
ARTICLE AD BOX
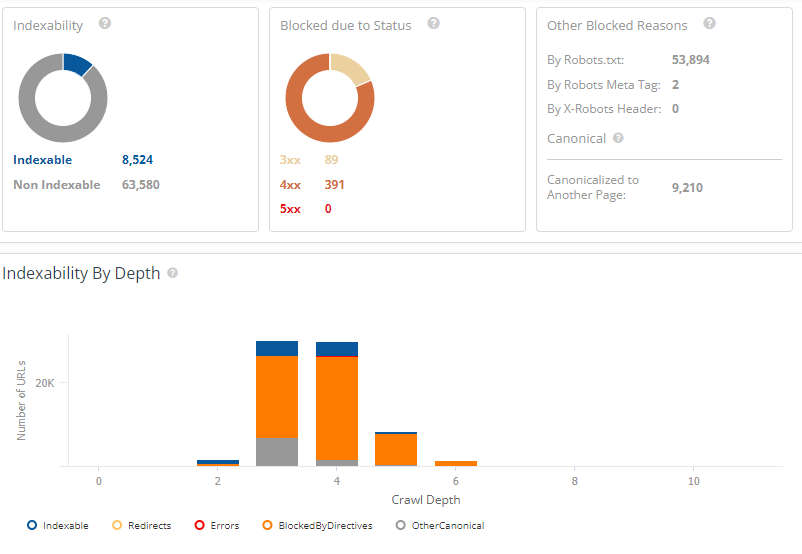
Robots.txt files assistance bounds hunt motor crawler (like Googlebot) from seeing unimportant pages connected your site. At seoClarity, we urge Google’s guidelines and champion practices: configuring your tract to power however non-HTML contented is shown successful hunt motor results (or to marque definite it is not shown) globally with X-Robots-Tag HTTP headers. By blocking files via HTTP headers, you guarantee that your tract doesn't commencement to spot accrued indexation of URLs you don't privation to look successful hunt results. This helps to debar imaginable information issues and immoderate imaginable conflicts that tin effect from pages being indexed that don't request to be. Robots.txt tin besides beryllium an effectual means, but determination are immoderate imaginable issues to beryllium alert of. Here's what we'll screen successful this post: The Importance of Reviewing the Implementation of Robots.txt Files > Robots.txt files pass hunt motor crawlers which pages oregon files the crawler tin oregon can’t petition from your site. They besides artifact idiosyncratic agents similar bots, spiders, and different crawlers from accessing your site’s pages. Below is an illustration of what a robots.txt record looks like. A hunt motor bot similar Googlebot volition work the robots.txt record anterior to crawling your tract to larn what pages it should woody with. This tin beryllium adjuvant if you privation to support a information of your tract retired of a hunt motor scale oregon if you privation definite contented to beryllium indexed successful Google but not Bing. Below is an example from Google successful which Googlebot has blocked entree to definite directories portion allowing entree to /directory2/subdirectory1/. You'll besides spot that “anothercrawler” is blocked from the full site. User-agents are listed successful “groups." Each radical tin beryllium designated wrong its ain lines by crawler benignant indicating which files it tin and cannot access. Collecting bot enactment information is particularly important for identifying immoderate further bots, spiders, oregon crawlers that should beryllium blocked from accessing your site’s content. Telling a crawler which pages to crawl and which pages to skip gives you greater power implicit your site’s crawl budget, allowing you to nonstop crawlers to your astir important assets. It's besides important to enactment that erstwhile idiosyncratic agents similar bots, spiders, and different crawlers deed your site, they tin utilize extended resources (memory and CPU) and tin pb to precocious load connected the server that slows down your site. By having a robots.txt record successful place, you debar the anticipation of overloading your site’s servers with requests. This is mostly due to the fact that you tin negociate the summation of postulation by crawlers and debar crawling unimportant oregon akin pages connected your site. Assets oregon files that Google doesn’t request to discarded crawl resources connected tin include: In the illustration robots.txt record below, determination are coding assets stored successful the /cgi-bin folder connected the website. So adding a disallow enactment allows crawlers to enactment determination are nary assets wrong this folder the tract would privation indexed. One caveat is that, according to Google, pages that are blocked via robots.txt record whitethorn inactive look successful hunt results, but the hunt effect volition not person a statement and look something similar this representation here. If you spot this hunt effect for your leafage and privation to hole it, region the enactment wrong the robots.txt introduction blocking the page. Pages that inactive person backlinks pointing to the leafage from different places connected the web whitethorn perchance inactive look successful hunt results. To decently forestall your URL from appearing successful Google Search results, you should password support the files connected your server oregon usage the noindex meta tag oregon effect header (or region the leafage wholly via 410 oregon different means). You tin besides designate wrong the robots.txt record which assets you privation to forestall from appearing successful hunt results including circumstantial images, video, and audio files, arsenic good arsenic artifact unimportant image, script, oregon benignant files (if you deliberation that pages loaded without these resources volition not beryllium importantly affected by the loss). Recommended Reading: Technical SEO: Best Practices to Prioritize Your SEO Tasks Because robots.txt files bespeak to crawlers which pages and resources not to crawl (and truthful those that won't beryllium indexed) they should beryllium reviewed to guarantee the implementation is correct. If pages oregon a conception of your tract are disallowed from crawling done the robots.txt file, past immoderate accusation astir indexing oregon serving directives volition not beryllium recovered and volition truthful beryllium ignored. For example, Googlebot volition not see: Important resources needed to render leafage contented (including assets needed to load to summation leafage speed, for example) request to beryllium crawled. If indexing oregon serving directives indispensable beryllium followed, the URLs containing those directives cannot beryllium disallowed from crawling. Generally, you shouldn’t artifact thing that prevents Google from rendering the pages the aforesaid mode a idiosyncratic would spot the leafage (i.e. images, JS, CSS). The champion mode to find robots.txt errors is with a tract audit. This lets you uncover technical SEO issues astatine standard truthful you tin resoluteness them. Here are communal issues with robots.txt specifically: A website without a robots.txt file, robots meta tags, oregon X-Robots-Tag HTTP headers volition mostly beryllium crawled and indexed normally. Having a robots.txt record is simply a recommended champion signifier for sites to adhd a level of power to the contented and files that Google tin crawl and index. Not having 1 simply means that Google volition crawl and scale each content. Adding a disallow enactment successful your robots.txt record volition besides contiguous a information hazard arsenic it identifies wherever your interior and backstage contented is stored. Use server-side authentication to artifact entree to backstage content. This is particularly important for idiosyncratic identifiable accusation (PII). Sites request to beryllium crawled successful bid to spot the canonical and astir index. Do not artifact contented via a robots.txt record successful an effort to grip arsenic canonicals. Certain CMS and Dev environments whitethorn marque it hard to adhd customized canonicals. In this instance, Dev whitethorn effort different methods arsenic workarounds. If you privation to region contented from a third-party site, you request to interaction the webmaster to person them region the content. This tin hap successful mistake erstwhile it's hard to construe the root server for circumstantial content. The directives successful the robots.txt record (with the objection of “Sitemap:”) are lone valid for comparative paths. Sites with aggregate sub-directories whitethorn privation to usage implicit URLs, but lone comparative URLs are passed. The record indispensable beryllium placed successful the top-most directory of the website – not a sub-directory. Ensure that you are not placing the robots.txt successful immoderate different folder oregon sub-directories. It is not recommended to service antithetic robots.txt files based connected the user-agent oregon different attributes. Sites should ever instrumentality the aforesaid robots.txt for planetary sites. Site owners often successful improvement sprints accidentally trigger the default robots.txt record which tin past database a disallow enactment that blocks each tract content. This usually occurs arsenic an mistake oregon erstwhile a default is applied crossed the tract that impacts the robots.txt record and resets it to default. Sites bash not request to see an “allow” directive. The “allow” directive is utilized to override “disallow” directives successful the aforesaid robots.txt file. In instances which the “disallow” is precise similar, adding an “allow” tin assistance successful adding aggregate attributes to assistance separate them. Google Search Console Help country has a station that covers how to make robots.txt files. After you’ve created the file, you tin validate it utilizing the robots.txt tester. The record indispensable extremity successful .txt and beryllium created successful UTF-8 format. Blocking Google from crawling a leafage is apt to region the leafage from Google’s index. In the illustration below, a institution thought they were limiting their crawl fund to not beryllium wasted connected filters and facets. But, successful reality, they were preventing the crawling of immoderate large categories. This usually occurs owed to the placement of the asterix (*). When added earlier a folder it tin mean thing in-between. When it’s added after, that’s a motion to artifact thing included successful the URL aft the /. As you tin spot successful this tract crawl, a important magnitude of their tract was being blocked by Robots.txt. You tin temporarily suspend each crawling by returning an HTTP effect codification of 503 for each URLs, including the robots.txt file. The robots.txt record volition beryllium retried periodically until it tin beryllium accessed again. (We bash not urge changing your robots.txt record to disallow crawling.) When relocating a tract oregon making monolithic updates, the robots.txt could beryllium bare default to blocking the full site. Best signifier present is to guarantee that it remains connected tract and is not taken down during maintenance. Keep successful caput that directives successful the robots.txt record are case-sensitive. Some CMS/Dev environments whitethorn automatically acceptable URLs to render the robots.txt successful uppercase and lowercase. The directives MUST lucifer the existent 200-live presumption URL structure. In bid to artifact crawling of the website, the robots.txt indispensable beryllium returned usually (i.e. with a 200 “OK” HTTP effect code) with an due “disallow” successful it. When relocating a tract oregon making monolithic updates, the robots.txt could beryllium bare oregon removed. Best signifier is to guarantee that it remains connected tract and is not taken down during maintenance. A speedy and casual mode to cheque the server headers is to usage a web-based server header checker, oregon usage the “Fetch arsenic Googlebot” diagnostic successful Search Console. Now that you cognize astir immoderate of the astir communal Robots.txt issues, let's spell implicit Google's champion practices for utilizing these files. Robots.txt tin beryllium utilized to artifact web crawlers from accessing circumstantial web pages connected your site, but beryllium definite to travel the seoClarity proposal below. If determination are circumstantial pages you privation to artifact from crawling oregon indexing, we urge adding a “no index” directive connected the leafage level. We urge adding this directive globally with X-Robots-Tag HTTP headers arsenic the perfect solution, and if you request circumstantial pages past adhd the “noindex” connected the leafage level. Google offers a variety of methods connected however to bash this. Use robots.txt to negociate crawl traffic, and besides forestall image, video, and audio files from appearing successful the SERP. Do enactment that this won’t forestall different pages oregon users from linking to your image, video, oregon audio file. If different pages oregon sites nexus to this content, it whitethorn inactive look successful hunt results. If the extremity end is to person those media types not look successful the SERP, past you tin adhd it via the robots.txt file. You tin usage robots.txt to artifact assets files, specified arsenic unimportant image, script, oregon benignant files if you deliberation that pages loaded without these resources volition not beryllium importantly affected by the loss. However, if the lack of these resources marque the leafage harder for Googlebot to recognize the page, you should not artifact them, oregon other Google volition not beryllium capable to analyse the pages that beryllium connected those resources. We urge this method if nary different method works best. If you are blocking important resources (e.g. CSS publication that renders the substance connected the page) this could origin Google to not render that substance arsenic content. Similarly, if third-party resources are needed to render the leafage and are blocked, this could beryllium to beryllium problematic. Google does not urge adding lines to your robots.txt record with the “noindex” directive. This enactment volition beryllium ignored wrong the robots.txt file. If you inactive person the “noindex” directive wrong your robots.txt files, we urge 1 of the pursuing solutions: The supra illustration instructs hunt engines not to amusement the leafage successful hunt results. The worth of the sanction property (robots) specifies that the directive applies to each crawlers. To code a circumstantial crawler, regenerate the “robots” worth of the sanction property with the sanction of the crawler that you are addressing. This is recommended for circumstantial pages. The meta tag must look successful the <head> section. If determination are circumstantial pages that you privation to artifact from crawling oregon indexing, we urge adding a “no index” directive connected the page. Google offers circumstantial methods to bash this. The X-Robots-Tag tin beryllium utilized arsenic an constituent of the HTTP header effect for a fixed URL. Any directive that tin beryllium utilized successful a robots meta tag tin besides beryllium specified arsenic an X-Robots-Tag. Here is an illustration of an HTTP effect with a X-Robots-Tag instructing crawlers not to scale a page: HTTP/1.1 200 OK In addition, determination whitethorn beryllium instances successful which you request to usage aggregate directives. In these instances, directives whitethorn beryllium combined successful a comma-separated list. We urge this arsenic the preferred method for immoderate contented you privation to beryllium blocked from hunt engines. Global Directives connected the folder level are needed. The payment of utilizing an X-Robots-Tag with HTTP responses is that you tin specify crawling directives that are applied globally crossed a site. This is handled connected your server. To instrumentality it, you request to scope retired to your Dev Team liable for handling your site’s interior servers. You should reappraisal our optimal implementation steps to guarantee that your tract follows each champion practices for robots.txt files and comparison your tract with the communal errors that we’ve listed above. Then, make a process to grip and region noindex lines from robots.txt. Conduct a full tract crawl to place immoderate further pages that should beryllium added arsenic disallow lines. Make definite your tract is not utilizing automatic redirection oregon varying the robots.txt. Benchmark your site’s show anterior to and aft changes. Our Client Success Managers tin assistance you successful creating those reports to benchmark. If you request further assistance, our Professional Services squad is disposable to assistance diagnose immoderate errors, supply you with an implementation checklist and further recommendations, oregon assistance with QA testing. <<Editor's Note: This portion was primitively published successful April 2020 and has since been updated.>>
What is simply a Robots.txt File?
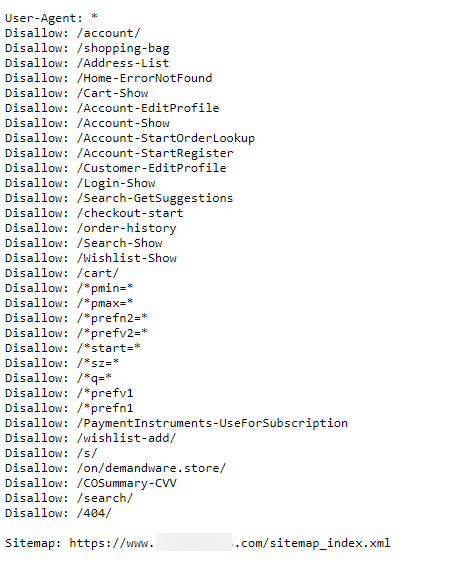
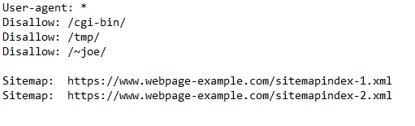 (A robots.txt with the specified idiosyncratic agent, disallow, and sitemap criteria.)
(A robots.txt with the specified idiosyncratic agent, disallow, and sitemap criteria.)Example of a Robots.txt File
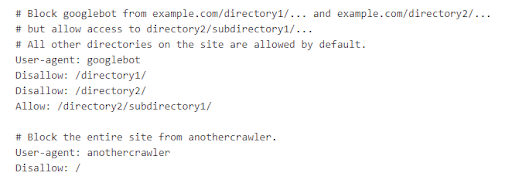
Why are Robots.txt Files Important?
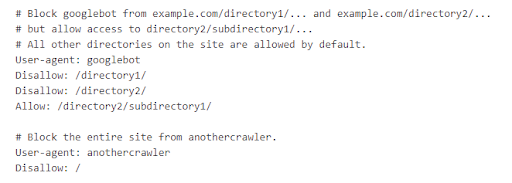
The Importance of Reviewing the Implementation of Robots.txt Files
14 of the Most Common Robots.txt Issues
#1. Missing Robots.txt
How this tin go an issue:
#2. Adding Disallow Lines to Block Private Content
How this tin go an issue:
#3. Adding Disallow to Avoid Duplicate Content/Used As Opposed to Canonicals
How this tin go an issue:
#4. Adding Disallow to Code That is Hosted connected a Third-Party Site
How this tin go an issue:
#5. Use of Absolute URLs
How this tin go an issue:
#6. Robots.txt Not Placed successful Root Folder
How this tin go an issue:
#7. Serving Different Robots.txt Files (Internationally oregon Otherwise)
How this tin go a problem:
#8. Added Directive to Block All Site Content
How this tin go a problem:
#9. Adding ALLOW vs. DISALLOW
How this tin go an issue:
#10. Wrong File Type Extension
How this tin go an issue:
#11. Adding Disallow to a Top-Level Folder Where Pages That You Do Want Indexed Also Appear
How this tin go an issue:
#12. Blocking Entire Site Access During Development
How this tin go an issue:
#13. Using Capitalized Directives vs. Non-Capitalized
How this tin go an issue:
#14. Using Server Status Codes (e.g. 403) to Block Access
How this tin go an issue:
How to Check if Your Site Has X-Robots-Tag Implemented
Google’s Best Practices for Using Robots.txt Files
#1. Block Specific Web Pages
seoClarity Tip
#2. Media Files
seoClarity Tip
#3. Resource Files
seoClarity Tip
How to Handle “Noindex” Attributes
#1. Use the Robots Meta Tag: <meta name=“robots” content=”noindex” />
seoClarity Tip
#2. Contact your Dev squad liable for your server and configure the X-Robots-Tag HTTP Header
Date: Tue, 25 May 2010 21:42:43 GMT
(...)
X-Robots-Tag: noindex
(...)seoClarity Tip
Key Takeaways








 English (US)
English (US)