawl of up to 2 cardinal URLs.
For crawls of up to 5 cardinal URLs, it is recommended that 8 GB of RAM are allocated.
Adam Humphreys shared: “Crawling sites is incredibly assets intensive and requires a batch of memory. A dedicated desktop oregon renting a server is simply a overmuch faster method than a laptop.
I erstwhile spent astir 2 weeks waiting for a crawl to complete. I learned from that and got partners to physique distant bundle truthful I tin execute audits anyplace astatine immoderate time.”
8. Connect To A Fast Internet
If you are crawling from your bureau past it’s paramount to usage the fastest Internet transportation possible.
Using the fastest disposable Internet tin mean the quality betwixt a crawl that takes hours to implicit to a crawl that takes days.
In general, the fastest disposable Internet is implicit an ethernet transportation and not implicit a Wi-Fi connection.
If your Internet entree is implicit Wi-Fi, it’s inactive imaginable to get an ethernet transportation by moving a laptop oregon desktop person to the Wi-Fi router, which contains ethernet connections successful the rear.
This seems similar 1 of those “it goes without saying” pieces of proposal but it’s casual to place due to the fact that astir radical usage Wi-Fi by default, without truly reasoning astir however overmuch faster it would beryllium to link the machine consecutive to the router with an ethernet cord.
9. Cloud Crawling
Another option, peculiarly for extraordinarily ample and analyzable tract crawls of implicit 5 cardinal web pages, crawling from a server tin beryllium the champion option.
All mean constraints from a desktop crawl are disconnected erstwhile utilizing a unreality server.
Ash Nallawalla, an Enterprise SEO specializer and author, has implicit 20 years of acquisition moving with immoderate of the world’s biggest endeavor exertion firms.
So I asked him astir crawling millions of pages.
He responded that helium recommends crawling from the unreality for sites with implicit 5 cardinal URLs.
Ash shared: “Crawling immense websites is champion done successful the cloud. I bash up to 5 cardinal URIs with Screaming Frog connected my laptop successful database retention mode, but our sites person acold much pages, truthful we tally virtual machines successful the unreality to crawl them.
Our contented is fashionable with scrapers for competitory information quality reasons, much truthful than copying the articles for their textual content.
We usage firewall exertion to halt anyone from collecting excessively galore pages astatine precocious speed. It is bully capable to observe scrapers acting successful alleged “human emulation mode.” Therefore, we tin lone crawl from whitelisted IP addresses and a further furniture of authentication.”
Adam Humphreys agreed with the proposal to crawl from the cloud.
He said: “Crawling sites is incredibly assets intensive and requires a batch of memory. A dedicated desktop oregon renting a server is simply a overmuch faster method than a laptop. I erstwhile spent astir 2 weeks waiting for a crawl to complete.
I learned from that and got partners to physique distant bundle truthful I tin execute audits anyplace astatine immoderate clip from the cloud.”
10. Partial Crawls
A method for crawling ample websites is to disagreement the tract into parts and crawl each portion according to series truthful that the effect is simply a sectional presumption of the website.
Another mode to bash a partial crawl is to disagreement the tract into parts and crawl connected a continual ground truthful that the snapshot of each conception is not lone kept up to day but immoderate changes made to the tract tin beryllium instantly viewed.
So alternatively than doing a rolling update crawl of the full site, bash a partial crawl of the full tract based connected time.
This is an attack that Ash powerfully recommends.
Ash explained: “I person a crawl going connected each the time. I americium moving 1 close present connected 1 merchandise brand. It is configured to halt crawling astatine the default bounds of 5 cardinal URLs.”
When I asked him the crushed for a continual crawl helium said it was due to the fact that of issues beyond his power which tin hap with businesses of this size wherever galore stakeholders are involved.
Ash said: “For my situation, I person an ongoing crawl to code known issues successful a circumstantial area.”
11. Overall Snapshot: Limited Crawls
A mode to get a high-level presumption of what a website looks similar is to bounds the crawl to conscionable a illustration of the site.
This is besides utile for competitory quality crawls.
For example, connected a Your Money Or Your Life task I worked connected I crawled astir 50,000 pages from a competitor’s website to spot what kinds of sites they were linking retired to.
I utilized that information to person the lawsuit that their outbound linking patterns were mediocre and showed them the high-quality sites their top-ranked competitors were linking to.
So sometimes, a constricted crawl tin output capable of a definite benignant of information to get an wide thought of the wellness of the wide site.
12. Crawl For Site Structure Overview
Sometimes 1 lone needs to recognize the tract structure.
In bid to bash this faster 1 tin acceptable the crawler to not crawl outer links and interior images.
There are different crawler settings that tin beryllium un-ticked successful bid to nutrient a faster crawl truthful that the lone happening the crawler is focusing connected is downloading the URL and the nexus structure.
13. How To Handle Duplicate Pages And Canonicals
Unless there’s a crushed for indexing duplicate pages, it tin beryllium utile to acceptable the crawler to disregard URL parameters and different URLs that are duplicates of a canonical URL.
It’s imaginable to acceptable a crawler to lone crawl canonical pages. But if idiosyncratic acceptable paginated pages to canonicalize to the archetypal leafage successful the series past you’ll ne'er observe this error.
For a akin reason, astatine slightest connected the archetypal crawl, 1 mightiness privation to disobey noindex tags successful bid to place instances of the noindex directive connected pages that should beryllium indexed.
14. See What Google Sees
As you’ve nary uncertainty noticed, determination are galore antithetic ways to crawl a website consisting of millions of web pages.
A crawl budget is however overmuch resources Google devotes to crawling a website for indexing.
The much webpages are successfully indexed the much pages person the accidental to rank.
Small sites don’t truly person to interest astir Google’s crawl budget.
But maximizing Google’s crawl fund is simply a precedence for endeavor websites.
In the erstwhile script illustrated above, I advised against respecting noindex tags.
Well for this benignant of crawl you volition really privation to obey noindex directives due to the fact that the extremity for this benignant of crawl is to get a snapshot of the website that tells you however Google sees the full website itself.
Google Search Console provides tons of accusation but crawling a website yourself with a idiosyncratic cause disguised arsenic Google whitethorn output utile accusation that tin assistance amended getting much of the close pages indexed portion discovering which pages Google mightiness beryllium wasting the crawl fund on.
For that benignant of crawl, it’s important to acceptable the crawler idiosyncratic cause to Googlebot, acceptable the crawler to obey robots.txt, and acceptable the crawler to obey the noindex directive.
That way, if the tract is acceptable to not amusement definite leafage elements to Googlebot you’ll beryllium capable to spot a representation of the tract arsenic Google sees it.
This is simply a large mode to diagnose imaginable issues specified arsenic discovering pages that should beryllium crawled but are getting missed.
For different sites, Google mightiness beryllium uncovering its mode to pages that are utile to users but mightiness beryllium perceived arsenic debased prime by Google, similar pages with sign-up forms.
Crawling with the Google idiosyncratic cause is utile to recognize however Google sees the tract and assistance to maximize the crawl budget.
Beating The Learning Curve
One tin crawl endeavor websites and larn however to crawl them the hard way. These fourteen tips should hopefully shave immoderate clip disconnected the learning curve and marque you much prepared to instrumentality connected those enterprise-level clients with gigantic websites.
More resources:
- 3 Ways Spammers Hide Links & Text connected Webpages & How To Stop Them
- 7 SEO Crawling Tool Warnings & Errors You Can Safely Ignore
- Advanced Technical SEO: A Complete Guide
Featured Image: SvetaZi/Shutterstock








 English (US)
English (US)